6-828Lab4
LAB4: Preemtive Multitasking 抢占式多任务处理
您将在多个同时活跃的用户模式环境中实现抢占式多任务处理。
在A部分中,您将向JOS添加多处理器支持,实现循环调度,并添加基本的环境管理系统调用(创建和销毁环境的调用,以及分配/映射内存的调用)。
在B部分中,您将实现一个类unix的fork(),它允许用户模式环境创建自身的副本。
最后,在C部分中,您将添加对进程间通信(IPC)的支持,允许不同的用户模式环境显式地相互通信和同步。您还将添加对硬件时钟中断和抢占的支持
Part A: Multiprocessor Support and Cooperative Multitasking多处理器支持和多任务协作
我们首先需要把 JOS 扩展到在多处理器系统中运行。然后实现一些新的 JOS 系统调用来允许用户进程创建新的进程。我们还要实现协同轮询调度,允许内核在当前进程自愿放弃CPU(或退出cpu)时从一个环境切换到另一个环境。
我们即将使 JOS 能够支持“对称多处理” (Symmetric MultiProcessing, SMP)。这种模式使所有 CPU 能对等地访问内存、I/O 总线等系统资源。虽然 CPU 在 SMP 下以同样的方式工作,在启动过程中他们可以被分为两个类型:引导处理器(BootStrap Processor, BSP) 负责初始化系统以及启动操作系统;应用处理器( Application Processors, AP ) 在操作系统拉起并运行后由 BSP 激活。哪个 CPU 作为 BSP 由硬件和 BIOS 决定。也就是说目前我们所有的 JOS 代码都运行在 BSP 上。
在 SMP 系统中,每个 CPU 都有一个附属的 LAPIC 单元。LAPIC 单元用于传递中断,并给它所属的 CPU 一个唯一的 ID。在 lab4 中,我们将会用到 LAPIC 单元的以下基本功能 ( 见kern/lapic.c中 ):
- 读取 APIC ID 来判断我们的代码运行在哪个 CPU 之上。(see
cpunum()) - 从 BSP 发送
STARTUP跨处理器中断 (InterProcessor Interrupt, IPI) 来启动 AP。(seelapic_startap()) - 在 part C 中,我们为 LAPIC 的内置计时器编程来触发时钟中断以支持抢占式多任务处理。(see
apic_init())
处理器通过映射在内存上的 I/O (Memory-Mapped I/O, MMIO) 来访问它的 LAPIC。在 MMIO 中,物理内存的一部分被硬连接到一些 I/O 设备的寄存器,因此,访问内存的 load/store 指令可以被用于访问设备的寄存器。实际上,我们在 lab1 中已经接触过这样的 IO hole,如0xA0000被用来写 VGA 显示缓冲。LAPIC 开始于物理地址0xFE000000 ( 4GB以下32MB处 )。如果用以前的映射算法(将0xF0000000 映射到 0x00000000,也就是说内核空间最高只能到物理地址0x0FFFFFFF)显然太高了。因此,JOS 在 MMIOBASE (即 虚拟地址0xEF800000) 预留了 4MB 来映射这类设备。我们需要写一个函数来分配这个空间并在其中映射设备内存。

LAPIC 和 IOAPIC
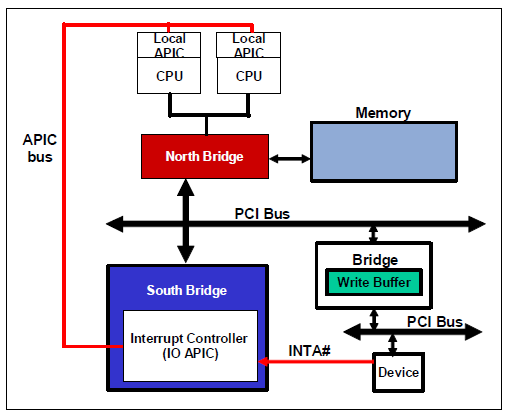
APIC全称是Advanced Programmable Interrupt Controller,高级可编程中断控制器。它是在奔腾P54C之后被引入进来的。
在现在的计算机它通常由两个部分组成,分别为LAPIC(Local APIC,本地高级可编程中断控制器)和IOAPIC(I/O高级可编程中断控制器)。
LAPIC在CPU中,IOAPIC通常位于南桥。
APIC是在PIC (Programmable Interrupt Controller) 的基础上发展而来的
IOAPIC: IOAPIC的主要作用是中断的分发。最初有一条专门的APIC总线用于IOAPIC和LAPIC通信,在Pentium4 和Xeon 系列CPU出现后,他们的通信被合并到系统总线中。
Exercise 1: Multiprocessor Support
Implement mmio_map_region in kern/pmap.c. To see how this is used, look at the beginning of lapic_init in kern/lapic.c. You’ll have to do the next exercise, too, before the tests for mmio_map_region will run.
*void mmio_map_region(physaddr_t pa, size_t size)
1 | Reserve size bytes in the MMIO region and map [pa,pa+size) at this location. Return the base of the reserved region. |
1 | void * |
void lapic_init(void)
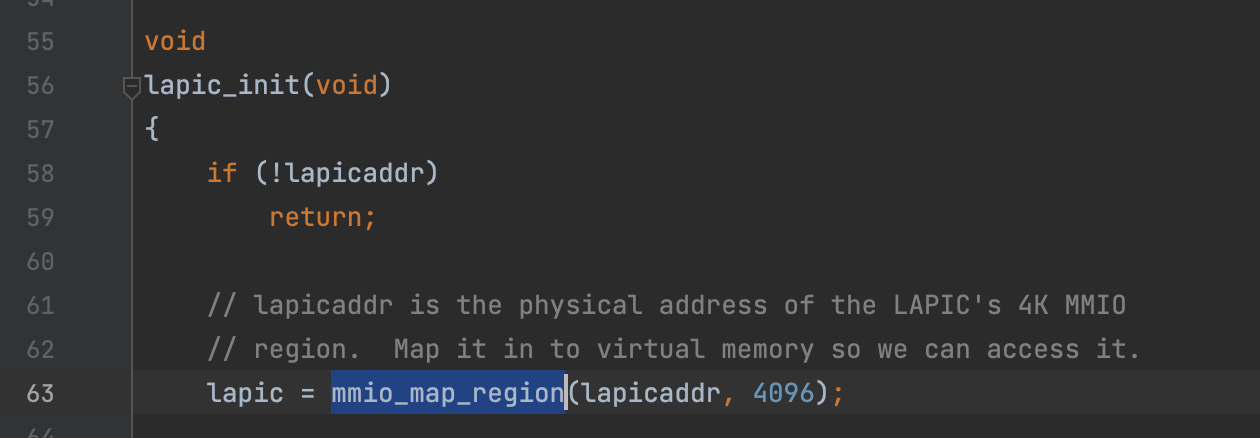
该函数一开始就调用了mmin_map_region函数,pa为lapicaddr,size为4096 = 4KB,即将从lapicaddr开始的4KB的物理地址映射到虚拟地址(保留区域),以便我们能访问,然后返回保留区域的起始地址。
Exercise 2: Application Processor Bootstrap
