6.828Lab3
LAB3: User Environments
实验三中,you will implement the basic kernel facilities required to get a protected user-mode environment (i.e., “process”) running. 将实现运行受保护的用户模式环境(即进程)所需的基本内核功能。将增强JOS内核以设置数据结构来跟踪 用户环境、创建单个用户环境、将程序映像(program image)加载到其中并开始运行。还需要使得JOS内核能够处理用户环境进行的任何调用和解决它所造成的一切异常情况。
killall XXX杀掉所有的进程 kill xxx(PID)杀死进程号xxx的进程,查看所有运行进程的命令:ps -aux
Part A: User Environment and Expection Handling
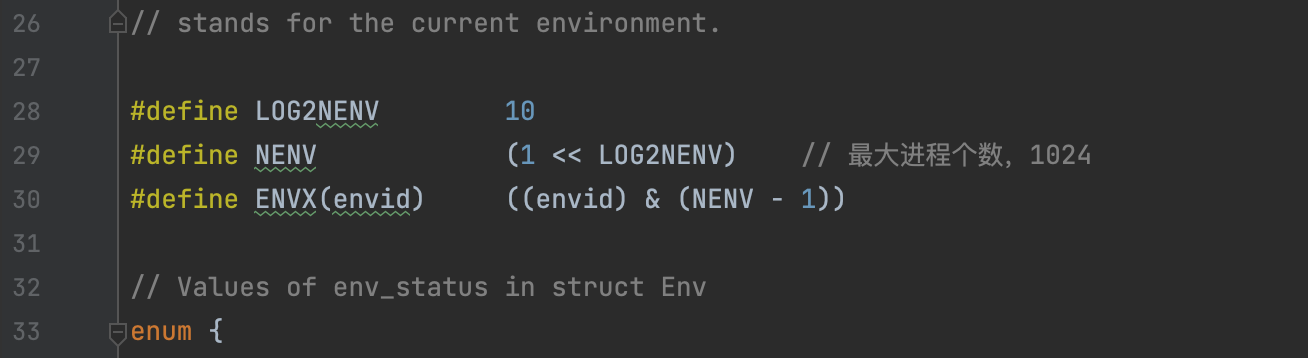
inc/env.h 查看最大进程个数NENV为1024
kern/env.c 全局变量
1 | // env指针指向一个由Env结构体组成的数组,同时,不活动的Env记录在env_free_list 中, 和之前的page_free_list很像 |
inc/enc.h 中查看Env结构体的具体信息
1 | struct Env { |
env_id 进程的身份标识。
env_status 进程的运行状态。
env_link 类似于PageInfo中的pp_link,用于创建空闲进程链表,若进程槽已分配,则置为NULL。
env_tf 是一个Trapframe型的结构体(Trapframe是指中断、自陷、异常进入内核后,在堆栈上形成的一种数据结构),用于登记进程运行时的寄存器信息。
env_pgdir 指向进程运行所用的页目录,即描述了进程的用户地址空间。
在JOS中,进程的运行实体是线程,而env_tf描述的实际上是所说的之行线程。文档中说明:当进程不在运行状态时,env_tf保存了进程的寄存器信息,内核在硬件控制权由用户转到内核时保存这些信息,使得进程可以在之后恢复到它交出控制权时的状态。
Exercise 1: Allocating the Environments Array
修改 kern/pmap.c 中的 mem_init() 来分配和映射 envs 数组。这个数组完全由 ENEV(1024) 个结构体Env组成,与分配 pages 数组的方式非常相似。同时像 pages 数组一样, 在UENVS(定义在inc/memlayout.h)上的用户,内存也该被映射为只读,这样用户进程就可以从这个数组中读取数据。
You should run your code and make sure check_kern_pgdir() succeeds.
1 | void |
Exercise 2: Creating and Running Environments
You will now write the code in kern/env.c necessary to run a user environment. Because we do not yet have a filesystem, we will set up the kernel to load a static binary image that is embedded within the kernel itself. JOS embeds this binary in the kernel as a ELF executable image.
In i386_init() in kern/init.c you’ll see code to run one of these binary images in an environment. However, the critical functions to set up user environments are not complete; you will need to fill them in.
在kern/env.c中,补充完成以下函数
env_init()
初始化 envs 数组中所有的结构体 Env,并把它们添加到env_free_list。
调用 env_init_percpu,它为 privilege level 0(kernel) 和 privilege level 3(user) 配置特定的段。
env_steup_vm()
为新环境分配一个页目录,并且初始化新环境地址空间的内核部分。
region_alloc()
为环境分配和映射物理内存。
load_icode()
您需要解析ELF二进制映像,就像引导加载程序已经做的那样,并将其内容加载到新环境的用户地址空间中。
env_create()
使用env_alloc分配一个环境,并调用load_icode将ELF二进制文件加载到其中。
env_run()
启动以用户模式运行的给定环境。
As you write these functions, you might find the new cprintf verb %e useful – it prints a description corresponding to an error code. For example,
1 | r = -E_NO_MEM; |
will panic with the message “env_alloc: out of memory”.
Below is a call graph of the code up to the point where the user code is invoked. Make sure you understand the purpose of each step.
