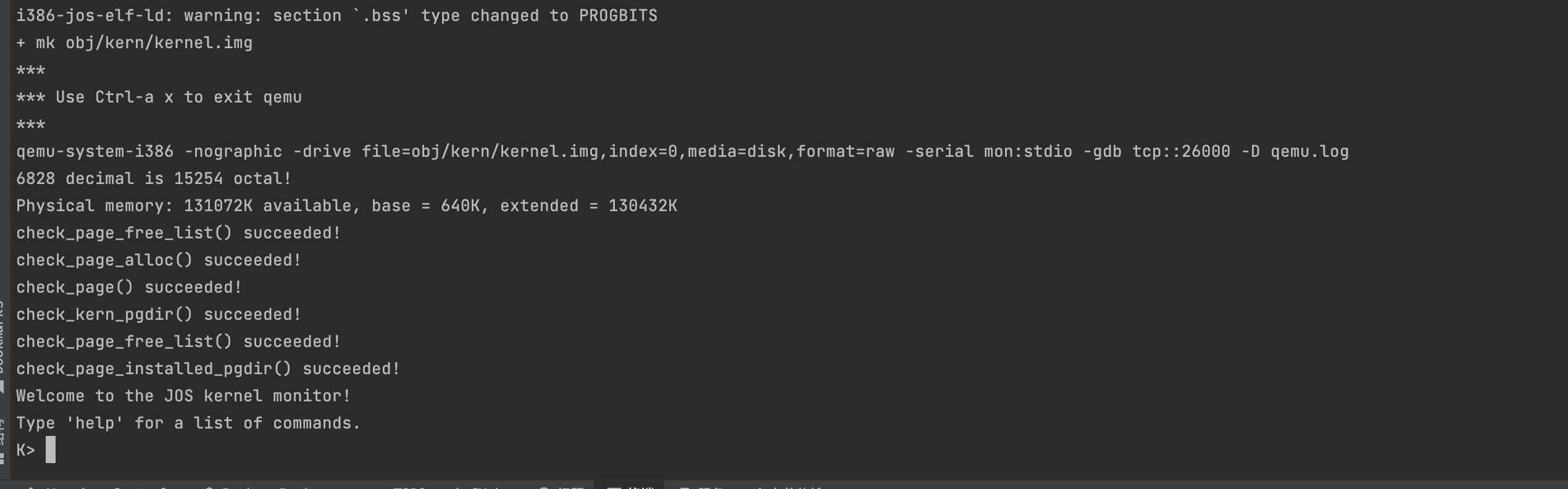
kclock.c and kclock.h manipulate the PC’s battery-backed clock and CMOS RAM hardware, in which the BIOS records the amount of physical memory the PC contains, among other things.
staticvoid * boot_alloc(uint32_t n) { staticchar *nextfree; // virtual address of next byte of free memory char *result;
// Initialize nextfree if this is the first time. // 'end' is a magic symbol automatically generated by the linker, // which points to the end of the kernel's bss segment: // the first virtual address that the linker did *not* assign // to any kernel code or global variables. if (!nextfree) { externchar end[]; nextfree = ROUNDUP((char *) end, PGSIZE); }
// Allocate a chunk large enough to hold 'n' bytes, then update // nextfree. Make sure nextfree is kept aligned // to a multiple of PGSIZE. // // LAB 2: Your code here. if (n == 0) { // if n == 0, returns the address of the next free page without allocating anything. return nextfree; } // n > 0 分配足够的连续物理内存页以容纳〞n”个字节。returns a kernel virtual address. result = nextfree; nextfree += ROUNDUP(n, PGSIZE); // Round up to the nearest multiple of PGSIZE return result; }
////////////////////////////////////////////////////////////////////// // Recursively insert PD in itself as a page table, to form // a virtual page table at virtual address UVPT. // (For now, you don't have understand the greater purpose of the // following line.)
