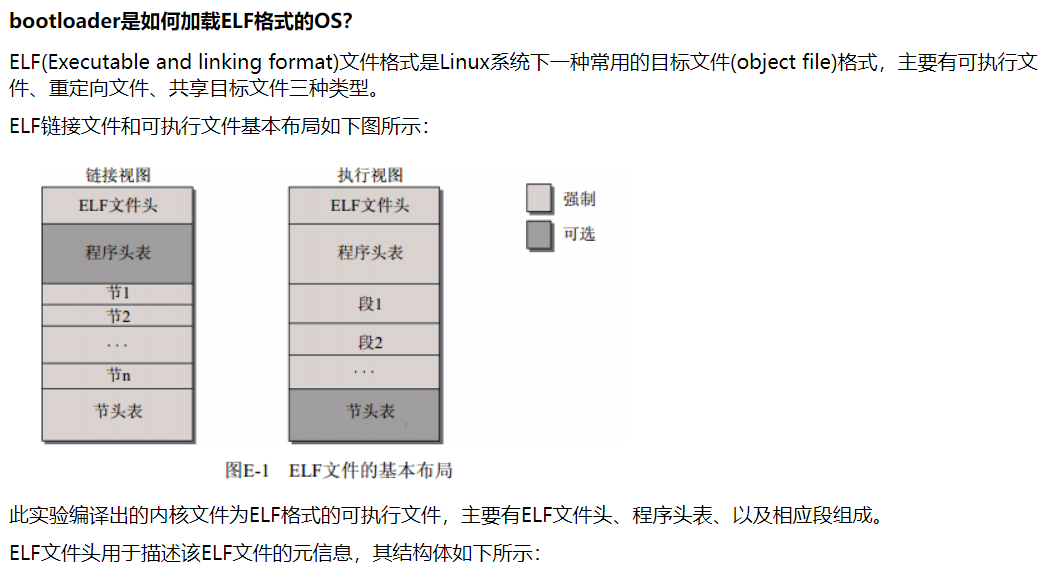
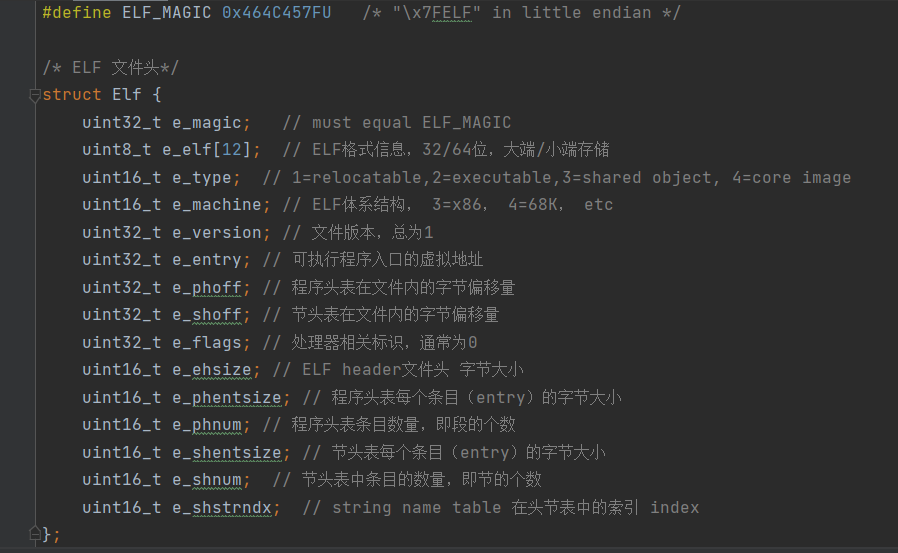
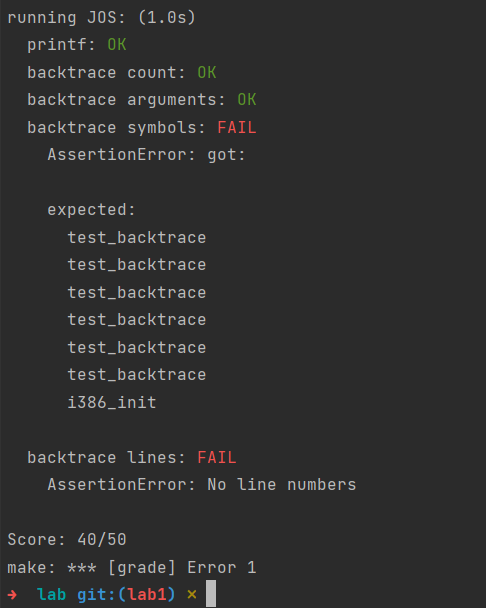
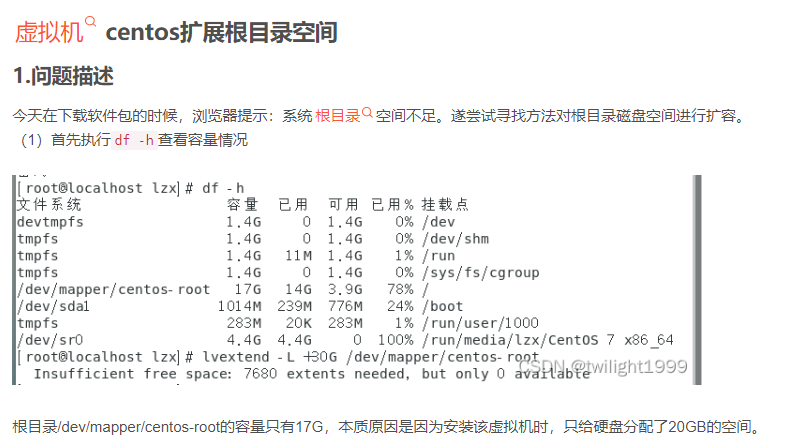
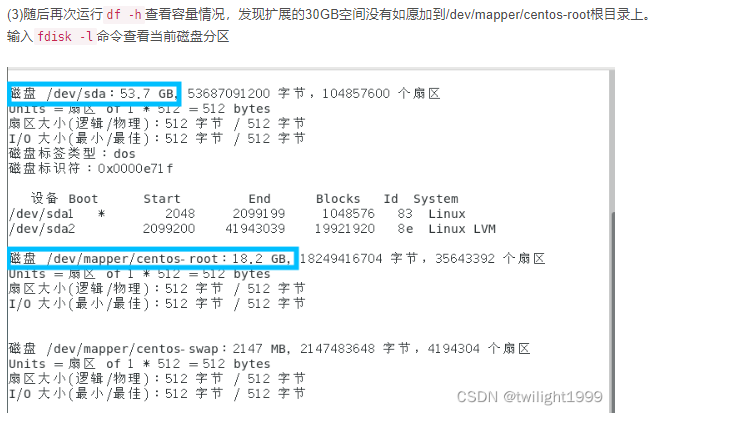
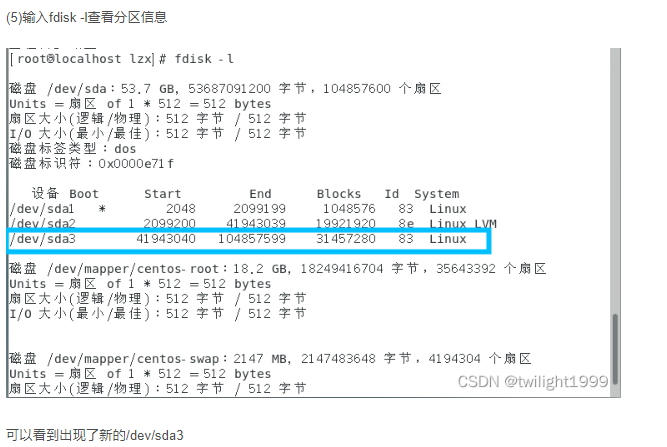
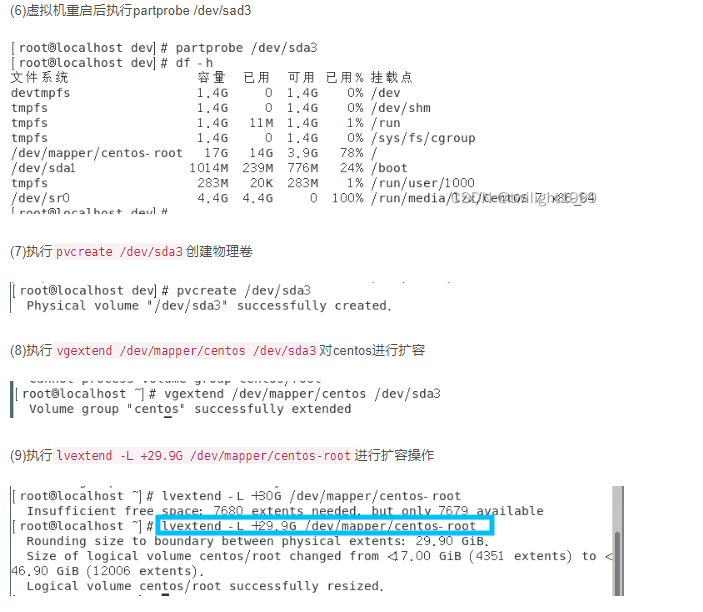
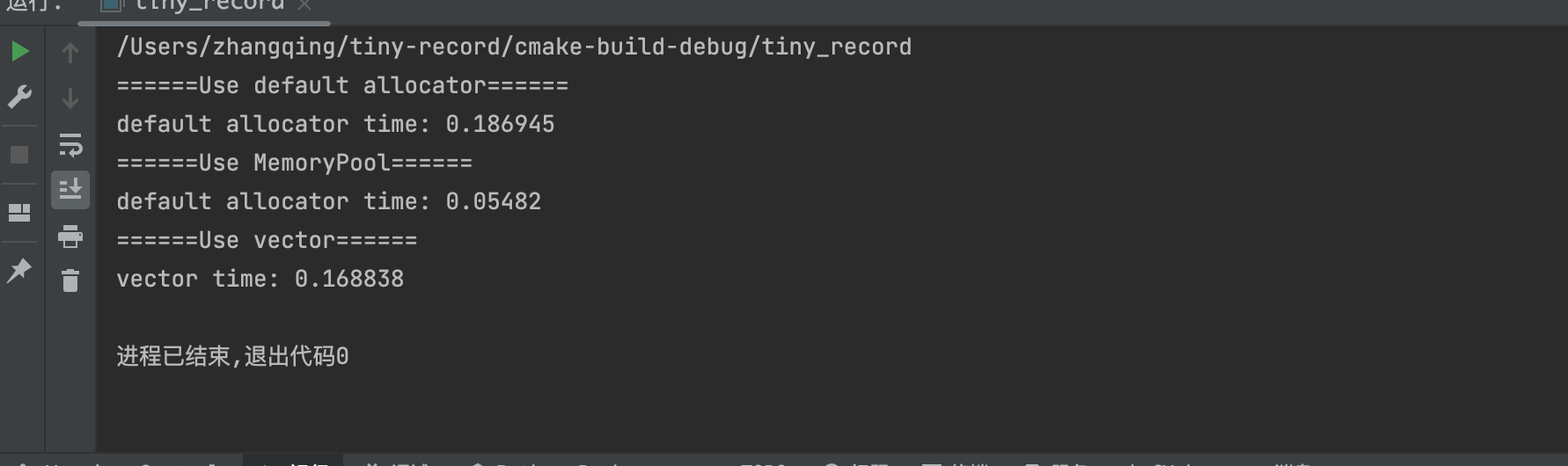
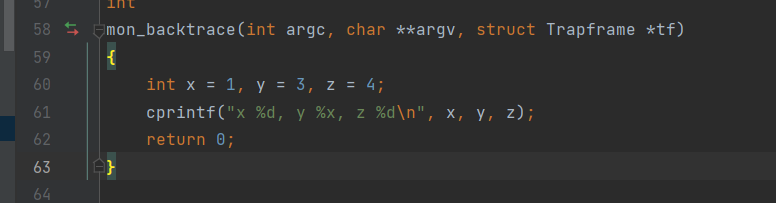一般,使用malloc free和 new delete来动态管理内存,因为牵扯到系统调用,因此效率很低。内存池的思想就是使用很少的系统调用,申请一大块内存自己管理。内存池向系统申请大块内存,然后再分为小片给程序使用,每次请求内存,起始都是在内存池里拿内存而非通过系统调用。(线程池和对象池有着类似的思想)。内存池的优点:
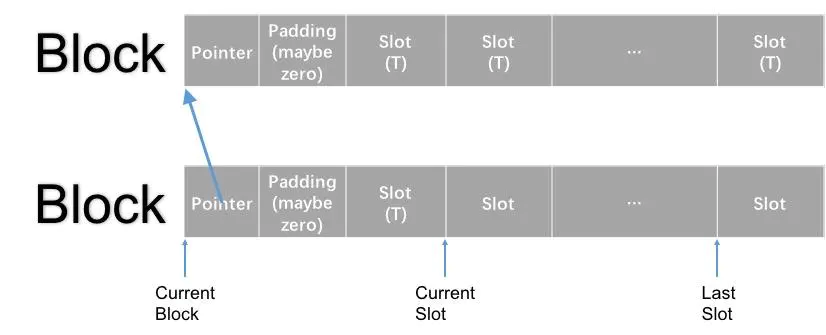
/** 清除所有元素,stack清空 **/ voidclear(){ // T is an object node* cur = head_; while(cur!=0){ node* temp = cur->prev; allocator_.destroy(cur); allocator_.deallocate(cur,1); cur = temp; } head_ = 0; }