- start (kern/entry.S)
- i386_init (kern/init.c)
- cons_init
- mem_initenv_init
- trap_init (still incomplete at this point)
- env_create
- env_run
- env_pop_tf
boot.S中通过ljmp跳转指令使cs的索引值指向代码段描述符,并将选择子ds、es、fs、gs和ss的索引值均设置为指向数据段描述符,至此这些段选择子均不曾被更改过。现在我们要创建进程,而原先的GDT中并没有特权级为3的数据段和代码段描述符,所以我们必须加载一个新的GDT。env_init_percpu重新加载了GDT,并设置了各个段选择子。
1 | truct Segdesc gdt[] = |
env_init()
1 | // Set up envs array |
env_steup_vm()
为新环境分配一个页目录,并且初始化新环境地址空间的内核部分。
1 | static int |
region_alloc()
为环境env分配 len 字节的物理内存,并将其映射到环境地址空间中的虚拟地址va。不以任何方式将映射页归零或初始化。页面应该是用户和内核可写的。Panic if any allocation attempt fails.
region_alloc为一个进程分配指定长度的内存空间,并按指定的起始线性地址映射到分配的物理内存上。该函数只在加载用户程序到内存中时(目前通过load_icode)才被用到,分配用户栈的工作将交给load_icode完成。我们会用到lab2中实现的page_alloc和page_insert分别完成物理页的分配与映射。我们不需要对被分配的物理页进行初始化,物理页的权限将被设置为内核和用户都可读写,va和va+len需要设置为页对齐(corner-case应该是当分配的地址超过UTOP时,这里直接panic)。
1 | static void |
load_icode()
由于我们还没有实现文件系统,甚至连磁盘都没有,所以当然不可能从磁盘上加载一个用户程序到内存中。因此,我们暂时将ELF可执行文件嵌入内核,并从内存中加载这样的ELF文件,以此模拟从磁盘加载用户程序的过程。lab3 GNUmakefile负责设置将这样的ELF可执行文件直接嵌入内核
Hint:
在ELF段头指定的地址处把每个程序段加载到虚拟内存中。
你应该只加载 ph->p_type == ELF_PROG_LOAD 的段。
每个段的虚拟地址可以使用 ph->p_va 得到,同时它在内存中的大小可通过ph->memsz得到。
The ph->p_filesz bytes from the ELF binary, starting at binary + ph->p_offset, should be copied to virtual address ph->p_va.
ELF头应该有 ph->p_filesz <= ph->p_memsz.
所有的页面是用户可读/写的。
ELF段不一定是页面对齐的,但是你可以假设这个函数中没有两个段会接触同一个虚拟页面。
您还必须对程序的入口点做一些操作,以确保环境从那里开始执行。
怎么切换页目录?
lcr3([页目录物理地址]) 将地址加载到 cr3 寄存器。
怎么更改函数入口?
将 env->env_tf.tf_eip 设置为 elf->e_entry,等待之后的 env_pop_tf() 调用。
1 | static void |
env_create()
作用是新建一个进程。调用已经写好的 env_alloc() 函数即可,之后更改类型并且利用 load_icode() 读取 ELF。
这里的进程即环境.
1 | // 作用是新建一个进程。 |
env_run()
启动以用户模式运行的给定环境。
//步骤1:如果这是一个上下文切换(一个新的环境正在运行):
/ / 1。设置当前环境(如果有的话)回ENV_RUNNABLE如果它是ENV_RUNNING(想想它可以处于什么其他状态),
/ / 2。将’curenv’设置为新环境,
/ / 3。设置它的状态为ENV_RUNNING,更新env_status
/ / 4。更新它的’env_runs’计数器,
/ / 5。使用lcr3()切换到它的地址空间。
//步骤2:使用env_pop_tf()恢复环境的寄存器,并在环境中进入用户模式。
//Hint: 这个函数从e->env_tf加载新环境的状态。返回前面编写的代码,确保将e->env_tf的相关部分设置为合理的值。
1 | void |
Exercise 3: Handling Interrupts and Exceptions
用户空间中的第一个int $0x30系统调用指令是一个死胡同:一旦处理器进入用户模式,就没有办法返回。现在需要实现基本的异常和系统调用处理,以便内核能够从用户模式代码中恢复对处理器的控制。您应该做的第一件事是彻底熟悉x86中断和异常机制。
Read Chapter 9, Exceptions and Interrupts in the 80386 Programmer’s Manual (or Chapter 5 of the IA-32 Developer’s Manual), if you haven’t already.
根据xv6讲义,一共有三种必须将控制由用户程序转移到内核的情形:系统调用、异常和中断。
系统调用发生在用户程序请求一项操作系统的服务时。
异常发生在用户程序想要执行某种非法的操作时,如除以零或者访问不存在的页表项。
中断发生在某个外部设备需要操作系统的留意时,比如时钟芯片会定时产生一个中断提醒操作系统可以将硬件资源切换给下一个进程使用一会儿了。
在大多数处理器上,这三种情形都是由同一种硬件机制来处理的。对于x86,系统调用和异常本质上也是生成一个中断,因此操作系统只需要提供一套针对中断的处理策略就可以了。
操作系统处理中断时要用到中断描述符表IDT和程序状态段TSS
- 中断描述符表IDT (interrupt descriptor table)
x86最多支持256个不同中断和异常的条目,每个包含一个中断向量,是一个0~255之间的数字,代表中断来源:不同的设备及类型错误。
IDT使得系统调用、异常和中断都只能经由被内核定义的入口进入正确的中断处理程序。每一个中断处理程序都对应一个中断向量或中断号,处理器接收中断号后,会以它作为索引值从IDT中找到对应的中断描述符。接着,处理器从描述符中取出定位中断处理程序要用到的 eip(指令指针寄存器) 和 cs(代码段寄存器) 的值。
EIP中的值指向内核中处理这类异常的代码。 Extend Instruction Pointer
CS中的最低两位表示优先级,因此寻址空间少两位 .