// Permissions: kernel R, user R kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P;
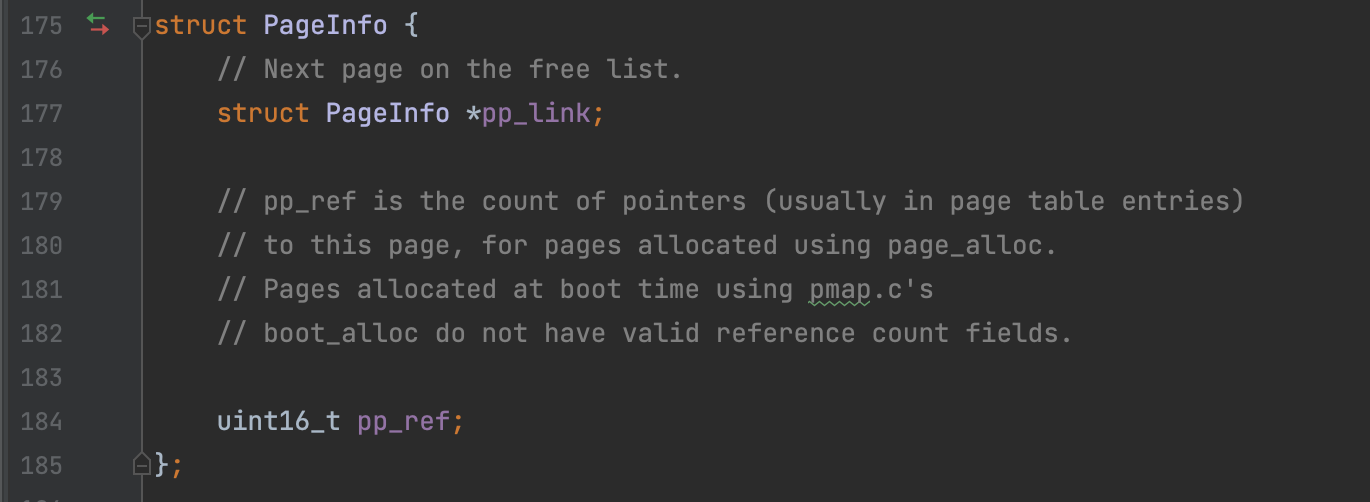
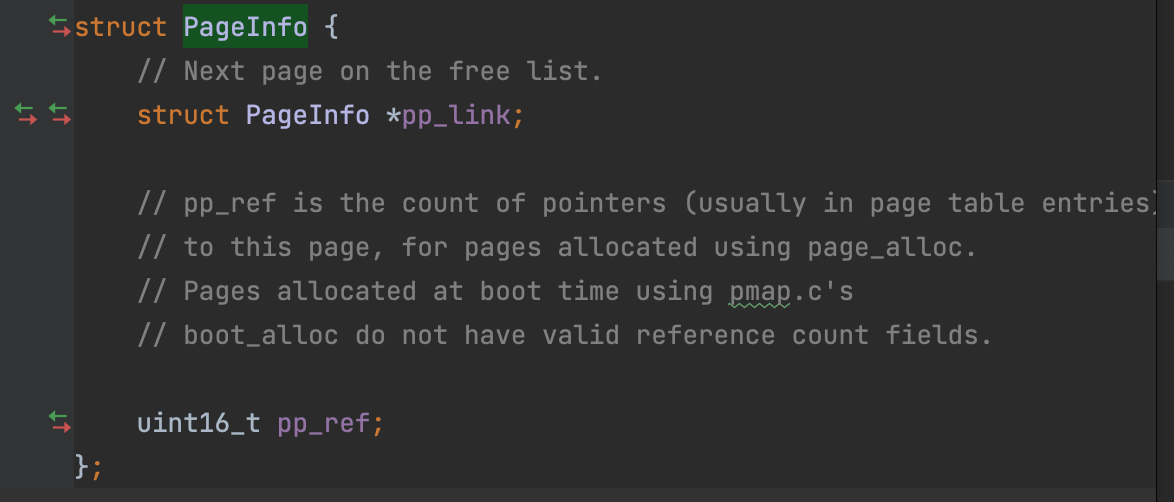
////////////////////////////////////////////////////////////////////// // Allocate an array of npages 'struct PageInfo's and store it in 'pages'. // The kernel uses this array to keep track of physical pages: for // each physical page, there is a corresponding struct PageInfo in this // array. 'npages' is the number of physical pages in memory. Use memset // to initialize all fields of each struct PageInfo to 0. // Your code goes here: // 创建一个struct PageInfo 的数组 // kernel 使用这个数组来耿总每个物理页 // 对于每一个物理页,都会有一个对应的 struct PageInfo 在数组中 pages = (struct PageInfo *) boot_alloc(npages * sizeof(struct PageInfo)); // npages 是内存中物理页的数量 memset(pages, 0, npages * sizeof(struct PageInfo));
////////////////////////////////////////////////////////////////////// // Now that we've allocated the initial kernel data structures, we set // up the list of free physical pages. Once we've done so, all further // memory management will go through the page_* functions. In // particular, we can now map memory using boot_map_region // or page_insert page_init();
////////////////////////////////////////////////////////////////////// // Now we set up virtual memory
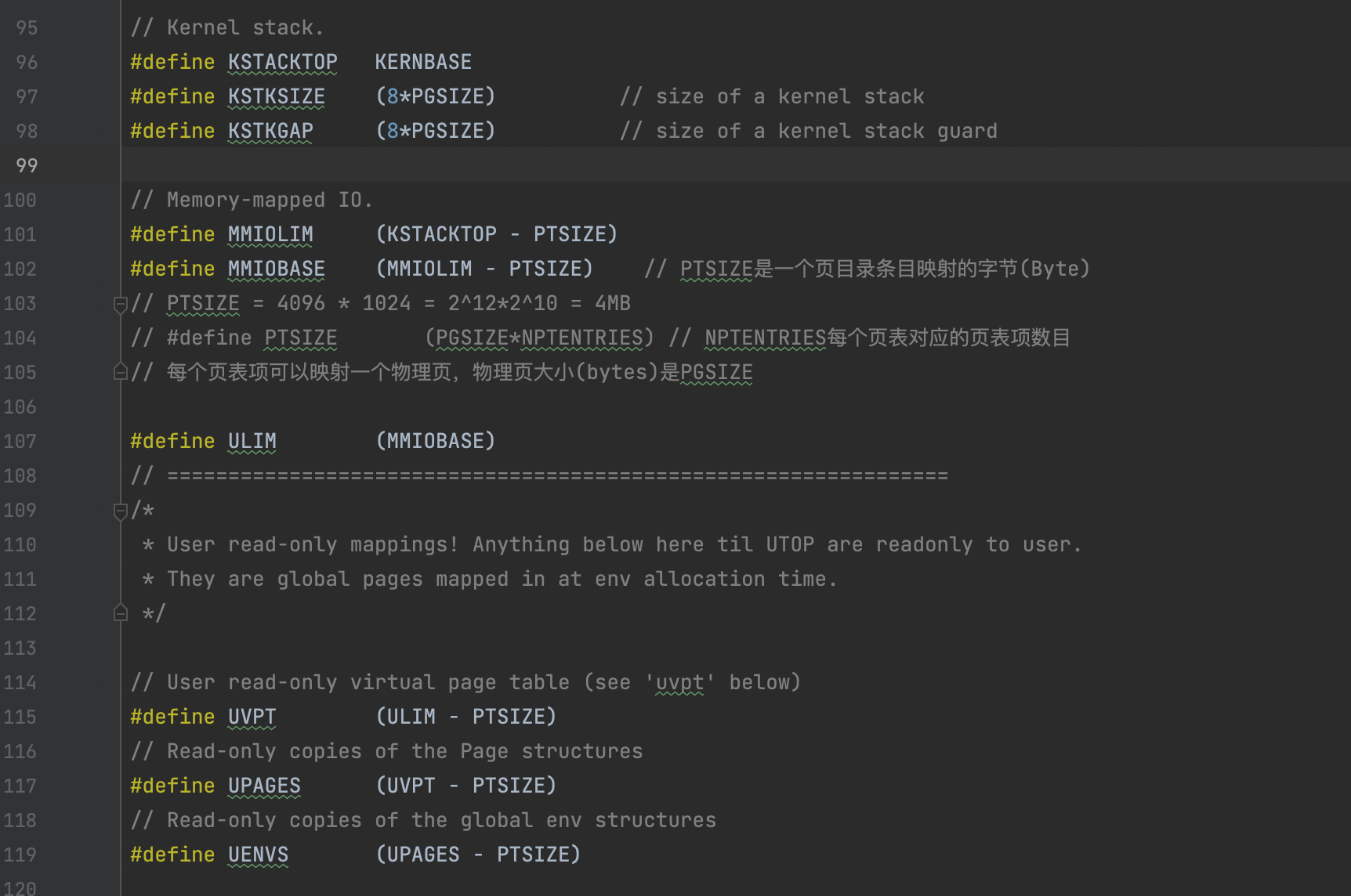
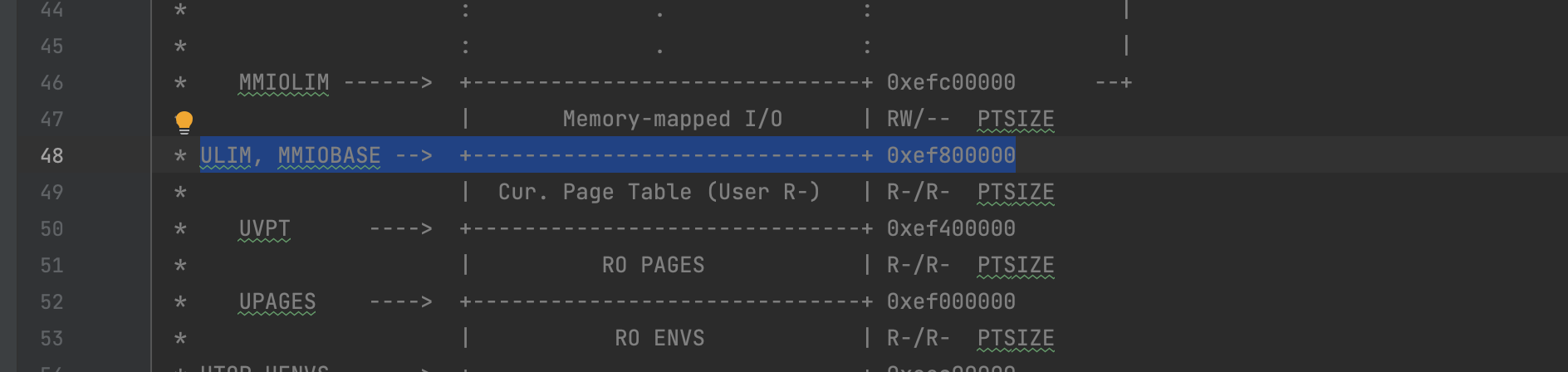
////////////////////////////////////////////////////////////////////// // Map 'pages' read-only by the user at linear address UPAGES // Permissions: // - the new image at UPAGES -- kernel R, user R // (ie. perm = PTE_U | PTE_P) // - pages itself -- kernel RW, user NONE // Your code goes here:
////////////////////////////////////////////////////////////////////// // Use the physical memory that 'bootstack' refers to as the kernel // stack. The kernel stack grows down from virtual address KSTACKTOP. // We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP) // to be the kernel stack, but break this into two pieces: // * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory // * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if // the kernel overflows its stack, it will fault rather than // overwrite memory. Known as a "guard page". // Permissions: kernel RW, user NONE // Your code goes here:
////////////////////////////////////////////////////////////////////// // Map all of physical memory at KERNBASE. // Ie. the VA range [KERNBASE, 2^32) should map to // the PA range [0, 2^32 - KERNBASE) // We might not have 2^32 - KERNBASE bytes of physical memory, but // we just set up the mapping anyway. // Permissions: kernel RW, user NONE // Your code goes here:
// Check that the initial page directory has been set up correctly. check_kern_pgdir();
// Switch from the minimal entry page directory to the full kern_pgdir // page table we just created. Our instruction pointer should be // somewhere between KERNBASE and KERNBASE+4MB right now, which is // mapped the same way by both page tables. // // If the machine reboots at this point, you've probably set up your // kern_pgdir wrong. lcr3(PADDR(kern_pgdir));
check_page_free_list(0);
// entry.S set the really important flags in cr0 (including enabling // paging). Here we configure the rest of the flags that we care about. cr0 = rcr0(); cr0 |= CR0_PE | CR0_PG | CR0_AM | CR0_WP | CR0_NE | CR0_MP; cr0 &= ~(CR0_TS | CR0_EM); lcr0(cr0);
// Some more checks, only possible after kern_pgdir is installed. check_page_installed_pgdir(); }
void page_init(void) { // The example code here marks all physical pages as free. // However this is not truly the case. What memory is free? size_t i; // 1) Mark physical page 0 as in use. // This way we preserve the real-mode IDT and BIOS structures // in case we ever need them. (Currently we don't, but...) // 将页 0 标记为使用状态 pages[0].pp_ref = 1; // 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE) // is free. // 剩下的标为空闲状态 for(i = 1;i<npages_basemem;++i){ pages[i].pp_ref = 0; pages[i].pp_link = page_free_list; page_free_list = &pages[i]; } // 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must // never be allocated. // io端口, 不能被分配 for(i = IOPHYSMEM/PGSIZE;i<EXTPHYSMEM/PGSIZE;++i){ pages[i].pp_ref = 1; }
// 4) Then extended memory [EXTPHYSMEM, ...). // Some of it is in use, some is free. Where is the kernel // in physical memory? Which pages are already in use for // page tables and other data structures? // // Change the code to reflect this. // NB: DO NOT actually touch the physical memory corresponding to // free pages! // 找到第一个能分配的页面 // boot_alloc有个 nextfree指针,但是是虚拟地址,我们要将其转换为物理地址 physical address // PADDR 可以实现地址的转换 size_t first_free_address = PADDR(boot_alloc(0)); // 看看extend physical memory 是不是free for(i = EXTPHYSMEM/PGSIZE;i<first_free_address/PGSIZE;++i){ pages[i].pp_ref = 1; } // 把页面设为空闲,插入链表头部 for (i = first_free_address/PGSIZE; i < npages; i++) { pages[i].pp_ref = 0; pages[i].pp_link = page_free_list; page_free_list = &pages[i]; } }