/** put an element on the top of the stack*/ // element is an object voidpush(T element){ node* newEle = allocator_.allocate(1); // 分配一个新的Slot_ allocator_.construct(newEle, node()); // inline void construct(U* p, Args&&... args){ newEle->data = element; newEle->prev = head_; head_ = newEle; }
T top(){ return head_->data; } /** 移除顶端元素,返回对象 */ T pop(){ node* cur = head_->prev; T cur_ele = head_->data; allocator_.destroy(head_); allocator_.deallocate(head_,1); head_ = cur; return cur_ele; }
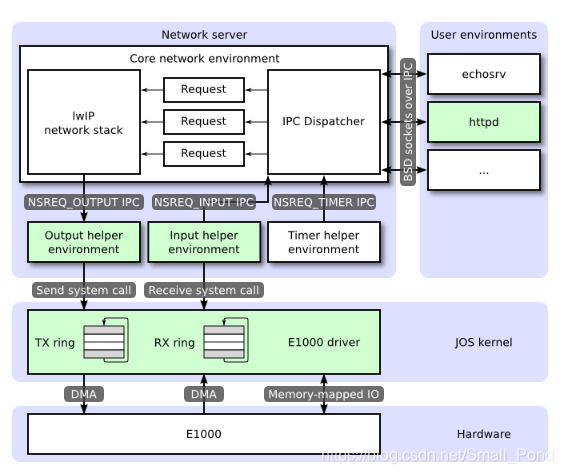