在JOS中,所有异常都在内核模式处理,优先级为0(用户模式为3)
- 任务状态段 (Task State Segment, TSS)
处理器需要保存中断和异常出现时的自身状态,例如EIP和CS,以便处理完后能返回原函数继续执行。但是存储区域必须禁止用户访问,避免恶意代码或bug的破坏。
因此,当x86处理器处理从用户态到内核态的模式转换时,也会切换到内核栈。而TSS指明段选择器和栈地址,处理器将SS, ESP, EFLAGS, CS, EIP压入新栈,然后从IDT读取EIP和CS,根据新栈设置ESP和SS。
SS是堆栈段寄存器。它指向将用于堆栈的内存的一般区域。
ESP是堆栈指针寄存器。它指向在存储器的“堆栈段”区域内的堆栈“顶部”的任何给定点处的精确位置。
EFLAGS标志寄存器。
JOS仅利用TSS来定义需要切换的内核栈。由于内核模式在JOS优先级是0,因此处理器用TSS的ESP0和SS0来定义内核栈,无需TSS结构体中的其他内容。其中,SS0中存储的是GD_KD
#define GD_KD 0x10 // kernel data
ESP0中存储的是KSTACKTOP
1 | #define KSTACKTOP KERNBASE |
在x86体系中,中断向量范围为0-255(vector number),最多表示256个异常或者中断,用一个8位的无符号整数表示,前32个vector为处理器保留用作异常处理。
32-255被指定为用户定义的中断,并且不由处理器保留。这些vector通常分配给外部I/O设备,以便这些设备能够向处理器发送中断。
一个例子
通过一个例子来理解上面的知识。假设处理器正在执行用户环境的代码,遇到了”除0”异常。
处理器切换到内核栈,利用了上文 TSS 中的 ESP0 和 SS0。
处理器将异常参数 push 到了内核栈。一般情况下,按顺序 push
SS, ESP, EFLAGS, CS, EIP
+——————–+ KSTACKTOP
| 0x00000 | old SS | “ - 4
| old ESP | “ - 8
| old EFLAGS | “ - 12
| 0x00000 | old CS | “ - 16
| old EIP | “ - 20 <—- ESP
+——————–+
存储这些寄存器状态的意义是:SS(堆栈选择器) 的低 16 位与 ESP 共同确定当前栈状态;EFLAGS(标志寄存器)存储当前FLAG;CS(代码段寄存器) 和 EIP(指令指针寄存器) 确定了当前即将执行的代码地址,E 代表”扩展”至32位。根据这些信息,就能保证处理中断结束后能够恢复到中断前的状态。因为我们将处理一个”除0”异常,其对应中断向量是0,因此,处理器读取 IDT 的条目0,设置
CS:EIP指向该条目对应的处理函数。处理函数获得程序控制权并且处理该异常。例如,终止进程的运行。

ref:https://www.jianshu.com/p/f67034d0c3f2
嵌套的异常和中断
内核和用户进程都会引起异常和中断。然而,仅在从用户环境进入内核时才会切换栈。如果中断发生时已经在内核态了(此时, CS 寄存器的低 2bit 为 00) ,那么 CPU 就直接将状态压入内核栈,不再需要切换栈。这样,内核就能处理内核自身引起的”嵌套异常”,这是实现保护的重要工具。
如果处理器已经处于内核态,然后发生了嵌套异常,由于它并不进行栈切换,所以无须存储 SS 和 ESP 寄存器状态。对于不包含 error code 的异常,在进入处理函数前内核栈状态如下所示:

对于包含了 error code 的异常,则将 error code 继续 push 到 EIP之后。
警告:如果 CPU 处理嵌套异常的时候,无法将状态 push 到内核栈(由于栈空间不足等原因),则 CPU 无法恢复当前状态,只能重启。当然,这是内核设计中必须避免的。
头文件 inc/trap.h 和 kern/trap.h 包含了与中断和异常相关的定义,需要仔细阅读。其中 kern/trap.h 包含内核私有定义,而 inc/trap.h 包含对内核以及用户进程和库都有用的定义。
每个异常和中断都应该在 trapentry.S 和 trap_init() 有自己的处理函数,并在 IDT 中将这些处理函数的地址初始化。每个处理函数都需要在栈上新建一个 struct Trapframe(见 inc/trap.h),以其地址为参数调用 trap() 函数,然后进行异常处理。

1 | => 0xf0103734 <env_pop_tf+15>: iret |
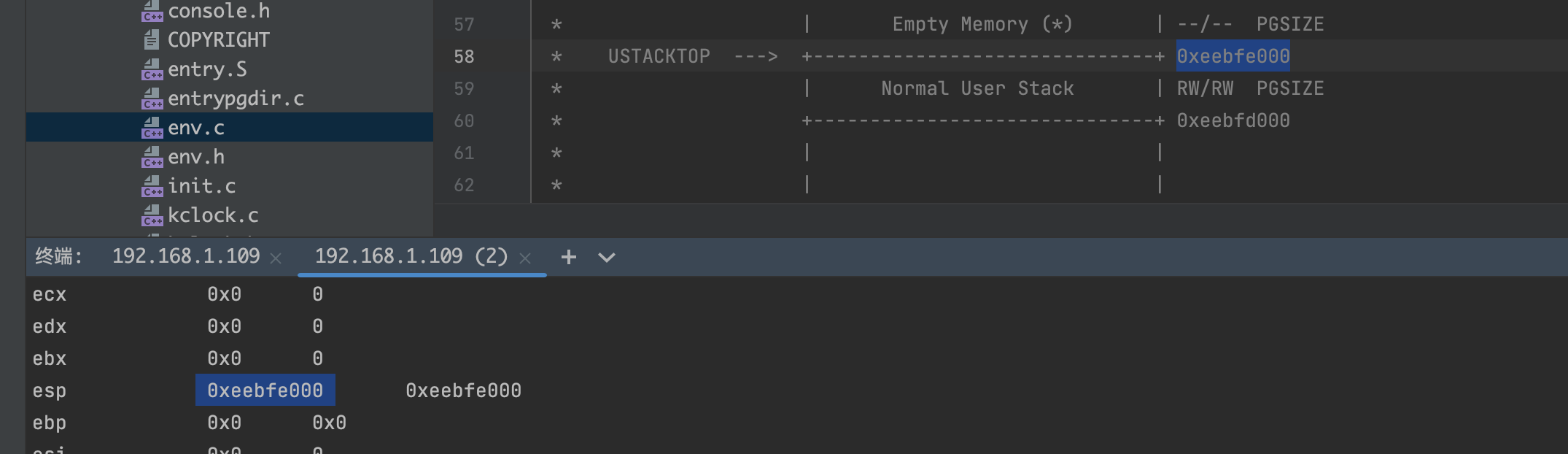
可以看到=> 0x800020: cmp $0xeebfe000,%esp时,进入了用户态,因为cs的值变为了GD_UT | 0X3 = 0x1b,esp的值为USTACKTOP的值0xeebfe000
Exercise 4.