(This function should only be called when pp->pp_ref reaches 0.)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// Return a page to the free list. // (This function should only be called when pp->pp_ref reaches 0.) // void page_free(struct PageInfo *pp){ // Fill this function in // Hint: You may want to panic if pp->pp_ref is nonzero or // pp->pp_link is not NULL. if(pp->pp_ref>0 || pp->pp_link!=NULL){ panic("Double check failed when dealloc page"); return; } pp->pp_link = page_free_list; // 头插 page_free_list = pp; }
使用 make qemu-nox 运行,发现报了个panic, 需要把panic注释掉。看漏了
Part 2: Virtual Memory
虚拟内存 当 cpu 拿到一个地址并根据地址访问内存时,在 x86架构下药经过至少两级的地址变换:段式变换和页式变换。分段机制的主要目的是将代码段、数据段以及堆栈段分开,保证互不干扰。分页机制则是为了实现虚拟内存。 虚拟内存主要的好处是:
// Given 'pgdir', a pointer to a page directory, pgdir_walk returns // a pointer to the page table entry (PTE) for linear address 'va'. // This requires walking the two-level page table structure. // // The relevant page table page might not exist yet. // If this is true, and create == false, then pgdir_walk returns NULL. // Otherwise, pgdir_walk allocates a new page table page with page_alloc. // - If the allocation fails, pgdir_walk returns NULL. // - Otherwise, the new page's reference count is incremented, // the page is cleared, // and pgdir_walk returns a pointer into the new page table page. // // Hint 1: you can turn a PageInfo * into the physical address of the // page it refers to with page2pa() from kern/pmap.h. // // Hint 2: the x86 MMU checks permission bits in both the page directory // and the page table, so it's safe to leave permissions in the page // directory more permissive than strictly necessary. // // Hint 3: look at inc/mmu.h for useful macros that manipulate page // table and page directory entries. // // typedef uint32_t pte_t; // pgdir_walk returns a pointer to the page table entry (PTE) for linear address 'va'. pte_t * pgdir_walk(pde_t *pgdir, constvoid *va, int create) { // Fill this function in // pgdir 页目录项地址 // va 虚拟地址,jos只有一个段,因此虚拟地址等于线性地址 // create 若页目录项不存在是否创建 // return 页表项指针 uint32_t page_dir_index = PDX(va); uint32_t page_table_index = PTX(va);
