6-828Lab5
Lab 5: File system, Spawn and Shell
Introduction
In this lab, you will implement spawn, a library call that loads and runs on-disk executables. 然后,您将充实内核和库操作系统,使其足以在控制台上运行shell。这些特性需要一个文件系统,本实验室介绍了一个简单的读写文件系统。
| file | |
|---|---|
fs/fs.c |
操纵文件系统磁盘上结构的代码。 |
fs/bc.c |
一个建立在用户级页面错误处理设施之上的简单块缓存。 |
fs/ide.c |
最小的基于pio(非中断驱动)的IDE驱动程序代码。 |
fs/serv.c |
使用文件系统IPCS与客户机环境交互的文件系统服务器。 |
lib/fd.c |
实现通用类unix文件描述符接口的代码。 |
lib/file.c |
用于磁盘上文件类型的驱动程序,实现为文件系统IPC客户机。 |
lib/console.c |
控制台输入/输出文件类型的驱动程序。 |
lib/spawn.c |
spawn库调用的代码框架。 |
File system preliminaries(文件系统初步)
我们要完成一个相对简单的文件系统,其可以实现创建、读、写以及删除在分层目录结构中组织的文件。目前我们的OS只支持单用户,因此我们的文件系统也不支持UNIX文件拥有或权限的概念。同时也不支持硬链接、符号链接、时间戳或是特别的设备文件。
On-Disk File System Structure
大多数UNIX文件系统将可用磁盘空间划分为两种主要类型的区域:inode区域和数据区域。UNIX文件系统为文件系统中的每个文件分配一个inode;一个文件的inode保存着关于该文件的关键元数据,比如它的属性和指向其数据块的指针。数据区域被划分为更大的数据块(通常为8KB或更多),文件系统在其中存储文件数据和目录元数据。目录项包含文件名和指向索引节点的指针;如果文件系统中的多个目录条目引用了该文件的inode,则该文件被称为硬链接文件。由于我们的文件系统不支持硬链接,我们不需要这种间接级别,因此可以进行方便的简化:我们的文件系统根本不使用inode,而只是将一个文件(或子目录)的所有元数据存储在描述该文件的(唯一的)目录条目中。
文件和目录在逻辑上都由一系列数据块组成,这些数据块可以分散在磁盘中,就像环境的虚拟地址空间的页面可以分散在物理内存中一样。文件系统环境隐藏了块布局的细节,提供了在文件中任意偏移位置读取和写入字节序列的接口。文件系统环境在内部处理对目录的所有修改,作为执行文件创建和删除等操作的一部分。我们的文件系统允许用户环境直接读取目录元数据(例如,使用read),这意味着用户环境可以自己执行目录扫描操作(例如,实现ls程序),而不必依赖于对文件系统的额外特殊调用。这种目录扫描方法的缺点是,它使应用程序依赖于目录元数据的格式,在不更改或至少重新编译应用程序的情况下,很难更改文件系统的内部布局,这也是大多数现代UNIX变体不鼓励使用这种方法的原因。
Sectors and Blocks
扇区是对磁盘的概念,块是对OS的概念。 块的 size 必须是扇区size 的整数倍。
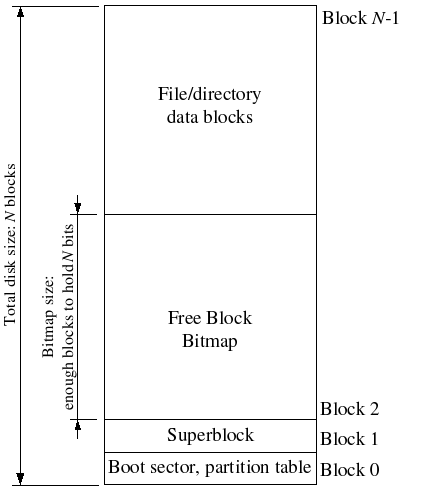
Superblocks
文件系统通常在磁盘上的“易于查找”位置保留某些磁盘块(例如从最开始或最后)以保存描述文件系统属性的元数据,例如块大小 ,磁盘大小,查找根目录所需的任何元数据,上次挂载文件系统的时间,文件系统上次检查错误的时间等等。 这些特殊块称为超级块。
我们的文件系统将只有一个超级块,它始终位于磁盘上的第1块。它的布局由struct Super在inc/fs.h中定义。块0通常保留来保存引导加载程序和分区表,因此文件系统通常不使用第一个磁盘块。许多“真正的”文件系统维护多个超级块,复制到磁盘上几个间隔很宽的区域,因此,如果其中一个超级块损坏或磁盘在该区域出现了媒体错误,仍然可以找到其他超级块,并使用它们访问文件系统。