Exercise 4. Edit trapentry.S and trap.c and implement the features described above. The macros TRAPHANDLER and TRAPHANDLER_NOEC in trapentry.S should help you, as well as the T_* defines in inc/trap.h. You will need to add an entry point in trapentry.S (using those macros) for each trap defined in inc/trap.h, and you’ll have to provide _alltraps which the TRAPHANDLER macros refer to. You will also need to modify trap_init() to initialize the idt to point to each of these entry points defined in trapentry.S; the SETGATE macro will be helpful here.
Your _alltraps should:
- push values to make the stack look like a struct Trapframe
- load
GD_KDinto%dsand%es pushl %espto pass a pointer to the Trapframe as an argument to trap()call trap(cantrapever return?)
Consider using the pushal instruction; it fits nicely with the layout of the struct Trapframe.
Test your trap handling code using some of the test programs in the user directory that cause exceptions before making any system calls, such as user/divzero. You should be able to get make grade to succeed on the divzero, softint, and badsegment tests at this point.
查看trapentry.s
1 | /* TRAPHANDLER defines a globally-visible function for handling a trap. |
.global 定义了全局符号。
汇编函数如果需要在其他文件内调用,需要把函数声明为全局,此时就会使用.global这个伪操作。
.type 用来制定一个符号类型是函数类型或者是对象类型,对象类型一般是数据
.type symbol, @object
.type symbol, @function
.align 用来指定内存对齐方式
.align size
表示按size字节对齐内存
这一步做了什么?光看这里很难理解,提示说是构造一个 Trapframe 结构体来保存现场,但是这里怎么直接就 push 中断向量了?实际上,在上文已经指出, cpu 自身会先 push 一部分寄存器(见例子所述),而其他则由用户和操作系统决定。由于中断向量是操作系统定义的,所以从这部分开始就已经不属于 cpu 的工作范畴了。
在 trapentry.S 中:
根据inc/trap.h 绑定
1 | // TRAPHANDLER defines a globally-visible function for handling a trap. |
SETGATE MACRO
Set up a normal interrupt/trap gate descriptor.
1 | // Set up a normal interrupt/trap gate descriptor. |
Challenge! You probably have a lot of very similar code right now, between the lists of TRAPHANDLER in trapentry.S and their installations in trap.c. Clean this up. Change the macros in trapentry.S to automatically generate a table for trap.c to use. Note that you can switch between laying down code and data in the assembler by using the directives .text and .data.
Questions
Answer the following questions in your answers-lab3.txt:
What is the purpose of having an individual handler function for each exception/interrupt? (i.e., if all exceptions/interrupts were delivered to the same handler, what feature that exists in the current implementation could not be provided?)