在启动 APs 之前,BSP 需要先搜集多处理器系统的信息,例如 CPU 的总数,CPU 各自的 APIC ID,LAPIC 单元的 MMIO 地址。kern/mpconfig.c 中的 mp_init() 函数通过阅读 BIOS 区域内存中的 MP 配置表来获取这些信息。boot_aps() 函数驱动了 AP 的引导。APs 从实模式开始,如同 boot/boot.S 中 bootloader 的启动过程。因此 boot_aps() 将 AP 的入口代码 (kern/mpentry.S) 拷贝到实模式可以寻址的内存区域 (0x7000, MPENTRY_PADDR)。
此后,boot_aps() 通过发送 STARTUP 这个跨处理器中断到各 LAPIC 单元的方式,逐个激活 APs。激活方式为:初始化 AP 的 CS:IP 值使其从入口代码执行。通过一些简单的设置,AP 开启分页进入保护模式,然后调用 C 语言编写的 mp_main()。boot_aps() 等待 AP 发送 CPU_STARTED 信号,然后再唤醒下一个。
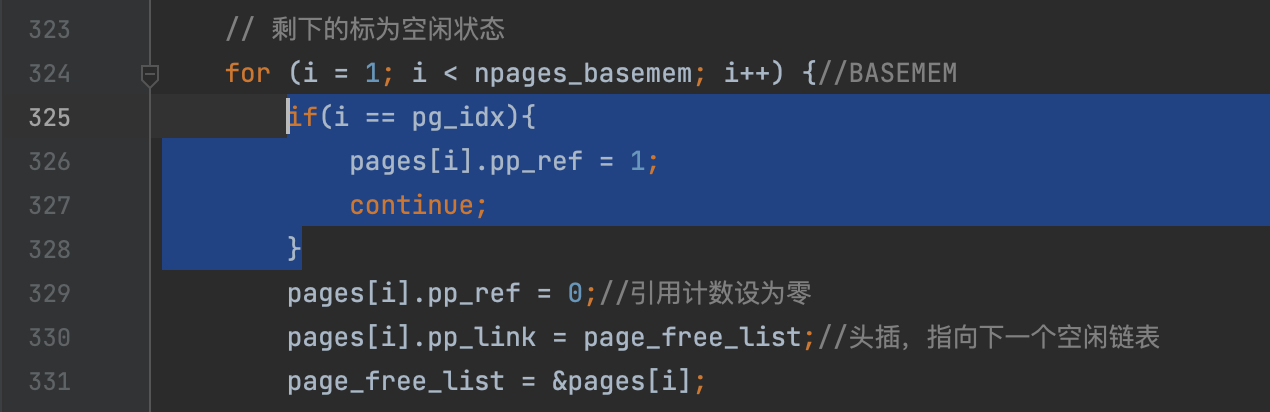
Read boot_aps() and mp_main() in kern/init.c, and the assembly code in kern/mpentry.S. Make sure you understand the control flow transfer during the bootstrap of APs. Then modify your implementation of page_init() in kern/pmap.cto avoid adding the page at MPENTRY_PADDR to the free list, so that we can safely copy and run AP bootstrap code at that physical address. Your code should pass the updated check_page_free_list() test (but might fail the updated check_kern_pgdir() test, which we will fix soon).

real mode表示我们看到的都是直接的物理地址
Question
- Compare
kern/mpentry.Sside by side withboot/boot.S. Bearing in mind thatkern/mpentry.Sis compiled and linked to run aboveKERNBASEjust like everything else in the kernel, what is the purpose of macroMPBOOTPHYS? Why is it necessary inkern/mpentry.Sbut not inboot/boot.S? In other words, what could go wrong if it were omitted inkern/mpentry.S?
Hint: recall the differences between the link address and the load address that we have discussed in Lab 1.
MPBOOTPHYS的作用:
kern/mpentry.S是运行在kernbase之上的,因此在实地址模式下,无法进行寻址(即无法访问)。
kern/mpentry.S
1 | # This code is similar to boot/boot.S except that |
((s) - mpentry_start + MPENTRY_PADDR) 表示把mpentry地址转换到MPENTRY_PADDR。
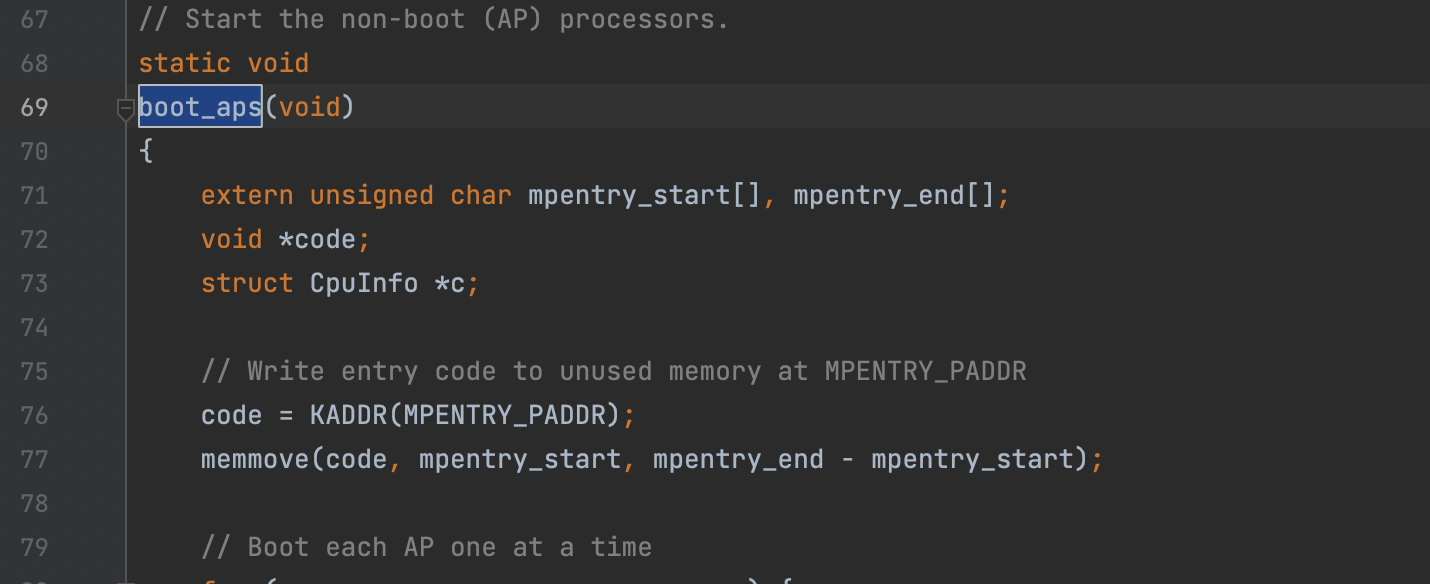
kern/init.c中已经进行了内容的拷贝,因此boot.S不需要再次 进行拷贝。而mpentry.S需要宏进行拷贝。
Per-CPU State and Initialization(CPU私有状态和初始化)
当写一个多处理器操作系统时,分清 CPU 的私有状态 ( per-CPU state) 及全局状态 (global state) 非常关键。 kern/cpu.h 定义了大部分的 per-CPU 状态。
我们需要注意的 per-CPU 状态有:
Per-CPU 内核栈
因为多 CPU 可能同时陷入内核态,我们需要给每个处理器一个独立的内核栈。用户态切到内核态,内核将用户态时的堆栈寄存器的值保存在内核栈中,以便于从内核栈切换回进程栈时能找到用户栈的地址。percpu_kstacks[NCPU][KSTKSIZE]
在 Lab2 中,我们将 BSP 的内核栈映射到了 KSTACKTOP 下方。相似地,在 Lab4 中,我们需要把每个 CPU 的内核栈都映射到这个区域,每个栈之间留下一个空页作为缓冲区避免 overflow。CPU 0 ,即 BSP 的栈还是从KSTACKTOP开始,间隔KSTACKGAP的距离就是 CPU 1 的栈,以此类推。Per-CPU TSS 以及 TSS 描述符
为了指明每个 CPU 的内核栈位置,需要任务状态段 (Task State Segment, TSS),其功能在 Lab3 中已经详细讲过。Per-CPU 当前环境指针
因为每个 CPU 能够同时运行各自的用户进程,我们重新定义了基于cpus[cpunum()]的curenv。Per-CPU 系统寄存器
所有的寄存器,包括系统寄存器,都是 CPU 私有的。因此,初始化这些寄存器的指令,例如lcr3(), ltr(), lgdt(), lidt()等,必须在每个 CPU 都执行一次。
Exercise 3.