Map [va, va+size) of virtual address space to physical [pa, pa+size) in the page table rooted at pgdir. Size is a multiple of PGSIZE, and va and pa are both page-aligned. This function is only intended to set up the ``static'' mappings above UTOP. As such, it should *not* change the pp_ref field on the mapped pages.
// Return the page mapped at virtual address 'va'. // If pte_store is not zero, then we store in it the address // of the pte for this page. This is used by page_remove and // can be used to verify page permissions for syscall arguments, // but should not be used by most callers. // // Return NULL if there is no page mapped at va. // // Hint: the TA solution uses pgdir_walk and pa2page. // // 返回映射到虚拟地址 va 的页面 // pgdir_walk 只查询,不创建,create为0 // pa2page 由物理地址 返回对应的页面描述 struct PageInfo * page_lookup(pde_t *pgdir, void *va, pte_t **pte_store) { // Fill this function in // pdgir 页目录地址 // va 虚拟地址 // pte_store 指向页表指针的指针 the address of the pte for this page // If pte_store is not zero, then we store in it the address of the pte for this page. pde_t* find_pgtab = pgdir_walk(pgdir, va, 0); // 根据va,返回一个指向page table entry的指针 if(!find_pgtab){ // 没找到 returnNULL; } // 找到了 // 再找page table的虚拟地址 if(pte_store){ *pte_store = find_pgtab; // 保存下 } // 返回页面描述 struct PageInfo * return pa2page(PTE_ADDR(*find_pgtab)); // PTE_ADDR 将页表指针指向的内容转为物理地址 }
// // Unmaps the physical page at virtual address 'va'. // If there is no physical page at that address, silently does nothing. // // Details: // - The ref count on the physical page should decrement. // - The physical page should be freed if the refcount reaches 0. // - The pg table entry corresponding to 'va' should be set to 0. // (if such a PTE exists) // - The TLB must be invalidated if you remove an entry from // the page table. // // Hint: The TA solution is implemented using page_lookup, // tlb_invalidate, and page_decref. // // 移除一个虚拟地址与对应物理地址的映射关系 void page_remove(pde_t *pgdir, void *va) { // Fill this function in // pgdir 页目录地址 // va 虚拟地址 // 首先要找到 va对应的物理地址, 使用 page_lookup // page_lookup(pde_t *pgdir, void *va, pte_t **pte_store) pte_t* pgtab; pte_t** pte_store = &pgtab; structPageInfo* pInfo = page_lookup(pgdir, va, pte_store); if(!pInfo){ // 空的 return; } page_decref(pInfo); // 减少页上的引用计数,如果没有引用则释放该计数。 *pgtab = 0; // tlb_invalidate(pde_t *pgdir, void *va) tlb_invalidate(pgdir, va); // 使TLB条目无效,但前提是正在编辑的页表是当前处理器正在使用的页表。 }
page_insert()
建立一个虚拟地址与物理页的映射,与page_remove() 对应。
The permissions (the low 12 bits) of the page table entry should be set to ‘perm|PTE_P’.