为每个异常/中断提供单独的处理函数的目的是什么?(也就是说,如果所有异常/中断都被交付给同一个处理程序,当前实现中存在的哪些特性不能提供?)
答:因为每个异常和中断的处理方式不同,例如除0异常不会继续返回程序执行,而I/O操作中断后会继续返回程序处理。一个handler难以处理多种情况。
Did you have to do anything to make the
user/softintprogram behave correctly? The grade script expects it to produce a general protection fault (trap 13), butsoftint‘s code saysint $14. Why should this produce interrupt vector 13? What happens if the kernel actually allowssoftint‘sint $14instruction to invoke the kernel’s page fault handler (which is interrupt vector 14)?
Part B: Page Faults, Breakpoints Exceptions, and System Calls
Exercise5: Handling Page Faults
缺页错误异常,中断向量 14 (T_PGFLT),是一个非常重要的异常类型,lab3 以及 lab4 都强烈依赖于这个异常处理。当程序遇到缺页异常时,它将引起异常的虚拟地址存入 CR2 控制寄存器( control register)。在 trap.c 中,我们已经提供了page_fault_handler() 函数用来处理缺页异常。
修改trap_dispatch(),将页面故障异常分派到page_fault_handler()。现在,您应该能够在faultread、faultreadkernel、faultwrite和faultwritekernel测试中获得成功。如果其中任何一个不工作,找出原因并解决它们。记住,您可以使用make run-x或make run-x-nox将JOS引导到特定的用户程序中。例如,make run-hello-nox运行hello用户程序。
1 | static void |
Exercise 6: The Breakpoint Exception
断点异常,中断向量 3 (T_BRKPT) 允许调试器给程序加上断点。原理是暂时把程序中的某个指令替换为一个 1 字节大小的 int3软件中断指令。在 JOS 中,我们将它实现为一个伪系统调用。这样,任何程序(不限于调试器)都能使用断点功能。
Modify trap_dispatch() to make breakpoint exceptions invoke the kernel monitor. You should now be able to get make grade to succeed on the breakpoint test.
1 | static void |
Challenge! Modify the JOS kernel monitor so that you can ‘continue’ execution from the current location (e.g., after the int3, if the kernel monitor was invoked via the breakpoint exception), and so that you can single-step one instruction at a time. You will need to understand certain bits of the EFLAGS register in order to implement single-stepping.
Optional: If you’re feeling really adventurous, find some x86 disassembler source code - e.g., by ripping it out of QEMU, or out of GNU binutils, or just write it yourself - and extend the JOS kernel monitor to be able to disassemble and display instructions as you are stepping through them. Combined with the symbol table loading from lab 1, this is the stuff of which real kernel debuggers are made.
Questions
The break point test case will either generate a break point exception or a general protection fault depending on how you initialized the break point entry in the IDT (i.e., your call to
SETGATEfromtrap_init). Why? How do you need to set it up in order to get the breakpoint exception to work as specified above and what incorrect setup would cause it to trigger a general protection fault?断点测试用例将生成断点异常或一般保护故障,这取决于您在IDT中初始化断点条目的方式(即,从trap_init调用SETGATE)。为什么?您需要如何设置它才能使断点异常像上面指定的那样工作?哪些不正确的设置会导致它触发一般的保护故障?
答:权限问题。特权级别是个很重要的点。每个IDT的entries内的中断描述符都为中断处理程序设定了一个DPL(Descriptor Privilege Level)。用户程序的特权级别是3,内核的特权级别是0(可知0级别更高)。如果用户产生的中断/异常需要级别0,那么用户就无权请内核调用这个处理程序,就会产生一个general protection fault,如果是内核发生中断/异常的话,特权级别总是够的
SETGATE(idt[T_BRKPT], 1, GD_KT, brkpt_handler, 3);中如果最后一个参数dpl设为3就会产生一个breakpoint exception,如果设为0就会产生一个general protection fault。这也是由于特权级别影响的。breakpoint test程序的特权级别是3,如果断点异常处理程序特权设为3那就可以是断点异常,如果设为0就产生保护错误。What do you think is the point of these mechanisms, particularly in light of what the
user/softinttest program does?里面是这条代码
asm volatile("int $14");本来想中断调用页面错误处理,结果因为特权级别不够而产生一个保护异常,所以重点应该是要分清特权级别吧。要区分$14与$0x30。优先级别低的代码无法访问优先级高的代码,优先级高低由gd_dpl判断。数字越小越高。
Exercise 7: System calls
用户进程通过调用系统调用请求内核为它们做一些事情。当用户进程调用一个系统调用时,处理器进入内核模式,处理器和内核合作保存用户进程的状态,内核执行相应的代码来执行系统调用,然后恢复用户进程。用户进程如何获得内核的注意,以及用户进程如何指定要执行的调用,这些具体细节在不同的系统中有所不同。
在JOS内核中,我们将使用int指令,它会导致处理器中断。特别地,我们将使用int $0x30作为系统调用中断。我们已经为您定义了常量T_SYSCALL到48 (0x30)。您必须设置中断描述符,以允许用户进程引起中断。注意,中断0x30不能由硬件生成,所以不会因为允许用户代码生成它而产生歧义。
应用程序将在寄存器中传递系统调用号和系统调用参数。这样,内核就不需要在用户环境的堆栈或指令流中到处寻找了。系统调用号将进入%eax,参数(最多5个)将分别进入%edx、%ecx、%ebx、%edi和%esi。内核将返回值返回到%eax中。调用系统调用的汇编代码已经为您编写,在lib/syscall.c中的syscall()中。你应该通读一遍,确保你明白发生了什么.