Modify mem_init_mp() (in kern/pmap.c) to map per-CPU stacks starting at KSTACKTOP, as shown in inc/memlayout.h. The size of each stack is KSTKSIZE bytes plus KSTKGAP bytes of unmapped guard pages. Your code should pass the new check in check_kern_pgdir().
1 | static void |
Exercise 4.
在 inc/memlayout.h 中可以看到之前分配BSP时,TSS0的定义

这只是对单CPU而言的定义,那么对于多个cpu,就需要其他的TSS,如何寻找这个TSS?trap_init_percpu()注释中说明了
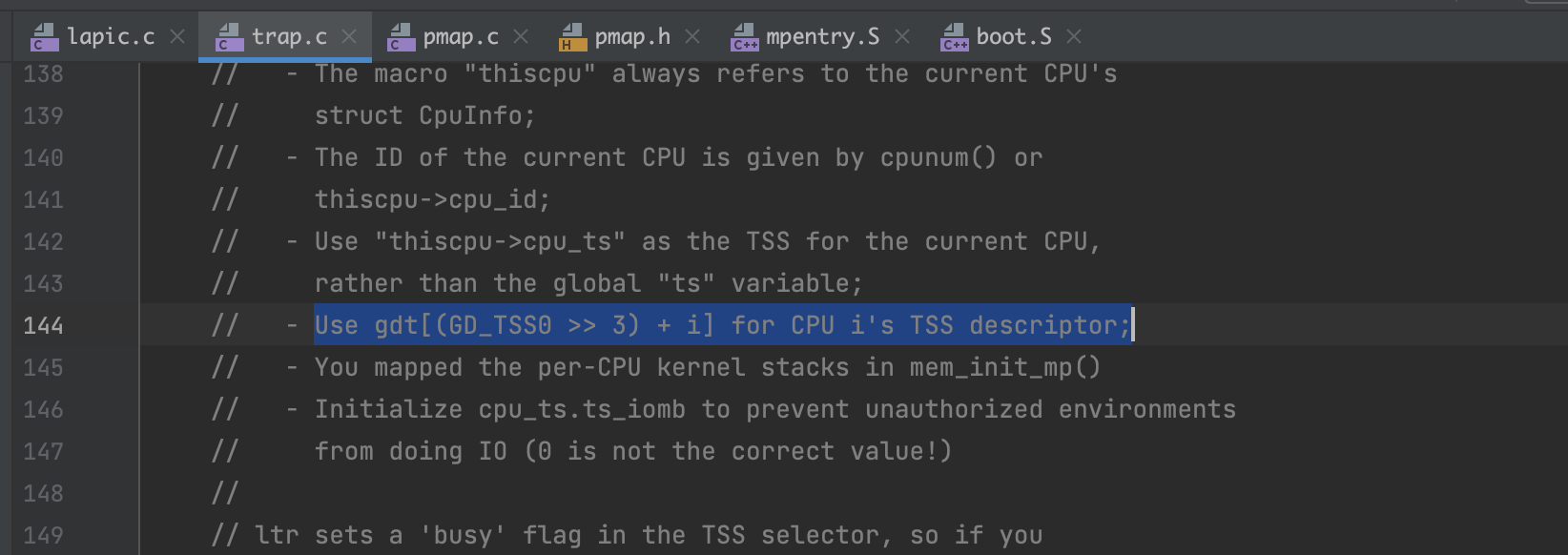
1 | // Initialize and load the per-CPU TSS and IDT |
运行 make qemu CPUS=4 (or make qemu-nox CPUS=4)
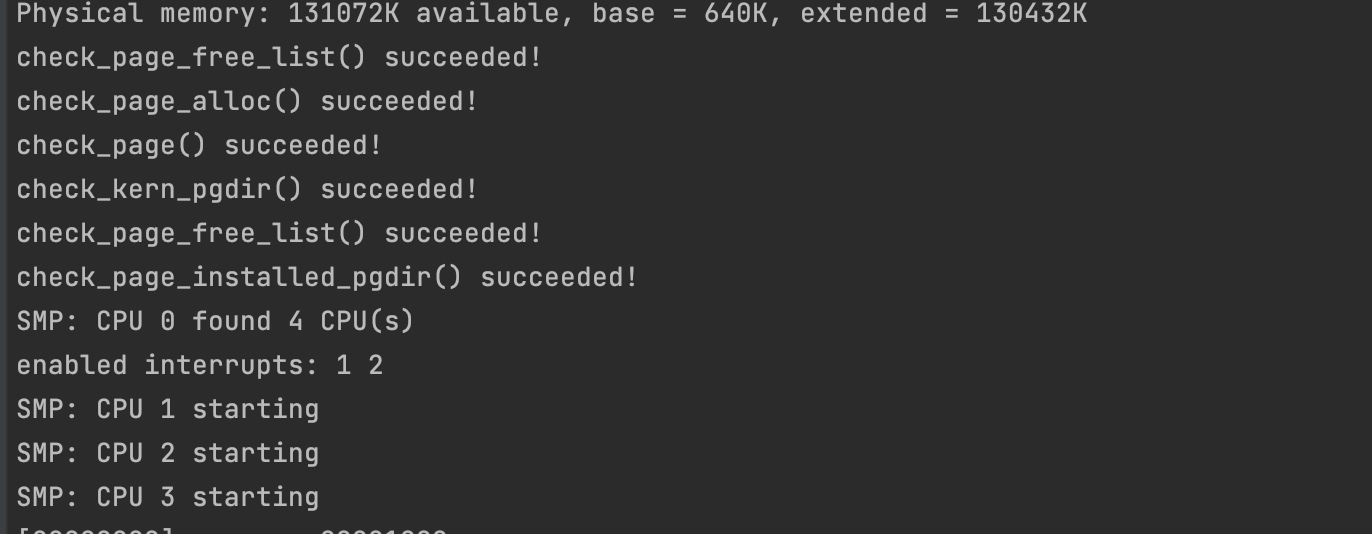
Exercise5: Locking
我们现在的代码在初始化 AP 后就会开始自旋。在进一步操作 AP 之前,我们要先处理几个 CPU 同时运行内核代码的竞争情况。最简单的方法是用一个大内核锁 (big kernel lock)。它是一个全局锁,在某个进程进入内核态时锁定,返回用户态时释放。这种模式下,用户进程可以并发地在 CPU 上运行,但是同一时间仅有一个进程可以在内核态,其他需要进入内核态的进程只能等待。kern/spinlock.h 声明了一个大内核锁 kernel_lock。它提供了 lock_kernel() 和 unlock_kernel() 方法用于获得和释放锁。在以下 4 个地方需要使用到大内核锁:
- 在
i386_init(),BSP 唤醒其他 CPU 之前获得内核锁 - 在
mp_main(),初始化 AP 之后获得内核锁,之后调用sched_yield()在 AP 上运行进程。 - 在
trap(),当从用户态陷入内核态时获得内核锁,通过检查tf_Cs的低 2bit 来确定该 trap 是由用户进程还是内核触发。 - 在
env_run(),在切换回用户模式前释放内核锁。
Apply the big kernel lock as described above, by calling lock_kernel() and unlock_kernel() at the proper locations.