For each user environment IPC, the dispatcher in the network server calls the appropriate BSD socket interface function provided by lwIP on behalf of the user.
Regular user environments do not use the nsipc_* calls directly. Instead, they use the functions in lib/sockets.c, which provides a file descriptor-based sockets API.
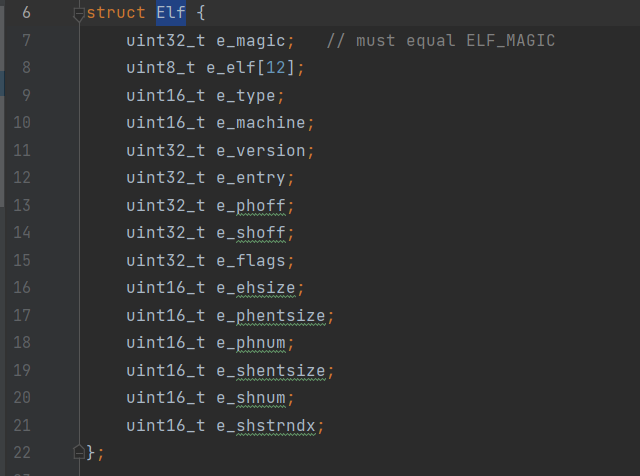
Add a call to time_tick for every clock interrupt in kern/trap.c(in kern/time.c). Implement sys_time_msec and add it to syscall in kern/syscall.c so that user space has access to the time.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// 1 // LAB 4: Your code here. case (IRQ_OFFSET + IRQ_TIMER): // 回应8259A 接收中断。 