exercise: 在内核中为中断向量T_SYSCALL添加一个处理程序。你必须编辑kern/trapentry。S和kern/trap.c的trap_init()。您还需要更改trap_dispatch()来处理系统调用中断,方法是使用适当的参数调用sycall(在kern/syscall.c中定义),然后将返回值传递回%eax中的用户进程。最后,你需要在kern/syscall.c中实现syscall()。确保如果系统调用号无效,syscall()返回-E_INVAL。您应该阅读并理解lib/syscall.c(特别是内联汇编例程),以确认您对系统调用接口的理解。通过为每个调用调用相应的内核函数来处理inc/syscall.h中列出的所有系统调用。
Run the user/hello program under your kernel (make run-hello). It should print “hello, world” on the console and then cause a page fault in user mode. If this does not happen, it probably means your system call handler isn’t quite right. You should also now be able to get make grade to succeed on the testbss test.
inc/syscall.h
定义了系统调用号
1 |
|
lib/syscall.c
这是系统调用的通用模板,不同的系统调用都会以不同参数调用syscall函数。
1 | // System call stubs. |
补充知识:GCC内联汇编
其语法固定为:asm volatile (“asm code”:output:input:changed);
1 | asm volatile("int %1\n" |
| 限定符 | 意义 |
|---|---|
| “m”、”v”、”o” | 内存单元 |
| “r” | 任何寄存器 |
| “q” | 寄存器eax、ebx、ecx、edx之一 |
| “i”、”h” | 直接操作数 |
| “E”、”F” | 浮点数 |
| “g” | 任意 |
| “a”、”b”、”c”、”d” | 分别表示寄存器eax、ebx、ecx和edx |
| “S”、”D” | 寄存器esi、edi |
| “I” | 常数 (0至31) |
除了这些约束之外, 输出值还包含一个约束修饰符:
| 输出修饰符 | 描述 |
|---|---|
| + | 可以读取和写入操作数 |
| = | 只能写入操作数 |
| % | 如果有必要操作数可以和下一个操作数切换 |
| & | 在内联函数完成之前, 可以删除和重新使用操作数 |
根据表格内容,可以看出该内联汇编作用就是引发一个int中断,中断向量为立即数 T_SYSCALL,同时,对寄存器进行操作。看懂这,就清楚了,这一部分应该不需要我们改动,因为我们处理的是中断已经产生后的部分。当然,还有另一种更简单的思路,inc/ 目录下的,其实都是操作系统留给用户的接口,所以才会在里面看到 stdio.h,assert.h 等文件。那么,要进行系统调用肯定也是先调用 inc/ 中的那个,具体处理应该是在 kern/ 中实现。
ref:https://www.jianshu.com/p/f67034d0c3f2
kern/trap.c
trap_init()添加

权限更改为3,以便用户进程可以触发该中断
修改trap_dispatch()
1 | case T_SYSCALL: |
kern/syscall.c
我们在 kern/trap.c 中调用的实际上就是这里的 syscall 函数,而不是 lib/syscall.c 中的那个。想明白这一点,设置参数也就很简单了,注意返回值的处理。
1 | // Dispatches to the correct kernel function, passing the arguments. |
运行 make grade 可以通过 testbss,运行 make run-hello 可以打印出 hello world,紧接着提示了页错误。

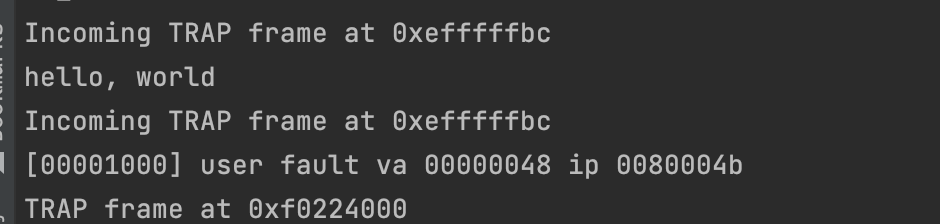
通过 exercise 7,可以看出 JOS系 统调用的步骤为:
- 用户进程使用
inc/目录下暴露的接口 lib/syscall.c中的函数将系统调用号及必要参数传给寄存器,并引起一次int $0x30中断kern/trap.c捕捉到这个中断,并将 TrapFrame 记录的寄存器状态作为参数,调用处理中断的函数kern/syscall.c处理中断
Exercise 8: User-mode startup
一个用户程序开始运行在lib/entry.S的顶部。在一些设置之后,这段代码调用lib/libmain.c中的libmain()。你应该修改libmain()来初始化全局指针thisenv,使其指向envs[]数组中的环境结构体Env。(Note that lib/entry.S has already defined envs to point at the UENVS mapping you set up in Part A.)