kern/init.c/i386_init()
1 | // Acquire the big kernel lock before waking up APs |
init.c/mp_main()
1 | // Now that we have finished some basic setup, call sched_yield() |
trap.c/trap()
1 | if ((tf->tf_cs & 3) == 3) { // 陷入了内核态 |
env.c/env_run()
1 | lcr3(PADDR(e->env_pgdir)); |
为什么要在这几处加大内核锁
从根本上来讲,其设计的初衷就是保证独立性。由于分页机制的存在,内核以及每个用户进程都有自己的独立空间。而多进程并发的时候,如果两个进程同时陷入内核态,就无法保证独立性了。例如内核中有某个全局变量 A,cpu1 让 A=1, 而后 cpu2 却让 A=2,显然会互相影响。
BPS 启动 AP 前,获取内核锁,所以 AP 会在 mp_main 执行调度之前阻塞,在启动完 AP 后,BPS 执行调度,运行第一个进程,env_run() 函数中会释放内核锁,这样一来,其中一个 AP 就可以开始执行调度,运行其他进程。
Question 2.
It seems that using the big kernel lock guarantees that only one CPU can run the kernel code at a time. Why do we still need separate kernel stacks for each CPU? Describe a scenario in which using a shared kernel stack will go wrong, even with the protection of the big kernel lock
在某进程即将陷入内核态的时候(尚未获得锁),其实在 trap() 函数之前已经在 trapentry.S 中对内核栈进行了操作,压入了寄存器信息。如果共用一个内核栈,那显然会导致信息错误。
Exercise6: Round-Robin Scheduling 轮询调度
下一个任务是让 JOS 内核能够以轮询方式在多个任务之间切换。其原理如下:
kern/sched.c中的sched_yield()函数用来选择一个新的进程运行。它将从上一个运行的进程开始,按顺序循环搜索envs[]数组,选取第一个状态为ENV_RUNNABLE的进程执行。sched_yield()不能同时在两个CPU上运行同一个进程。如果一个进程已经在某个 CPU 上运行,其状态会变为ENV_RUNNING。- 程序中已经实现了一个新的系统调用
sys_yield(),进程可以用它来唤起内核的sched_yield()函数,从而将 CPU 资源移交给一个其他的进程
Exercise 6.
Implement round-robin scheduling in sched_yield() as described above. Don’t forget to modify syscall() to dispatch sys_yield().
Make sure to invoke sched_yield() in mp_main.
Modify kern/init.c to create three (or more!) environments that all run the program user/yield.c.
首先要找到正在运行的进程在envs[]中的序号。
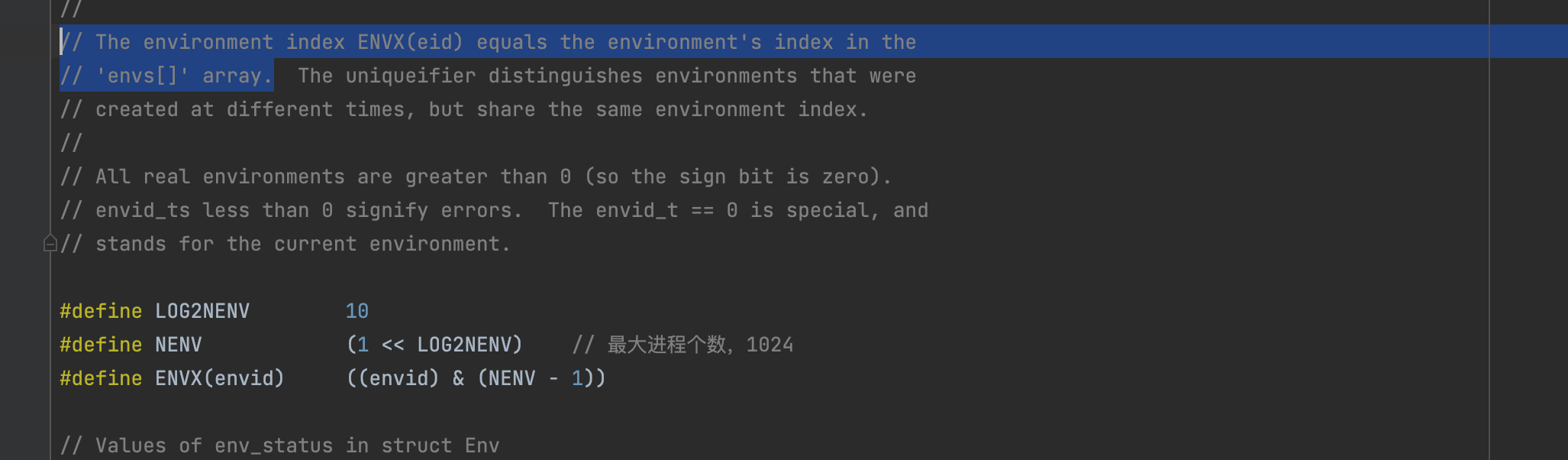
sched.c/sched_yield()
1 | // Choose a user environment to run and run it. |
inc/syscall.h
1 | /* system call numbers */ 在syscall.h中有定义,syscall不是trap!!! |
Question 3.