// // Map [va, va+size) of virtual address space to physical [pa, pa+size) // in the page table rooted at pgdir. Size is a multiple of PGSIZE, and // va and pa are both page-aligned. // Use permission bits perm|PTE_P for the entries. // // This function is only intended to set up the ``static'' mappings // above UTOP. As such, it should *not* change the pp_ref field on the // mapped pages. // // Hint: the TA solution uses pgdir_walk // 映射一片虚拟页到指定物理页,大小为size, size是PGSIZE的倍数 // va -> pa staticvoid boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm) { // Fill this function in // *pgdir 页目录指针 // va 虚拟地址 // size size是PGSIZE的倍数, // pa 物理地址 // perm 权限 // 直接使用页数来分配,避免溢出 pte_t* pgtab; size_t pg_count = PGNUM(size); // size能分成多少页 // pte_t* pgdir_walk(pde_t *pgdir, const void *va, int create) for(size_t i = 0;i<pg_count;++i){ pgtab = pgdir_walk(pgdir, (void*)va, 1); // pgdir_walk returns a pointer to the page table entry (PTE) for linear address 'va'. *pgtab = pa | perm | PTE_P; // 权限 va+=PGSIZE; pa+=PGSIZE; }
////////////////////////////////////////////////////////////////////// // Map 'pages' read-only by the user at linear address UPAGES // Permissions: // - the new image at UPAGES -- kernel R, user R // (ie. perm = PTE_U | PTE_P) // - pages itself -- kernel RW, user NONE // Your code goes here: // UPAGES是JOS记录物理页面使用情况的数据结构,只有kernel能够访问 // 但是现在需要让用户空间能够读取这段线性地址,因此需要建立映射,将用户空间的一块内存映射到存储该数据结构的物理地址上 // boot_map_region() 建立映射关系 boot_map_region(kern_pgdir, (uintptr_t)UPAGES, npages*sizeof(struct PageInfo), PADDR(pages), PTE_U | PTE_P); // 目前建立了一个页目录,kernel_pgdir // pgdir为页目录指针, UPAGES为虚拟地址,npages*sizeof(struct* PageInfo)为映射的内存块大小 // PADDR(pages) 为物理地址, PTE_U | PTE为权限 (PTE_U 表示用户可读)