Hint: look in inc/env.h and use sys_getenvid.
libmain() then calls umain, which, in the case of the hello program, is in user/hello.c. Note that after printing “hello, world”, it tries to access thisenv->env_id. This is why it faulted earlier.
Now that you’ve initialized thisenv properly, it should not fault. If it still faults, you probably haven’t mapped the UENVS area user-readable (back in Part A in pmap.c; this is the first time we’ve actually used the UENVS area).
Add the required code to the user library, then boot your kernel. You should see user/hello print “hello, world“ and then print “i am environment 00001000“. user/hello then attempts to “exit” by calling sys_env_destroy() (see lib/libmain.c and lib/exit.c). Since the kernel currently only supports one user environment, it should report that it has destroyed the only environment and then drop into the kernel monitor. You should be able to get make grade to succeed on the hello test.
umain.c
user/hello.c
1 | void |
1 | void |

hello 完成
Exercise 9: Page faults and memory protection
内存保护是操作系统的关键功能,它确保了一个程序中的错误不会导致其他程序或是操作系统自身的崩溃。
操作系统通常依赖硬件的支持来实现内存保护。操作系统会告诉硬件哪些虚拟地址可用哪些不可用。当某个程序想访问不可用的内存地址或不具备权限时,处理器将在出错指令处停止程序,然后陷入内核。如果错误可以处理,内核就处理并恢复程序运行,否则无法恢复。
作为可以修复的错误,设想某个自动生长的栈。在许多系统中内核首先分配一个页面给栈,如果某个程序访问了页面外的空间,内核会自动分配更多页面以让程序继续。这样,内核只用分配程序需要的栈内存给它,然而程序感觉仿佛可以拥有任意大的栈内存。
系统调用也为内存保护带来了有趣的问题。许多系统调用接口允许用户传递指针给内核,这些指针指向待读写的用户缓冲区。内核处理系统调用的时候会对这些指针解引用。这样就带来了两个问题:
- 内核的页错误通常比用户进程的页错误严重得多,如果内核在操作自己的数据结构时发生页错误,这就是一个内核bug,会引起系统崩溃。因此,内核需要记住这个错误是来自用户进程。
- 内核比用户进程拥有更高的内存权限,用户进程给内核传递的指针可能指向一个只有内核能够读写的区域,内核必须谨慎避免解引用这类指针,因为这样可能导致内核的私有信息泄露或破坏内核完整性。
我们将对用户进程传给内核的指针做一个检查来解决这两个问题。内核将检查指针指向的是内存中用户空间部分,页表也允许内存操作。
Change kern/trap.c to panic if a page fault happens in kernel mode.
Hint: to determine whether a fault happened in user mode or in kernel mode, check the low bits of the tf_cs. (tf_cs是0x18还是0x1b, 0x18|0x03 = 0x1b此时是用户模式,0x18是内核模式,检查&3后的低2位)
Read user_mem_assert in kern/pmap.c and implement user_mem_check in that same file.
Change kern/syscall.c to sanity check arguments to system calls.
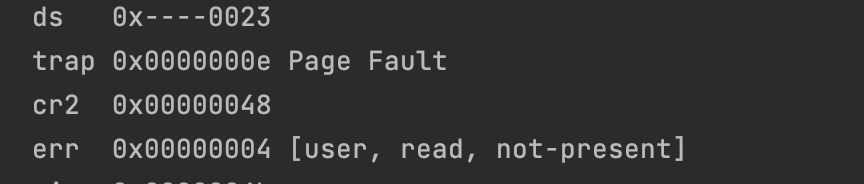
Boot your kernel, running user/buggyhello. The environment should be destroyed, and the kernel should not panic. You should see:
1 | [00001000] user_mem_check assertion failure for va 00000001 |
Finally, change debuginfo_eip in kern/kdebug.c to call user_mem_check on usd, stabs, and stabstr. If you now run user/breakpoint, you should be able to run backtrace from the kernel monitor and see the backtrace traverse into lib/libmain.c before the kernel panics with a page fault. What causes this page fault? You don’t need to fix it, but you should understand why it happens.