1 | struct Super { |
Superblock, Inode, Dentry 和 File 都属于元数据(Metadata),根据维基百科中的解释,所谓元数据,就是描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。Linux/Unix 文件系统的元数据以多级结构保存。
superblock:记录此filesystem 的整体信息,包括inode[表情]ock的总量、使用量、剩余量, 以及档案系统的格式与相关信息等;
inode:记录档案的属性,一个档案占用一个inode,同时记录此档案的资料所在的block 号码;
block:实际记录档案的内容,若档案太大时,会占用多个block 。
Superblock 是文件系统最基本的元数据,它定义了文件系统的类似、大小、状态,和其他元数据结构的信息(元数据的元数据)。
File Meta-data
The layout of the meta-data describing a file in our file system is described by struct File in inc/fs.h. Unlike in most “real” file systems, for simplicity we will use this one File structure to represent file meta-data
1 | struct File { |

Directories versus Regular Files(目录与普通文件)
我们的文件系统中的超级块包含一个 File结构,其保存了文件系统根目录的元数据。这个目录文件的内容是一系列文件结构体,其描述了文件系统根目录下的文件和目录。任何根目录下的子目录可能包含更多表示子子目录的文件结构体,以此类推。
The File System
我们实现的文件系统的关键部分是:
读数据到缓存中并能写回到磁盘;
分配磁盘块;
将文件偏移映射到磁盘块;
并在IPC接口中实现读,写和打开。
Disk Access
操作系统中的文件系统环境需要能够访问磁盘,但是我们还没有在内核中实现任何磁盘访问功能。我们没有采用传统的“单片”操作系统策略,即在内核中添加IDE磁盘驱动程序以及允许文件系统访问它的必要系统调用,而是将IDE磁盘驱动程序作为用户级文件系统环境的一部分来实现。我们仍然需要稍微修改内核,以便让文件系统环境拥有实现磁盘访问所需的权限。
只要我们依赖于轮询、基于“编程I/O”(PIO)的磁盘访问,并且不使用磁盘中断,就很容易通过这种方式在用户空间中实现磁盘访问。也可以在用户模式下实现中断驱动的设备驱动程序(例如,L3和L4内核就可以做到这一点),但难度更大,因为内核必须字段设备中断并将它们分派到正确的用户模式环境中。
x86处理器使用EFLAGS寄存器中的IOPL位来确定是否允许保护模式代码执行特殊的设备I/O指令,如in和OUT指令。因为我们需要访问的所有IDE磁盘寄存器都位于x86的I/O空间中,而不是内存映射的,所以给文件系统环境“I/O特权”是我们唯一需要做的事情,以便允许文件系统访问这些寄存器。实际上,EFLAGS寄存器中的IOPL位为内核提供了一种简单的“全或无”方法来控制用户模式代码是否可以访问I/O空间。在我们的示例中,我们希望文件系统环境能够访问I/O空间,但是我们根本不希望任何其他环境能够访问I/O空间。
Exercise 1:
i386_init通过将类型ENV_TYPE_FS传递给环境创建函数env_create来标识文件系统环境。在env.c中修改env_create,使它赋予文件系统环境I/O权限,但不赋予任何其他环境该权限。
1 | void |
Question
Do you have to do anything else to ensure that this I/O privilege setting is saved and restored properly when you subsequently switch from one environment to another? Why?