In your implementation ofenv_run()you should have calledlcr3(). Before and after the call tolcr3(), your code makes references (at least it should) to the variablee, the argument toenv_run. Upon loading the%cr3register, the addressing context used by the MMU is instantly changed. But a virtual address (namelye) has meaning relative to a given address context–the address context specifies the physical address to which the virtual address maps. Why can the pointer e be dereferenced both before and after the addressing switch?
大意是问为什么通过 lcr3() 切换了页目录,还能照常对 e 解引用。回想在 lab3 中,曾经写过的函数 env_setup_vm()。它直接以内核的页目录作为模版稍做修改。因此两个页目录的 e 地址映射到同一物理地址。
Question 4.
Whenever the kernel switches from one environment to another, it must ensure the old environment’s registers are saved so they can be restored properly later. Why? Where does this happen?
在进程陷入内核时,会保存当前的运行信息,这些信息都保存在内核栈上。而当从内核态回到用户态时,会恢复之前保存的运行信息。
具体到 JOS 代码中,保存发生在 kern/trapentry.S,恢复发生在 kern/env.c。可以对比两者的代码。
保存:
1 | #define TRAPHANDLER_NOEC(name, num) |
恢复:
1 | void |
1 | ➜ lab git:(lab4) ✗ make qemu-nox CPUS=2 |
cpu=2时,三个进程通过sys_yield切换了5次。
Exercise 7: System Calls for Environment Creation(系统调用: 创建进程)
现在我们的内核已经可以运行多个进程,并在其中切换了。不过,现在它仍然只能运行内核最初设定好的程序 (kern/init.c) 。现在我们即将实现一个新的系统调用,它允许进程创建并开始新的进程。
Unix 提供了 fork() 这个原始的系统调用来创建进程。fork()将会拷贝父进程的整个地址空间来创建子进程。在用户空间里,父子进程之间的唯一区别就是它们的进程 ID。fork()在父进程中返回其子进程的进程 ID,而在子进程中返回 0。父子进程之间是完全独立的,任意一方修改内存,另一方都不会受到影响。
我们将为 JOS 实现一个更原始的系统调用来创建新的进程。涉及到的系统调用如下:
sys_exofork:
这个系统调用将会创建一个空白进程:在其用户空间中没有映射任何物理内存,并且它是不可运行的。刚开始时,它拥有和父进程相同的寄存器状态。sys_exofork将会在父进程返回其子进程的envid_t,子进程返回 0(当然,由于子进程还无法运行,也无法返回值,直到运行:)sys_env_set_status:
设置指定进程的状态。这个系统调用通常用于在新进程的地址空间和寄存器初始化完成后,将其标记为可运行。sys_page_alloc:
分配一个物理页并将其映射到指定进程的指定虚拟地址上。sys_page_map:
从一个进程中拷贝一个页面映射(而非物理页的内容)到另一个。即共享内存。sys_page_unmap:
删除到指定进程的指定虚拟地址的映射。
Exercise 7.
Implement the system calls described above inkern/syscall.c. You will need to use various functions inkern/pmap.candkern/env.c, particularlyenvid2env(). For now, whenever you callenvid2env(), pass 1 in thecheckpermparameter. Be sure you check for any invalid system call arguments, returning-E_INVALin that case. Test your JOS kernel withuser/dumbforkand make sure it works before proceeding.
一个比较冗长的练习。重点应该放在阅读 user/dumbfork.c 上,以便理解各个系统调用的作用。
在 user/dumbfork.c 中,核心是 duppage() 函数。它利用 sys_page_alloc() 为子进程分配空闲物理页,再使用sys_page_map() 将该新物理页映射到内核 (内核的 env_id = 0) 的交换区 UTEMP,方便在内核态进行 memmove 拷贝操作。在拷贝结束后,利用 sys_page_unmap() 将交换区的映射删除。
1 | void |
sys_exofork() 函数
该函数主要是分配了一个新的进程,但是没有做内存复制等处理。唯一值得注意的就是如何使子进程返回0。sys_exofork()是一个非常特殊的系统调用,它的定义与实现在 inc/lib.h 中,而不是 lib/syscall.c 中。并且,它必须是 inline 的。
1 | // This must be inlined. Exercise for reader: why? |
可以看出,它的返回值是 %eax 寄存器的值。那么,它到底是什么时候返回?这就涉及到对整个 进程->内核->进程 的过程的理解。
1 | static envid_t |
在该函数中,子进程复制了父进程的 trapframe,此后把 trapframe 中的 eax 的值设为了0。最后,返回了子进程的 id。注意,根据 kern/trap.c 中的 trap_dispatch() 函数,这个返回值仅仅是存放在了父进程的 trapframe 中,还没有返回。而是在返回用户态的时候,即在 env_run() 中调用 env_pop_tf() 时,才把 trapframe 中的值赋值给各个寄存器。这时候 lib/syscall.c 中的函数 syscall() 才获得真正的返回值。因此,在这里对子进程 trapframe 的修改,可以使得子进程返回0。
sys_page_alloc() 函数
在进程 envid 的目标地址 va 分配一个权限为 perm 的页面。
1 | static int |
sys_page_map() 函数
简单来说,就是建立跨进程的映射。
在srcenvid地址空间的’srcva’映射到dstenvid地址空间的’dstva’,并赋予’perm ‘权限。Perm具有与sys_page_alloc相同的限制,但它也不能授予对只读页面的写访问权。
1 | static int |
sys_page_unmap() 函数
取消映射。
1 | static int |
sys_env_set_status() 函数
设置状态,在子进程内存 map 结束后再使用。
1 | static int |
最后,不要忘记在 kern/syscall.c 中添加新的系统调用类型,注意参数的处理。
1 | ... |
make grade 成功。至此,part A 结束。
链接:https://www.jianshu.com/p/10f822b3deda
Part B: Copy-on-Write Fork 写时拷贝的Fork
在Part A中,通过把父进程的所有内存数据拷贝到子进程实现了fork(), 这也是 Unix 系统早期的实现。这个拷贝到过程是 fork() 时最昂贵的操作。
然而,调用了 fork() 之后往往立即就会在子进程中调用 exec() ,将子进程的内存更换为新的程序,例如 shell 经常干的(HW:Shell)。这样,复制父进程的内存这个操作就完全浪费了。
因此,后来的 Unix 系统让父、子进程共享同一片物理内存,直到某个进程修改了内存。这被称作 copy-on-write。为了实现它,fork()时内核只拷贝页面的映射关系,而不拷贝其内容,同时将共享的页面标记为只读 (read-only)。当父子进程中任一方向内存中写入数据时,就会触发 page fault。此时,Unix 就知道应该分配一个私有的可写内存给这个进程。这个优化使得 fork() + exec() 连续操作变得非常廉价。在执行 exec() 之前,只需要拷贝一个页面,即当前的栈。
在 Part B 中,我们将实现上述更佳实现方式的 fork()。
User-level page fault handling 用户级别的页错误
内核必须要记录进程不同区域出现页面错误时的处理方法。例如,一个栈区域的 page fault 会分配并映射一个新的页。一个 BSS 区域(用于存放程序中未初始化的全局变量、静态变量)的页错误会分配一个新的页面,初始化为0,再映射。
用户级别的页错误处理流程为:
- 页错误异常,陷入内核
- 内核修改
%esp切换到进程的异常栈,修改%eip让进程运行 _pgfault_upcall - _pgfault_upcall 将运行 page fault handler,此后不通过内核切换回正常栈
EIP为:返回本次调用后,下一条指令的地址。
ESP:存放当前线程的栈顶指针。
EBP:存放当前线程的栈底指针。
在采用段式内存管理的架构中(比如intel的80x86系统),bss段(Block Started by Symbolsegment)通常是指用来存放程序中未初始化的全局变量的一块内存区域,一般在初始化时bss段部分将会清零。bss段属于静态内存分配,即程序一开始就将其清零了。
Exercise 8: 设置页错误处理函数
为处理自己的页错误,进程需要在 JOS 注册一个 page fault handler entrypoint。进程通过 sys_env_set_pgfault_upcall 注册自己的 entrypoint,并在 Env 结构体中新增 env_pgfault_upcall 来记录该信息。
Exercise 8.