lapic_eoi(); time_tick(); sched_yield(); break; // 2 staticint sys_time_msec(void) { // LAB 6: Your code here. return time_msec(); // panic("sys_time_msec not implemented"); } // 3 case SYS_time_msec: return sys_time_msec();
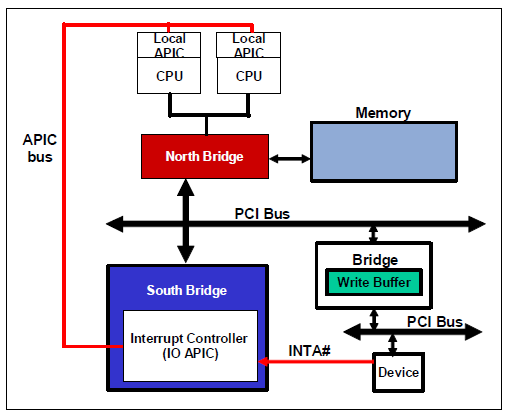
pci_func_enable 为 E1000分配了一个 MMIO 区域并且在 BAR0 中存储了它的 base and size。这是分配给设备的一系列物理内存地址,这意味着我们必须通过虚拟地址访问它。 由于MMIO区域被分配了非常高的物理地址(通常高于3GB),因为JOS的256MB限制,我们无法使用KADDR(内核地址)访问它。所以我们将创建一个新的映射。我们还是使用mmio_map_region分配MMIOBASE以上的区域,其保证了我们不会修改到之前创建的 LAPIC 映射。由于PCI设备初始化发生在JOS创建用户环境之前,因此您可以在kern_pgdir中创建映射,并且它总是可用的。
Exercise 4
In your attach function, create a virtual memory mapping for the E1000’s BAR 0 by calling mmio_map_region (which you wrote in lab 4 to support memory-mapping the LAPIC).