不需要,因为在环境切换时,会保存eflags的值,后续也会使用env_pop_tf来恢复eflags的值。
The Block Cache
在我们的文件系统中,我们将在处理器的虚拟内存系统的帮助下实现一个简单的“缓冲区缓存”(实际上只是块缓存)。块缓存的代码在fs/bc.c中。
我们的文件系统只能处理3GB或更小的磁盘。我们在文件系统环境的地址空间中保留了一个很大的、固定的3GB区域,从0x10000000 (DISKMAP)到0xD0000000 (DISKMAP+DISKMAX),作为磁盘的“内存映射”版本。例如,磁盘块0映射到虚拟地址0x10000000,磁盘块1映射到虚拟地址0x10001000,依此类推。fs/bc.c中的diskaddr函数实现了从磁盘块号到虚拟地址的转换(以及一些完整性检查)。
将整个磁盘读入内存需要很长时间,因此我们将实现一种请求页面调度,当进程在运行时需要访问某部分程序和数据时,若发现请求页面不在内存,便提出请求,由OS将其所需页面调入内存。这样,我们就可以假装整个磁盘都在内存中。
Exercise 2:
implement the bc_pgfault and flush_block functions in fs/bc.c.
bc_pgfault is a page fault handler, just like the one your wrote in the previous lab for copy-on-write fork, 只不过它的工作是从磁盘加载页面以响应页面错误.
When writing this, keep in mind that
(1) addr may not be aligned to a block boundary and
(2) ide_read operates in sectors, not blocks.
如果需要,flush_block函数应该将一个块写入磁盘。如果块甚至不在块缓存中(也就是说,页面没有映射),或者它不是脏的,则Flush_block不应该做任何事情。我们将使用VM硬件来跟踪磁盘块自上次从磁盘读取或写入磁盘以来是否被修改过。要查看一个块是否需要写入,我们只需查看uvpt条目中是否设置了PTE_D“脏”位。PTE_D位由处理器设置,以响应对该页的写操作;参见386参考手册第五章5.2.4.3。)将块写入磁盘后,flush_block应该使用sys_page_map清除PTE_D位。
采用了wb
块号与扇区号有一定的区别,在完成这两个函数时,要注意区分这两个概念。 JOS 块大小位4kB,扇区大小为512B,每次读写一个块,就需要读写4个扇区。因此,JOS使用了一个宏定义#define BLKSECTS (BLKSIZE / SECTSIZE)来描述两者的关系。
bc_pgfault()
1 | static void |
flush_block()
1 | // 如果需要,将包含VA的块的内容清除到磁盘,然后使用sys_page_map清除PTE_D位。 |
fs/fs.c中的fs_init()将会初始化super和bitmap全局指针变量。
至此对于文件系统进程只要访问虚拟内存[DISKMAP, DISKMAP+DISKMAX]范围中的地址addr,就会访问到磁盘((uint32_t)addr - DISKMAP) / BLKSIZE block中的数据。
如果block数据还没复制到内存物理页,bc_pgfault()缺页处理函数会将数据从磁盘拷贝到某个物理页,并且将addr映射到该物理页。这样FS进程只需要访问虚拟地址空间[DISKMAP, DISKMAP+DISKMAX]就能访问磁盘了。
JOS FS进程地址空间和磁盘映射:

The Block Bitmap
在fs_init设置位图(btimap)指针之后,我们可以将位图视为一个位的压缩数组,磁盘上的每个块对应一个位。例如,block_is_free,它只是检查位图中给定的块是否被标记为空闲。
Exercise 3:
使用free_block作为模型来实现fs/fs.c中的alloc_block,它应该在位图中找到一个空闲的磁盘块,标记它已被使用,并返回该块的编号。当您分配一个块时,您应该立即使用flush_block将更改后的位图块刷新到磁盘,以帮助文件系统保持一致性。
我们以一个实例来分析 bitmap的工作原理, 若标记第35个块(块号为34)为使用状态, 则将bitmap[1] 的第 2 (34%32)位标记为 0。 讲道理应该位图位为0是free的呀,JOS这里反过来了。
1 | // Search the bitmap for a free block and allocate it. When you |
File Operations
Exercise 4:
实现file_block_walk和file_get_block。file_block_walk将文件中的块偏移量映射到struct file或间接块中该块的指针,非常像pgdir_walk对页表所做的。File_get_block更进一步,映射到实际的磁盘块,如果需要,分配一个新的磁盘块。
file_block_walk 获得文件第filebno块的地址(其本身是个指针),编写需要注意以下几点。
ppdiskbno是块指针(记录块的地址)f_indirect直接记录块号,而不是记地址。- Don’t forget to clear any block you allocate. 对分配的块进行清零操作后,要写入 disk 中。
1 | // Find the disk block number slot for the 'filebno'th block in file 'f'. |
1 | // Set *blk to the address in memory where the filebno'th |
The file system interface
由于其他环境无法直接调用文件系统环境中的函数,因此我们将通过 RPC 或在JOS的IPC机制上构建的RPC抽象来公开对文件系统环境的访问。
RPC(Remote Procedure Call)。它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
1 |
|
本质上RPC还是借助IPC机制实现的,普通进程通过IPC向FS进程间发送具体操作和操作数据,然后FS进程执行文件操作,最后又将结果通过IPC返回给普通进程。从上图中可以看到客户端的代码在lib/fd.c和lib/file.c两个文件中。服务端的代码在fs/fs.c和fs/serv.c两个文件中。
相关数据结构之间的关系可用下图来表示:
%E5%8E%9F%E7%90%86.png)
文件系统服务端代码在fs/serv.c中,serve()中有一个无限循环,接收IPC请求,将对应的请求分配到对应的处理函数,然后将结果通过IPC发送回去。
对于客户端来说:发送一个32位的值作为请求类型,发送一个Fsipc结构作为请求参数,该数据结构通过IPC的页共享发给FS进程,在FS进程可以通过访问fsreq(0x0ffff000)来访问客户进程发来的Fsipc结构。
对于服务端来说:FS进程返回一个32位的值作为返回码,对于FSREQ_READ和FSREQ_STAT这两种请求类型,还额外通过IPC返回一些数据。
Exercise 5
Implement serve_read in fs/serv.c.
1 | int |
Exercise 6
Implement serve_write in fs/serv.c and devfile_write in lib/file.c.
serve_write: 在file_write中考虑了块边界的问题bn = MIN(BLKSIZE - pos % BLKSIZE, offset + count - pos);,因此我们同样不需要对 req_n 进行处理。
1 | int |
devfile_write: devfile_write需要调用fsipc,其向文件服务器发送一个进程间请求,并等待回复。请求体保存在fsipcbuf中,回复部分也应该写回到 fsipcbuf中。
1 | static ssize_t |
Spawning Processes
slib/spawn.c中的spawn()创建一个新的进程,从文件系统加载用户程序,然后启动该进程来运行这个程序。spawn()就像UNIX中的fork()后面马上跟着exec()。 spawn(const char *prog, const char **argv)`做如下一系列动作:
- 从文件系统打开prog程序文件
- 调用系统调用sys_exofork()创建一个新的Env结构
- 调用系统调用sys_env_set_trapframe(),设置新的Env结构的Trapframe字段(该字段包含寄存器信息)。
- 根据ELF文件中program herder,将用户程序以Segment读入内存,并映射到指定的线性地址处。
- 调用系统调用sys_env_set_status()设置新的Env结构状态为ENV_RUNNABLE。
我们实现了spawn而不是UNIX风格的exec,因为在没有内核特殊帮助的情况下,spawn更容易以“exokernel fashion”从用户空间实现。
Exercise 7
spawn C依赖新的系统调用sys_env_set_trapframe来初始化新创建的环境的状态。 在kern/syscall.c中实现sys_env_set_trapframe(不要忘记在sycall()中调度新的系统调用)。