Implement thesys_env_set_pgfault_upcallsystem call. Be sure to enable permission checking when looking up the environment ID of the target environment, since this is a “dangerous” system call.
进程的正常栈和异常栈
正常运行时,JOS 的进程会运行在正常栈上,ESP 从USTACKTOP开始往下生长,栈上的数据存放在 [USTACKTOP-PGSIZE, USTACKTOP-1] 上。当出现页错误时,内核会把进程在一个新的栈(异常栈)上面重启,运行指定的用户级别页错误处理函数。也就是说完成了一次进程内的栈切换。这个过程与 trap 的过程很相似。
JOS 的异常栈也只有一个物理页大小,并且它的栈顶定义在虚拟内存 UXSTACKTOP 处。当运行在这个栈上时,用户级别页错误处理函数可以使用 JOS 的系统调用来映射新的页,以修复页错误。
每个需要支持用户级页错误处理的函数都需要分配自己的异常栈。可以使用 sys_page_alloc() 这个系统调用来实现。
用户页错误处理函数
现在我们需要修改 kern/trap.c 以支持用户级别的页错误处理。
如果没有注册 page fault handler,JOS内核就直接销毁进程。否则,内核就会初始化一个 trap frame 记录寄存器状态,在异常栈上处理页错误,恢复进程的执行。UTrapframe 在异常栈栈上如下所示。
1 | <-- UXSTACKTOP |
相比 trap 时使用的 Trapframe,多了记录错误位置的 fault_va,少了段选择器%cs, %ds, %ss。这反映了两者最大的不同:是否发生了进程的切换。
如果异常发生时,进程已经在异常栈上运行了,这就说明 page fault handler 本身出现了问题。这时,我们就应该在 tf->tf_esp 处分配新的栈,而不是在 UXSTACKTOP。首先需要 push 一个空的 32bit word 作为占位符,然后是一个 UTrapframe 结构体。
为检查 tf->tf_esp 是否已经在异常栈上了,只要检查它是否在区间 [UXSTACKTOP-PGSIZE, UXSTACKTOP-1] 上即可。
以下9,10,11三个练习,建议按照调用顺序来看,即 11(设置handler)->9(切换到异常栈)->10(运行handler,切换回正常栈)。
Exercise 9.
Implement the code in
page_fault_handlerinkern/trap.crequired to dispatch page faults to the user-mode handler. Be sure to take appropriate precautions when writing into the exception stack. (What happens if the user environment runs out of space on the exception stack?)
可参考 Exercise 10 的 lib/pfentry.S 中的注释
较有难度的一个练习。首先需要理解用户级别的页错误处理的步骤是:
进程A(正常栈) -> 内核 -> 进程A(异常栈) -> 进程A(正常栈)
那么内核的工作就是修改进程 A 的某些寄存器,并初始化异常栈,确保能顺利切换到异常栈运行。需要注意的是,由于修改了eip, env_run() 是不会返回的,因此不会继续运行后面销毁进程的代码。
值得注意的是,如果是嵌套的页错误,为了能实现递归处理,栈留出 32bit 的空位,直接向下生长。
1 | void |
Question
What happens if the user environment runs out of space on the exception stack?
在 inc/memlayout.h 中可以找到:
1 |
|
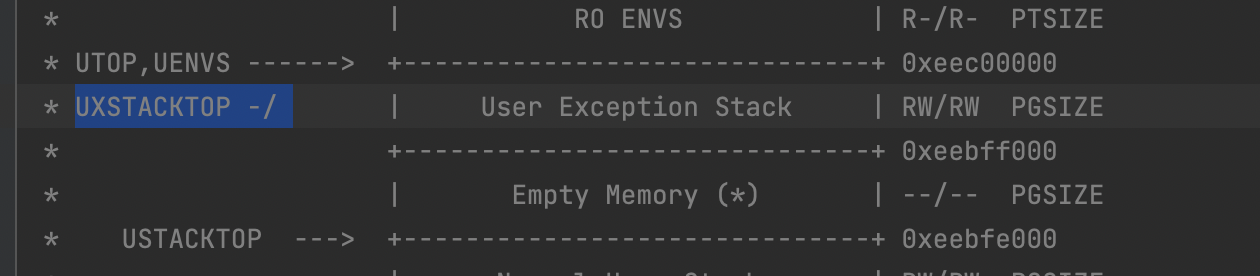
下面一页是空页,内核和用户访问都会报错。
用户模式页错误入口
在处理完页错误之后,现在我们需要编写汇编语句实现从异常栈到正常栈的切换。
Exercise 10.
Implement the _pgfault_upcall routine in lib/pfentry.S. The interesting part is returning to the original point in the user code that caused the page fault. You’ll return directly there, without going back through the kernel. The hard part is simultaneously switching stacks and re-loading the EIP.
汇编苦手,写的很艰难,最终还是参考了别人的答案。
1 | .text |
首先必须要理解异常栈的结构,下图所示的是嵌套异常时的情况。其中左边表示内容,右边表示地址。需要注意的是,上一次异常的栈顶之下间隔 4byte,就是一个新的异常。

uxstack.png
最难理解的是这一部分:
1 | movl 48(%esp), %ebp // 使 %ebp 指向 utf_esp |
经过这一部分的修改,异常栈更新为(红字标出):

uxstack_new.png
此后就是恢复各寄存器,最后的 ret 指令相当于 popl %eip,指令寄存器的值修改为 utf_eip,达到了返回的效果。
Exercise 11.
Finish
set_pgfault_handler()inlib/pgfault.c.