如果用户调用传输系统调用,但下一个描述符的DD位未置位,表明传输队列已满,该怎么办? 你必须决定在这种情况下该做什么。你可以简单地丢弃数据包。网络协议对此具有弹性,但如果丢弃大量数据包,协议可能无法恢复。我们可以告诉用户环境它必须重试,就像我们对sys_ipc_try_send所做的那样。This has the advantage of pushing back on the environment generating the data.。
// LAB 6: Your code here: // - read a packet from the network server // - send the packet to the device driver uint32_t whom; int perm; int32_t req;
while (1) { req = ipc_recv((envid_t *)&whom, &nsipcbuf, &perm); if (req != NSREQ_OUTPUT) { continue; } while (sys_pkt_try_send(nsipcbuf.pkt.jp_data, nsipcbuf.pkt.jp_len) < 0) { sys_yield(); } } }
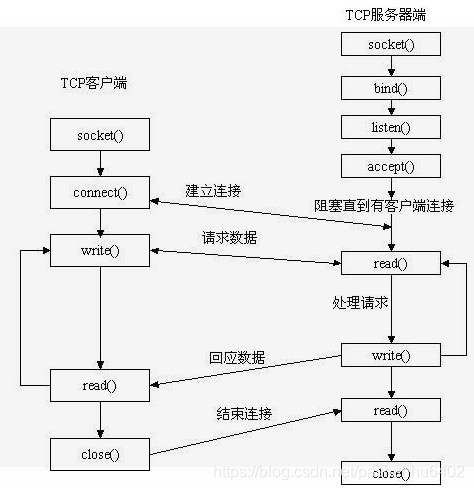
Linux Daemon(守护进程)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。它不需要用户输入就能运行而且提供某种服务,不是对整个系统就是对某个用户程序提供服务。Linux系统的大多数服务器就是通过守护进程实现的。常见的守护进程包括系统日志进程syslogd、 web服务器httpd、邮件服务器sendmail和数据库服务器mysqld等。
In this lab, you will implement spawn, a library call that loads and runs on-disk executables. 然后,您将充实内核和库操作系统,使其足以在控制台上运行shell。这些特性需要一个文件系统,本实验室介绍了一个简单的读写文件系统。
structSuper { uint32_t s_magic; // Magic number: FS_MAGIC uint32_t s_nblocks; // Total number of blocks on disk structFiles_root;// Root directory node };
Superblock, Inode, Dentry 和 File 都属于元数据(Metadata),根据维基百科中的解释,所谓元数据,就是描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。Linux/Unix 文件系统的元数据以多级结构保存。
The layout of the meta-data describing a file in our file system is described by struct File in inc/fs.h. Unlike in most “real” file systems, for simplicity we will use this one File structure to represent file meta-data
1 2 3 4 5 6 7 8 9 10 11 12 13 14
structFile { char f_name[MAXNAMELEN]; // filename off_t f_size; // file size in bytes uint32_t f_type; // file type
// Block pointers. // A block is allocated iff its value is != 0. uint32_t f_direct[NDIRECT]; // direct blocks uint32_t f_indirect; // indirect block
// Pad out to 256 bytes; must do arithmetic in case we're compiling // fsformat on a 64-bit machine. uint8_t f_pad[256 - MAXNAMELEN - 8 - 4*NDIRECT - 4]; } __attribute__((packed)); // required only on some 64-bit machines
Do you have to do anything else to ensure that this I/O privilege setting is saved and restored properly when you subsequently switch from one environment to another? Why?