1 | // Set envid's trap frame to 'tf'. |
Sharing library state across fork and spawn
在fork和spawn之间共享library的状态
在JOS中,每个设备类型都具有相应的struct Dev,其中包含指向实现读/写/等的函数指针。对于该设备类型。 lib / fd.c在此基础上实现了类似UNIX的通用文件描述符接口。 每个结构体Fd表示它的设备类型,lib/fd.c中的大多数函数只是将操作分派给适当的struct Dev中的函数。
1 | // Per-device-class file descriptor operations |
UNIX文件描述符是一个大的概念,包含pipe,控制台I/O。在JOS中每种设备对应一个struct Dev结构,该结构包含函数指针,指向真正实现读写操作的函数。
lib/fd.c文件实现了UNIX文件描述符接口,但大部分函数都是简单对struct Dev结构指向的函数的包装。
我们希望共享文件描述符,JOS中定义PTE新的标志位PTE_SHARE,如果有个页表条目的PTE_SHARE标志位为1,那么这个PTE在fork()和spawn()中将被直接拷贝到子进程页表,从而让父进程和子进程共享相同的页映射关系,从而达到父子进程共享文件描述符的目的。
Exercise 8
修改lib/fork.c中的duppage(),使之正确处理有PTE_SHARE标志的页表条目。同时实现lib/spawn.c中的copy_shared_pages()。
1 | static int |
1 | // Copy the mappings for shared pages into the child address space. |
The keyboard interface
目前我们只能在内核监视器中才能接收输入。kern/console.c already contains the keyboard and serial drivers that have been used by the kernel monitor since lab 1, but now you need to attach these to the rest of the system.
kern/console.c 已经包含了从实验1开始内核监视器就在使用的键盘和串行驱动程序,但是现在您需要将它们附加到系统的其他部分。
在/kern/console.c/cons_getc()中的代码,实现了在 monitor 模式下(禁止中断)可以正常获取用户输入。
1 | // poll for any pending input characters, |
在 trap.c 中加入中断处理函数。
1 | case (IRQ_OFFSET + IRQ_KBD): |
The Shell
总结
Lab5 主要介绍了文件系统的基本组成,为超级块分配易查找的位置,并在超级块中记录根目录文件,此后递进存储即实现了FS的多级目录。利用虚拟地址和MMIO实现了类似统一编址方式,我们可以很方便实现文件访问,其操作过程与内存访问很类似(在文件结构体中 walk 到块号)。
JOS在用户环境实现FS,FS接口是这个Lab的重点。其通过RPC公开接口,在JOS中利用IPC机制构建RPC抽象。regular env->read->ipc_send -> ipc_recv->serve->file_read。
这实际上以微内核的方式实现的FS,FS的serv相当于一种微服务进程,其接收、解析内核转发的信息再执行相应的操作。消息通过一个页映射的Union Fsipc进行传递。
spawn函数表现得像在Unix下创建子进程带有一个立刻执行exec的fork函数。exec()会把当前执行进程覆盖掉来执行外部程序,spawn()则会创建一个新的进程来执行。对于spawn的设计,还是有一些困惑,因为不明白 Unix-Style的exec是如何实现的,所以不能理解为什么spawn更容易在用户空间实现。
最后的Keyboard 接口和Shell都相对简单,比较容易理解。
- 其他环境无法直接调用文件系统环境中的函数,要通过IPC,进程间消息传递实现。这里应该就是微内核的概念了。但为什么不能直接调用,是怎么实现不能直接调用的?是特意不让别的环境直接使用其函数吗?有没有方法可以实现不同用户程序可以直接调用其他用户程序的函数?
不能直接调用,应该是因为每个用户态的代码都存在于自身的地址空间中,其他用户程序无法访问到。但是我如果在源代码中的某个环境直接#include并且调用另一个环境文件夹下的代码(例如fs),即在编译前就调用了,这会出现什么情况?这样就相当于是宏内核的概念了吗? 或者是这样设计会增大代码的耦合性?这让我十分疑惑。毕竟这与越过系统调用不一样,系统调用有权限限制。