该练习是用户用来指定缺页异常处理方式的函数。代码比较简单,但是需要区分清楚 handler,_pgfault_handler,_pgfault_upcall 三个变量。
handler是传入的用户自定义页错误处理函数指针。_pgfault_upcall是一个全局变量,在lib/pfentry.S中完成的初始化。它是页错误处理的总入口,页错误除了运行 page fault handler,还需要切换回正常栈。_pgfault_handler被赋值为handler,会在_pgfault_upcall中被调用,是页错误处理的一部分。具体代码是:
1 | .text |
1 | void |
若是第一次调用,需要首先分配一个页面作为异常栈,并且将该进程的 upcall 设置为 Exercise 10 中的程序。此后如果需要改变handler,不需要再重复这个工作。
最后直接通过 make grade 测试,满足要求。
Question
Whyuser/faultallocanduser/faultallocbadbehave differently?
两者的 page fault handler 一样,但是一个使用 cprintf() 输出,另一个使用 sys_cput() 输出。sys_cput()直接通过 lib/syscall.c 发起系统调用,其实现在 kern/syscall.c 中:
1 | static void |
它检查了内存,因此在这里 panic 了。中途没有触发过页错误。
而 cprintf() 的实现可以在 lib/printf.c 中找到:
1 | int |
它在调用 sys_cputs() 之前,首先在用户态执行了 vprintfmt() 将要输出的字符串存入结构体 b 中。在此过程中试图访问 0xdeadbeef 地址,触发并处理了页错误(其处理方式是在错误位置处分配一个字符串,内容是 "this string was faulted in at ..."),因此在继续调用 sys_cputs() 时不会出现 panic。
Implementing Copy-on-Write Fork
如同 dumbfork() 一样,fork() 也要创建一个新进程,并且在新进程中建立与父进程同样的内存映射。关键的不同点是,**dumbfork() 拷贝了物理页的内容,而 fork() 仅拷贝了映射关系,仅在某个进程需要改写某一页的内容时,才拷贝这一页的内容。其基本流程如下:**
- 父进程使用
set_pgfault_handler将pgfault()设为 page fault handler - 父进程使用
sys_exofork()建立一个子进程 - 对每个在
UTOP之下可写页面以及 COW 页面(用PTE_COW标识),父进程调用duppage将其“映射”到子进程,同时将其权限改为只读,并用PTE_COW位来与一般只读页面区别
异常栈的分配方式与此不同,需要在子进程中分配一个新页面。因为 page fault handler 会实实在在地向异常栈写入内容,并在异常栈上运行。如果异常栈页面都用 COW 机制,那就没有能够执行拷贝这个过程的载体了 - 父进程会为子进程设置 user page fault entrypoint
- 子进程已经就绪,父进程将其设为 runnable
进程第一次往一个 COW page 写入内容时,会发生 page fault,其流程为:
- 内核将 page fault 传递至
_pgfault_upcall,它会调用pgfault()handler pgfault()检查错误类型,以及页面是否标记为PTE_COWpgfault()分配一个新的页面并将 fault page 的内容拷贝进去,然后将旧的映射覆盖,使其映射到该新页面。
Exercise 12.
Implement
fork,duppageandpgfaultinlib/fork.c.
Test your code with theforktreeprogram.
非常难的一个练习。
fork() 函数
首先从主函数
fork()入手,其大体结构可以仿造user/dumbfork.c写,但是有关键几处不同:- 设置 page fault handler,即 page fault upcall 调用的函数
- duppage 的范围不同,
fork()不需要复制内核区域的映射 - 为子进程设置 page fault upcall,之所以这么做,是因为
sys_exofork()并不会复制父进程的e->env_pgfault_upcall给子进程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39envid_t
fork(void)
{
// LAB 4: Your code here.
// panic("fork not implemented");
set_pgfault_handler(pgfault);
envid_t e_id = sys_exofork();
if (e_id < 0) panic("fork: %e", e_id);
if (e_id == 0) {
// child
thisenv = &envs[ENVX(sys_getenvid())];
return 0;
}
// parent
// extern unsigned char end[];
// for ((uint8_t *) addr = UTEXT; addr < end; addr += PGSIZE)
for (uintptr_t addr = UTEXT; addr < USTACKTOP; addr += PGSIZE) {
if ( (uvpd[PDX(addr)] & PTE_P) && (uvpt[PGNUM(addr)] & PTE_P) ) {
// dup page to child
duppage(e_id, PGNUM(addr));
}
}
// alloc page for exception stack
int r = sys_page_alloc(e_id, (void *)(UXSTACKTOP-PGSIZE), PTE_U | PTE_W | PTE_P);
if (r < 0) panic("fork: %e",r);
// DO NOT FORGET
extern void _pgfault_upcall();
r = sys_env_set_pgfault_upcall(e_id, _pgfault_upcall);
if (r < 0) panic("fork: set upcall for child fail, %e", r);
// mark the child environment runnable
if ((r = sys_env_set_status(e_id, ENV_RUNNABLE)) < 0)
panic("sys_env_set_status: %e", r);
return e_id;
}duppage() 函数
该函数的作用是复制父、子进程的页面映射。尤其注意一个权限问题。由于
sys_page_map()页面的权限有硬性要求,因此必须要修正一下权限。之前没有修正导致一直报错,后来发现页面权限为0x865,不符合sys_page_map()要求。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26static int
duppage(envid_t envid, unsigned pn)
{
int r;
// LAB 4: Your code here.
// panic("duppage not implemented");
envid_t this_env_id = sys_getenvid();
void * va = (void *)(pn * PGSIZE);
int perm = uvpt[pn] & 0xFFF;
if ( (perm & PTE_W) || (perm & PTE_COW) ) {
// marked as COW and read-only
perm |= PTE_COW;
perm &= ~PTE_W;
}
// IMPORTANT: adjust permission to the syscall
perm &= PTE_SYSCALL;
// cprintf("fromenvid = %x, toenvid = %x, dup page %d, addr = %08p, perm = %03x\n",this_env_id, envid, pn, va, perm);
if((r = sys_page_map(this_env_id, va, envid, va, perm)) < 0)
panic("duppage: %e",r);
if((r = sys_page_map(this_env_id, va, this_env_id, va, perm)) < 0)
panic("duppage: %e",r);
return 0;
}pgfault() 函数
这是 _pgfault_upcall 中调用的页错误处理函数。在调用之前,父子进程的页错误地址都引用同一页物理内存,该函数作用是分配一个物理页面使得两者独立。
首先,它分配一个页面,映射到了交换区PFTEMP这个虚拟地址,然后通过memmove()函数将addr所在页面拷贝至PFTEMP,此时有两个物理页保存了同样的内容。再将addr也映射到PFTEMP对应的物理页,最后解除了PFTEMP的映射,此时就只有addr指向新分配的物理页了,如此就完成了错误处理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38static void
pgfault(struct UTrapframe *utf)
{
void *addr = (void *) utf->utf_fault_va;
uint32_t err = utf->utf_err;
int r;
// Check that the faulting access was (1) a write, and (2) to a
// copy-on-write page. If not, panic.