// Check that the fault was within the block cache region if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE)) panic("page fault in FS: eip %08x, va %08x, err %04x", utf->utf_eip, addr, utf->utf_err);
// Sanity check the block number. if (super && blockno >= super->s_nblocks) panic("reading non-existent block %08x\n", blockno);
// Allocate a page in the disk map region, read the contents // of the block from the disk into that page. // Hint: first round addr to page boundary. fs/ide.c has code to read // the disk. // // LAB 5: you code here: addr = (void*) ROUNDUP(addr, PGSIZE); // Allocate a page of memory and map it at 'addr' with permission 'PTE_P|PTE_W|PTE_U' in the address space of 'envid'. if((r = sys_page_alloc(0,addr,PTE_P|PTE_W|PTE_U))<0){ panic("in bc_pgfault, sys_page_alloc: %e", r); }
// Clear the dirty bit for the disk block page since we just read the // block from disk if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0) panic("in bc_pgfault, sys_page_map: %e", r);
// Check that the block we read was allocated. (exercise for // the reader: why do we do this *after* reading the block // in?) if (bitmap && block_is_free(blockno)) panic("reading free block %08x\n", blockno); }
// Search the bitmap for a free block and allocate it. When you // allocate a block, immediately flush the changed bitmap block // to disk. // // Return block number allocated on success, // -E_NO_DISK if we are out of blocks. // // Hint: use free_block as an example for manipulating the bitmap. int alloc_block(void) { // The bitmap consists of one or more blocks. A single bitmap block // contains the in-use bits for BLKBITSIZE blocks. There are // super->s_nblocks blocks in the disk altogether.
// LAB 5: Your code here. size_t i; for(i = 1; i<super->s_nblocks;++i){ // block_is_free(): Check to see if the block bitmap indicates that block 'blockno' is free. // Return 1 if the block is free, 0 if not. if(block_is_free(i)){ // 没有使用,则标记为已使用 bitmap[i/32] &= ~(1<<(i%32)); flush_block(&bitmap[i/32]); // 写回并重置脏位 return i; } }
//panic("alloc_block not implemented"); return -E_NO_DISK; }
// Find the disk block number slot for the 'filebno'th block in file 'f'. // Set '*ppdiskbno' to point to that slot. // The slot will be one of the f->f_direct[] entries, // or an entry in the indirect block. // When 'alloc' is set, this function will allocate an indirect block // if necessary. // // Returns: // 0 on success (but note that *ppdiskbno might equal 0). // -E_NOT_FOUND if the function needed to allocate an indirect block, but // alloc was 0. // -E_NO_DISK if there's no space on the disk for an indirect block. // -E_INVAL if filebno is out of range (it's >= NDIRECT + NINDIRECT). // // Analogy: This is like pgdir_walk for files. // Hint: Don't forget to clear any block you allocate. staticint file_block_walk(struct File *f, uint32_t filebno, uint32_t **ppdiskbno, bool alloc) { // filenno file block number // LAB 5: Your code here. // panic("file_block_walk not implemented"); // ppdiskbno 块指针 if (filebno < NDIRECT) { // NDIRECT: Number of block pointers in a File descriptor // but note that *ppdiskbno might equal 0 if(ppdiskbno) *ppdiskbno = &(f->f_direct[filebno]); else return0; }
if (filebno >= NDIRECT + NINDIRECT) // NINDIRECT: Number of direct block pointers in an indirect block return -E_INVAL;
// Set *blk to the address in memory where the filebno'th // block of file 'f' would be mapped. // 将*blk设置为文件'f'的第filebno块在内存中的映射地址。 // Returns 0 on success, < 0 on error. Errors are: // -E_NO_DISK if a block needed to be allocated but the disk is full. // -E_INVAL if filebno is out of range. // // Hint: Use file_block_walk and alloc_block. int file_get_block(struct File *f, uint32_t filebno, char **blk) { // LAB 5: Your code here. uint32_t *pdiskbno; // 块的块号指针 int r; if ( (r = file_block_walk(f, filebno, &pdiskbno, 1))< 0) // return r; // 找到文件第filebno块的位置pdiskbno
// Set envid's trap frame to 'tf'. // tf is modified to make sure that user environments always run at code // protection level 3 (CPL 3), interrupts enabled, and IOPL of 0. // // Returns 0 on success, < 0 on error. Errors are: // -E_BAD_ENV if environment envid doesn't currently exist, // or the caller doesn't have permission to change envid. staticint sys_env_set_trapframe(envid_t envid, struct Trapframe *tf) { // LAB 5: Your code here. // Remember to check whether the user has supplied us with a good // address! // panic("sys_env_set_trapframe not implemented"); structEnv *env; int r; if ( (r = envid2env(envid, &env, 1)) < 0) return r;
// Copy the mappings for shared pages into the child address space. staticint copy_shared_pages(envid_t child) { // LAB 5: Your code here. uintptr_t addr; for (addr = 0; addr < UTOP; addr += PGSIZE) { if ((uvpd[PDX(addr)] & PTE_P) && (uvpt[PGNUM(addr)] & PTE_P) && (uvpt[PGNUM(addr)] & PTE_U) && (uvpt[PGNUM(addr)] & PTE_SHARE)) { sys_page_map(0, (void*)addr, child, (void*)addr, (uvpt[PGNUM(addr)] & PTE_SYSCALL)); } } return0; }
The keyboard interface
目前我们只能在内核监视器中才能接收输入。kern/console.c already contains the keyboard and serial drivers that have been used by the kernel monitor since lab 1, but now you need to attach these to the rest of the system.