////////////////////////////////////////////////////////////////////// // Use the physical memory that 'bootstack' refers to as the kernel // stack. The kernel stack grows down from virtual address KSTACKTOP. // We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP) // to be the kernel stack, but break this into two pieces: // * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory // * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if // the kernel overflows its stack, it will fault rather than // overwrite memory. Known as a "guard page". // Permissions: kernel RW, user NONE // Your code goes here: // kernel 内核栈 // kernel stack 从虚拟地址 KSTACKTOP 开始,向低地址增长,所以KSTACKTOP实际上是栈顶 // KSTACKTOP = 0xf0000000, // KSTKSIZE = (8*PGSIZE) = 8*4096(bytes) = 32KB // 只需要映射 [KSTACKTOP, KSTACKTOP - KSTKSIZE) 范围的虚拟地址 boot_map_region(kern_pgdir, (uintptr_t)(KSTACKTOP - KSTKSIZE), KSTKSIZE, PADDR(bootstack), PTE_W | PTE_P); // PTE_W 开启了写权限,但是并未打开 PTE_U, 因此用户没有权限,只有内核有权限
////////////////////////////////////////////////////////////////////// // Map all of physical memory at KERNBASE. // Ie. the VA range [KERNBASE, 2^32) should map to // the PA range [0, 2^32 - KERNBASE) // We might not have 2^32 - KERNBASE bytes of physical memory, but // we just set up the mapping anyway. // Permissions: kernel RW, user NONE // Your code goes here: // 内核部分 // KERNBASE = 0xF0000000, VA大小为 2^32 - KERNBASE // ROUNDUP(a,n) 将a四舍五入到最接近n的倍数 boot_map_region(kern_pgdir, (uintptr_t)KERNBASE, ROUNDUP(0xffffffff - KERNBASE + 1, PGSIZE), 0, PTE_W | PTE_P);
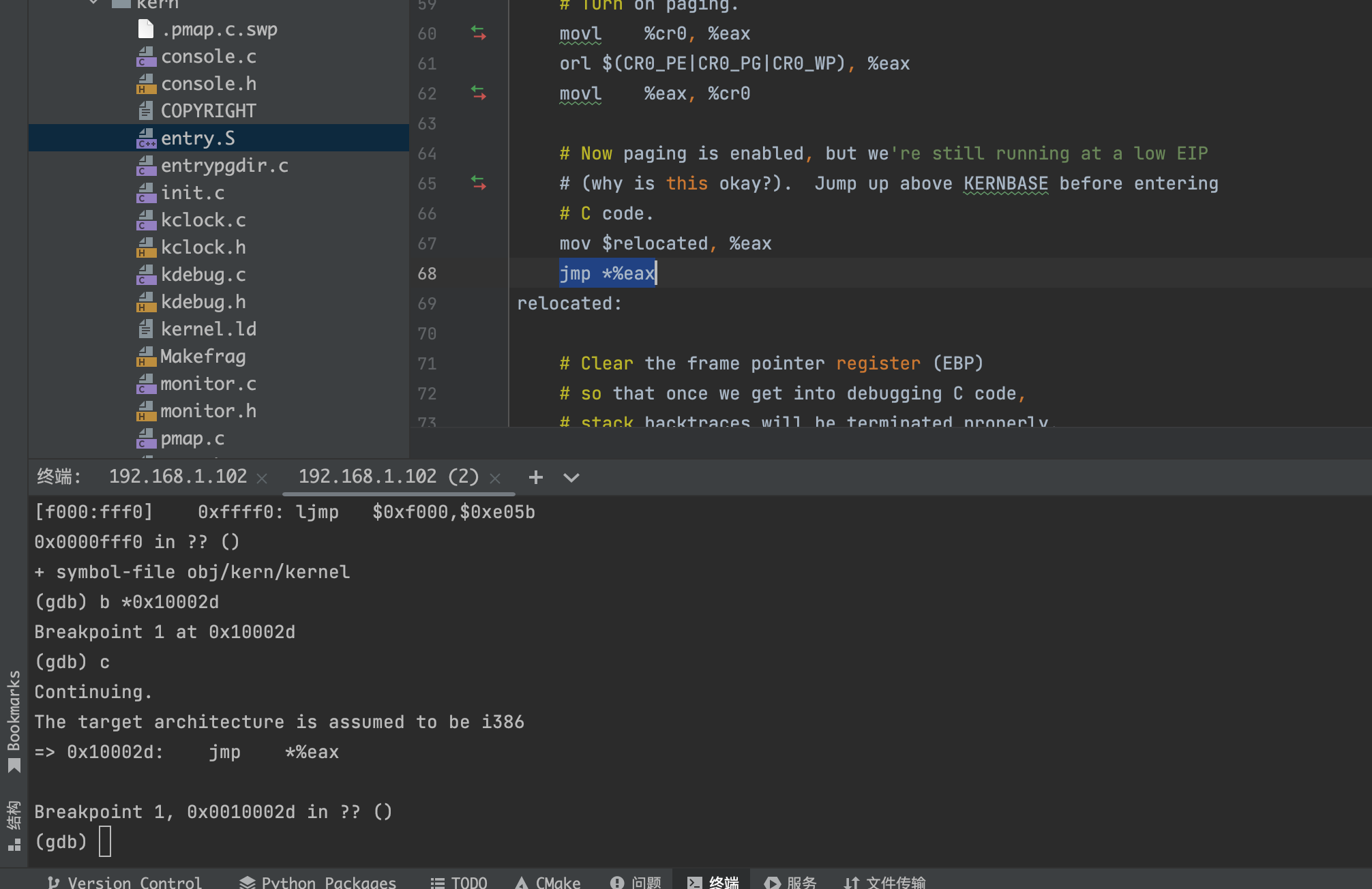
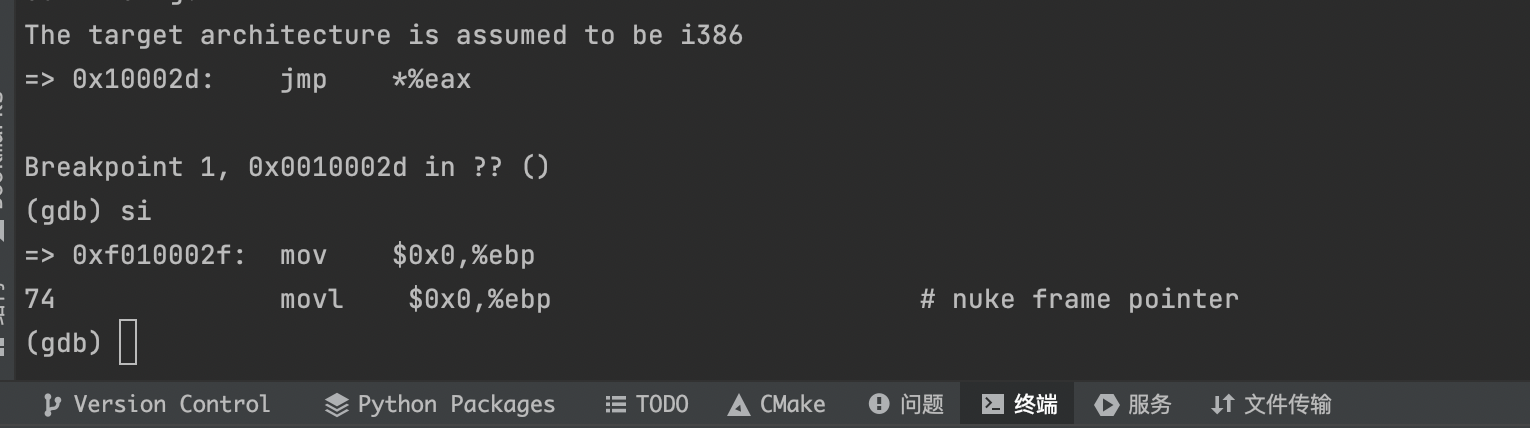
重新访问kern/entry.S和kern/entrypgdir.c中的页面表设置。在我们打开分页后,EIP仍然是一个低数字(略高于1MB)。我们什么时候过渡到KERNBASE上方的EIP运行?when we enable paging and when we begin running at an EIP above KERNBASE,是什么使我们能够继续以低EIP执行?为什么需要这种过渡?