// Hint:
// Use the read-only page table mappings at uvpt
// (see <inc/memlayout.h>).
// LAB 4: Your code here.
if ((err & FEC_WR)==0 || (uvpt[PGNUM(addr)] & PTE_COW)==0) {
panic("pgfault: invalid user trap frame");
}
// Allocate a new page, map it at a temporary location (PFTEMP),
// copy the data from the old page to the new page, then move the new
// page to the old page's address.
// Hint:
// You should make three system calls.
// LAB 4: Your code here.
// panic("pgfault not implemented");
envid_t envid = sys_getenvid();
if ((r = sys_page_alloc(envid, (void *)PFTEMP, PTE_P | PTE_W | PTE_U)) < 0)
panic("pgfault: page allocation failed %e", r);
addr = ROUNDDOWN(addr, PGSIZE);
memmove(PFTEMP, addr, PGSIZE);
if ((r = sys_page_unmap(envid, addr)) < 0)
panic("pgfault: page unmap failed (%e)", r);
if ((r = sys_page_map(envid, PFTEMP, envid, addr, PTE_P | PTE_W |PTE_U)) < 0)
panic("pgfault: page map failed (%e)", r);
if ((r = sys_page_unmap(envid, PFTEMP)) < 0)
panic("pgfault: page unmap failed (%e)", r);
}可以通过
make run-forktree验证结果
ref:https://www.jianshu.com/p/d9b6dcce1c48
Part C: 抢占式多进程处理 & 进程间通信
作为 lab4 的最后一步,我们要修改内核使之能抢占一些不配合的进程占用的资源,以及允许进程之间的通信。
Part I: 时钟中断以及抢占
尝试运行一下 user/spin 测试,该测试建立一个子进程,该子进程获得 CPU 资源后就进入死循环,这样内核以及父进程都无法再次获得 CPU。这显然是操作系统需要避免的。为了允许内核从一个正在运行的进程抢夺 CPU 资源,我们需要支持来自硬件时钟的外部硬件中断。
Interrupt discipline
外部中断用 IRQ(Interrupt Request) 表示。一共有 16 种 IRQ,在 picirq.c中将其增加了 IRQ_OFFSET 的偏移映射到了 IDT。
在 inc/trap.h 中, IRQ_OFFSET 被定义为 32。因此,IDT[32] 包含了时钟中断的处理入口地址。
联想 Lab3 中的内容:
x86 的所有异常可以用中断向量 0
31 表示,对应 IDT 的第 031 项。例如,页错误产生一个中断向量为 14 的异常。大于 32 的中断向量表示的都是中断
相对 xv6,在 JOS 中我们中了一个关键的简化:在内核态时禁用外部设备中断。外部中断使用 %eflag 寄存器的 FL_IF 位控制。当该位置 1 时,开启中断。由于我们的简化,我们只在进入以及离开内核时需要修改这个位。
我们需要确保在用户态时 FL_IF 置 1,使得当有中断发生时,可以被处理。我们在 bootloader 的第一条指令 cli就关闭了中断,然后再也没有开启过。
Exercise 13.
Modify kern/trapentry.S and kern/trap.c to initialize the appropriate entries in the IDT and provide handlers for IRQs 0 through 15. Then modify the code in env_alloc() in kern/env.c to ensure that user environments are always run with interrupts enabled.
比较简单,跟 Lab3 中的 Exercise 4 大同小异。相关的常数定义在 inc/trap.h 中可以找到。
在 kern/trapentry.S 中加入:
1 | // IRQs |
在 kern/trap.c 的 trap_init() 中加入:
1 | // IRQs |
在 kern/env.c 的 env_alloc() 中加入:
1 | // Enable interrupts while in user mode. |
Handling Clock Interrupts
在 user/spin 程序中,子进程开启后就陷入死循环,此后 kernel 无法再获得控制权。我们需要让硬件周期性地产生时钟中断,强制将控制权交给 kernel,使得我们能够切换到其他进程。
Exercise 14.
Modify the kernel’s trap_dispatch() function so that it calls sched_yield() to find and run a different environment whenever a clock interrupt takes place.
直接在 trap_dispatch() 中添加时钟中断的分支即可。
1 | // Handle clock interrupts. Don't forget to acknowledge the |
Part II: 进程间通信(Inter-Process communication)IPC
IPC in JOS
我们将实现两个系统调用:sys_ipc_recv 以及 sys_ipc_try_send ,再将他们封装为两个库函数,ipc_recv 和 ipc_send 以支持通信。
实际上,进程之间发送的信息是由两个部分组成,一个 int32_t,一个页面映射(可选)。
发送和接收消息
进程使用 sys_ipc_recv 来接收消息。该系统调用会将程序挂起,让出 CPU 资源,直到收到消息。在这个时期,任一进程都能给他发送信息,不限于父子进程。
为了发送信息,进程会调用 sys_ipc_try_send,以接收者的进程 id 以及要发送的值为参数。如果接收者已经调用了 sys_ipc_recv ,则成功发送消息并返回0。否则返回 E_IPC_NOT_RECV 表明目标进程并没有接收消息。ipc_send 库函数将会反复执行 sys_ipc_try_send 直到成功。
传递页面
当进程调用 sys_ipc_recv 并提供一个虚拟地址 dstva (必须位于用户空间) 时,进程表示它希望能接收一个页面映射。如果发送者发送一个页面,该页面就会被映射到接收者的 dstva。同时,之前位于 dstva 的页面映射会被覆盖。
当进程调用 sys_ipc_try_send 并提供一个虚拟地址 srcva (必须位于用户空间),表明发送者希望发送位于 srcva的页面给接收者,权限设置为 perm。
在一个成功的 IPC 之后,发送者和接受者将共享一个物理页。
Exercise 15.
Implement sys_ipc_recv and sys_ipc_try_send in kern/syscall.c. Read the comments on both before implementing them, since they have to work together. When you call envid2env in these routines, you should set the checkperm flag to 0, meaning that any environment is allowed to send IPC messages to any other environment, and the kernel does no special permission checking other than verifying that the target envid is valid.
Then implement the ipc_recv and ipc_send functions in lib/ipc.c.
首先需要仔细阅读 inc/env.h 了解用于传递消息的数据结构。
1 | // Lab 4 IPC |
然后需要注意的是通信流程。
- 调用
ipc_recv,设置好 Env 结构体中的相关 field - 调用
ipc_send,它会通过 envid 找到接收进程,并读取 Env 中刚才设置好的 field,进行通信。 - 最后返回实际上是在
ipc_send中设置好 reg_eax,在调用结束,退出内核态时返回。
lib/ipc.c
ipc_recv()
1 | int32_t |
ipc_send
1 | void |
kern/syscall.c
与 sys_page_map() 非常相似,但是其中最大的区别在于,ipc 通信并不限于父子进程之间,而 sys_page_map() 最初设计的作用就是用于 fork()。
sys_ipc_try_send
1 | static int |
1 | static int |