// poll for any pending input characters, // so that this function works even when interrupts are disabled // (e.g., when called from the kernel monitor). serial_intr(); kbd_intr();
在 trap.c 中加入中断处理函数。
1 2 3 4 5 6 7 8
case (IRQ_OFFSET + IRQ_KBD): lapic_eoi(); kbd_intr(); break; case (IRQ_OFFSET + IRQ_SERIAL): lapic_eoi(); serial_intr(); break;
The Shell
总结
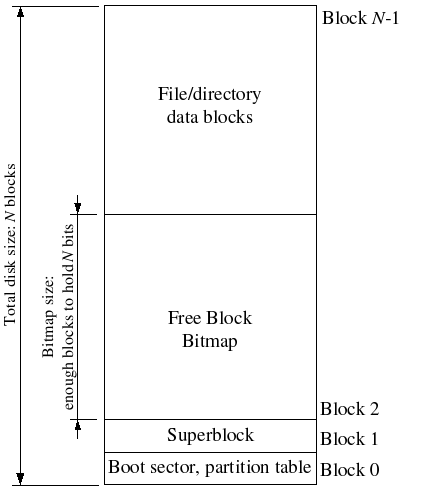
Lab5 主要介绍了文件系统的基本组成,为超级块分配易查找的位置,并在超级块中记录根目录文件,此后递进存储即实现了FS的多级目录。利用虚拟地址和MMIO实现了类似统一编址方式,我们可以很方便实现文件访问,其操作过程与内存访问很类似(在文件结构体中 walk 到块号)。
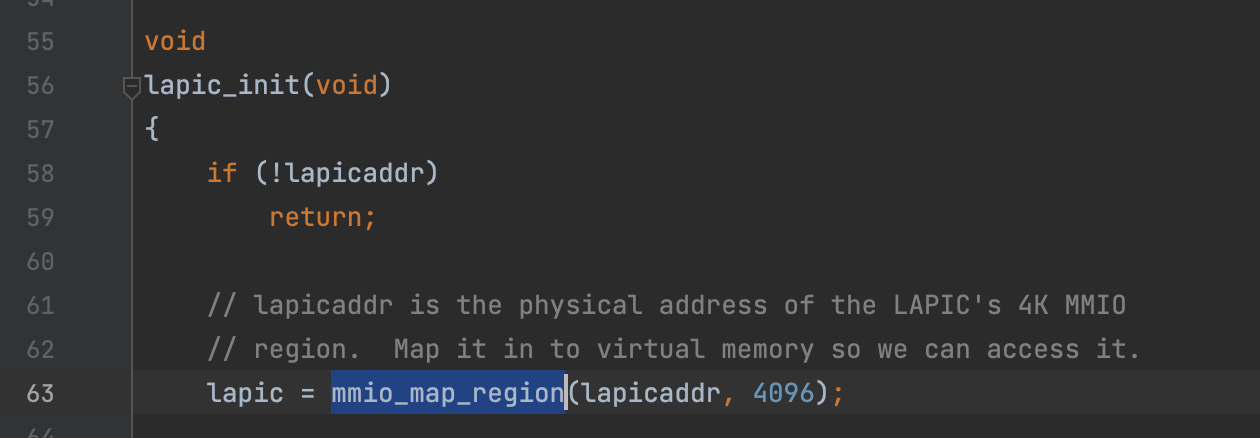
Implement mmio_map_region in kern/pmap.c. To see how this is used, look at the beginning of lapic_init in kern/lapic.c. You’ll have to do the next exercise, too, before the tests for mmio_map_region will run.