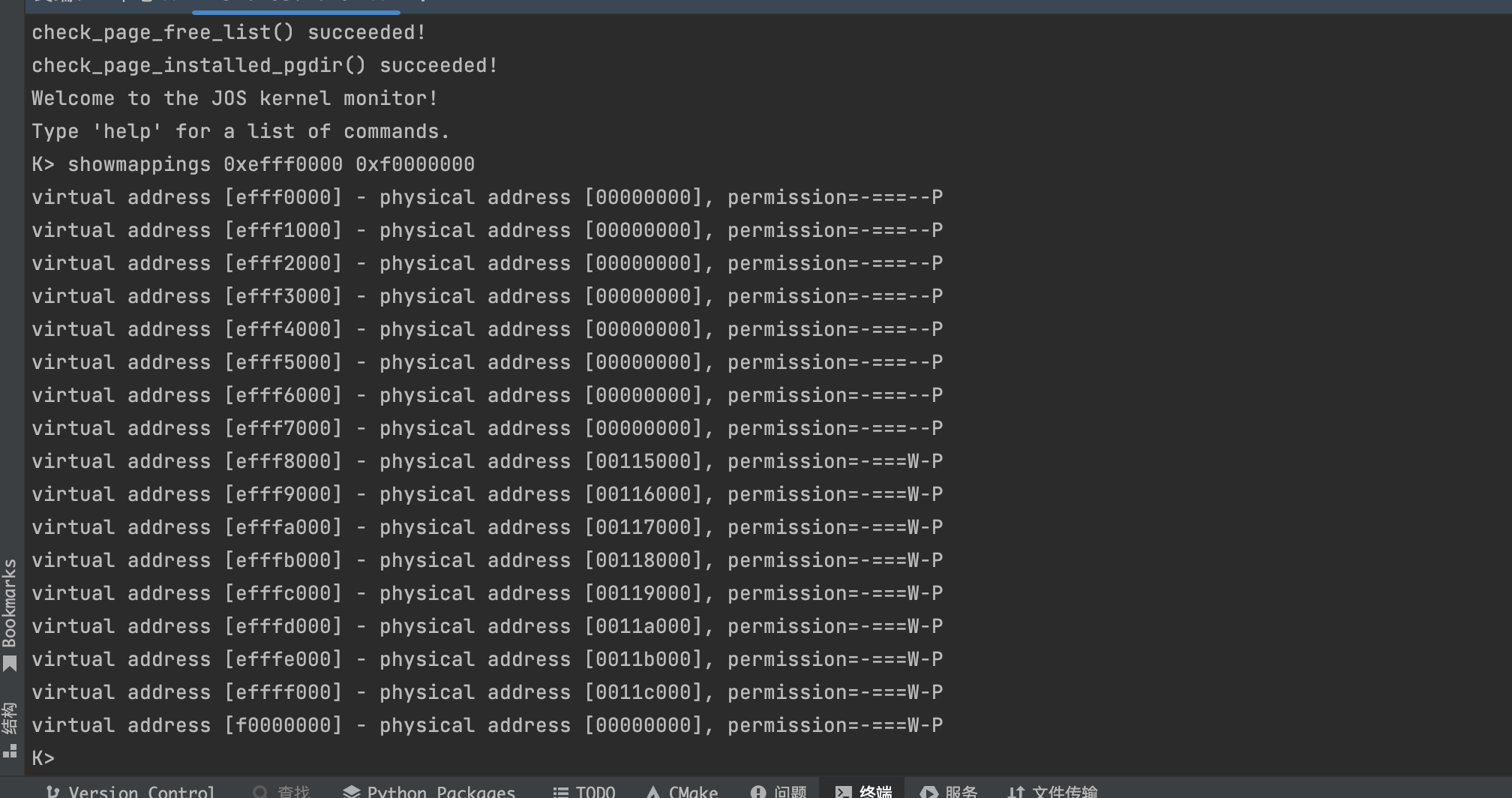
Display in a useful and easy-to-read format all of the physical page mappings (or lack thereof) that apply to a particular range of virtual/linear addresses in the currently active address space. For example, you might enter 'showmappings 0x3000 0x5000' to display the physical page mappings and corresponding permission bits that apply to the pages at virtual addresses 0x3000, 0x4000, and 0x5000.