kern/trap.c
1 | void |
kern/pmap.c
user_mem_check
1 | // 检查一个环境是否允许访问权限为'perm | PTE_P'的内存范围[va, va+len]。 |
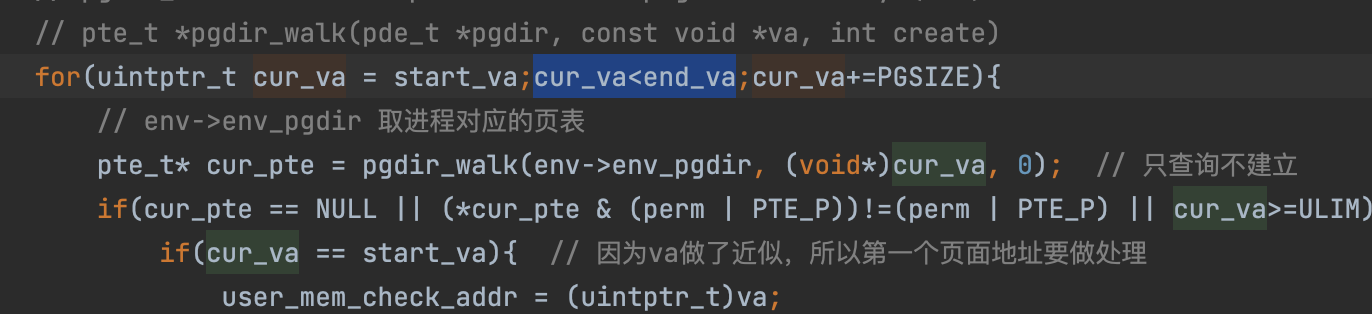
不能写为cur_va<=end_va。会内存越界
user_mem_assert
1 | // |
调用了user_mem_check(),不满足则摧毁页面
运行 make run-buggyhello-nox
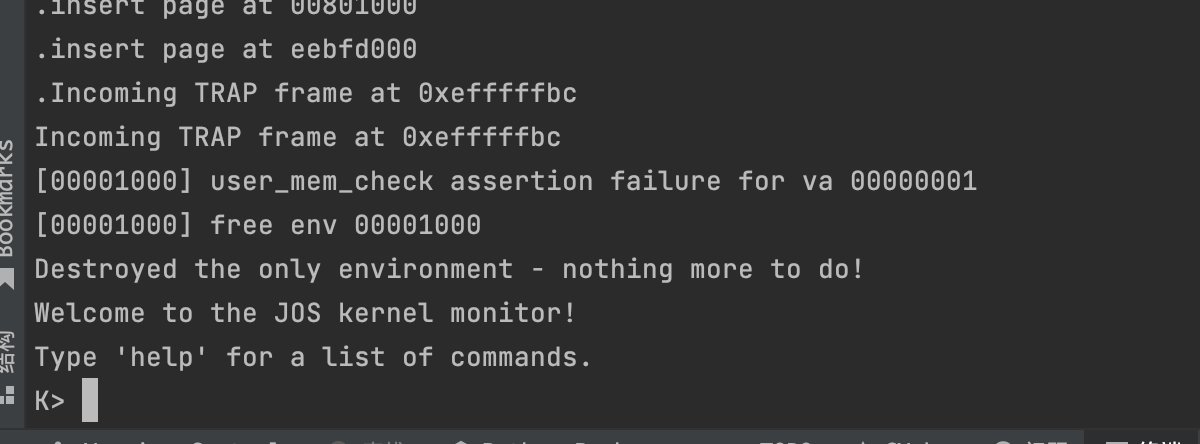
[00001000] user_mem_check assertion failure for va 00000001
[00001000] free env 00001000
Destroyed the only environment - nothing more to do!
最后,change debuginfo_eip in kern/kdebug.c to call user_mem_check on usd, stabs, and stabstr.
1 | // LAB 3: Your code here. |
make run-breakpoint-nox 然后 使用 backtrace
1 | K> backtrace |
可以看到遍历到了:lib/libmain.c:26: libmain+63
ebp(基址指针寄存器)寄存器的内容,efffff10,efffff80,efffffb0都位于内核栈,eebfdfd0位于用户栈。
输入make run-breakpoint-nox-gdb make gdb
把断点打在 monitor()函数处(kern/monitor.c)
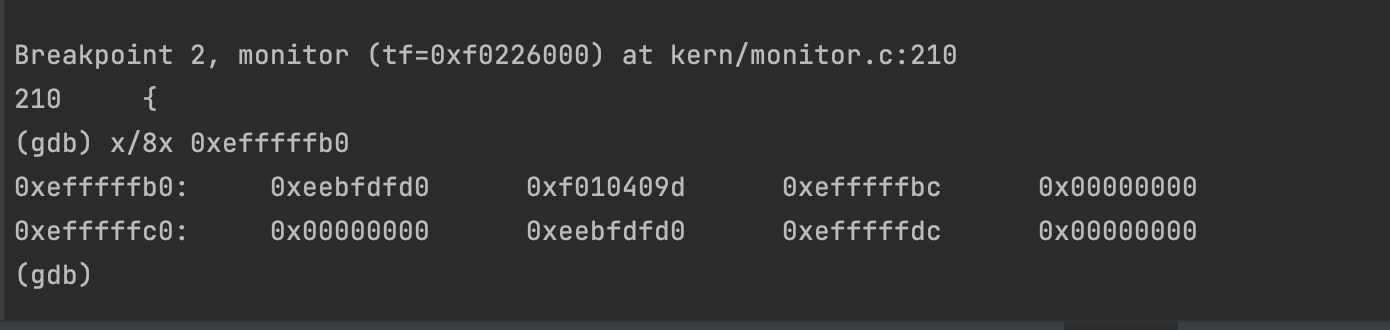
查看ebp的内容
1 | 调用者ebp 返回地址eip 参数1 参数2 |
在查看0xeebfdfd0到用户栈栈顶0xeebfdff0的内容

试图越界访问,可得到

可以看到,最后就只剩了12个字符
这一次,backtrace的打印内容为
ebp eebfdfd0 eip 0080007b args 00000000 00000000 00000000 00000000 00000000
那么下一次为
ebp eebfdff0 eip 00800031 args 00000000 00000000 之后的三个参数全部超过内存访问界限了
现在修改backtrace的函数,输出两个args,backtrace位于kern/monitor.c