*void mmio_map_region(physaddr_t pa, size_t size)
1 2 3
Reserve size bytes in the MMIO region and map [pa,pa+size) at this location. Return the base of the reserved region. 在MMIO区域保留大小为size字节的区域,然后把[pa, pa+size]映射到此区域,返回该区域的base.
void * mmio_map_region(physaddr_t pa, size_t size) { // Where to start the next region. Initially, this is the // beginning of the MMIO region. Because this is static, its // value will be preserved between calls to mmio_map_region // (just like nextfree in boot_alloc). staticuintptr_t base = MMIOBASE;
// Hint: The staff solution uses boot_map_region. // // Your code here: // panic("mmio_map_region not implemented"); // 取整页数 size_t roundup_sz = ROUNDUP(size, PGSIZE); if(base+roundup_sz > MMIOLIM){ panic("mmio_map_region: out of MMIOLIM."); } boot_map_region(kern_pgdir, base, roundup_sz, pa, PTE_PCD|PTE_PWT|PTE_W); uintptr_t res_region_base = base; base += roundup_sz; return (void*)res_region_base; }
在启动 APs 之前,BSP 需要先搜集多处理器系统的信息,例如 CPU 的总数,CPU 各自的 APIC ID,LAPIC 单元的 MMIO 地址。kern/mpconfig.c 中的 mp_init() 函数通过阅读 BIOS 区域内存中的 MP 配置表来获取这些信息。 boot_aps() 函数驱动了 AP 的引导。APs 从实模式开始,如同 boot/boot.S 中 bootloader 的启动过程。因此 boot_aps() 将 AP 的入口代码 (kern/mpentry.S) 拷贝到实模式可以寻址的内存区域 (0x7000, MPENTRY_PADDR)。 此后,boot_aps() 通过发送 STARTUP 这个跨处理器中断到各 LAPIC 单元的方式,逐个激活 APs。激活方式为:初始化 AP 的 CS:IP 值使其从入口代码执行。通过一些简单的设置,AP 开启分页进入保护模式,然后调用 C 语言编写的 mp_main()。boot_aps() 等待 AP 发送 CPU_STARTED 信号,然后再唤醒下一个。
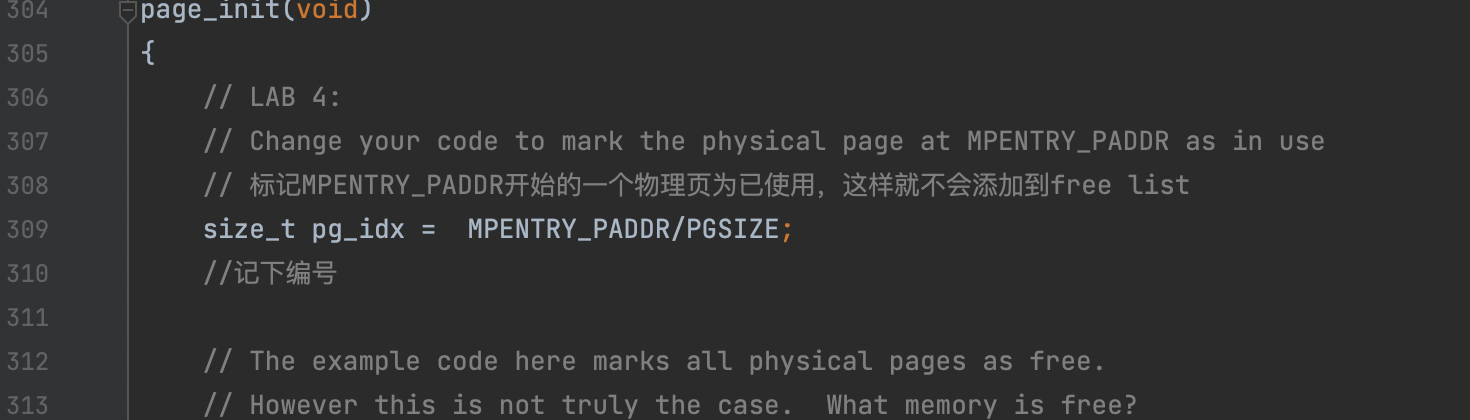
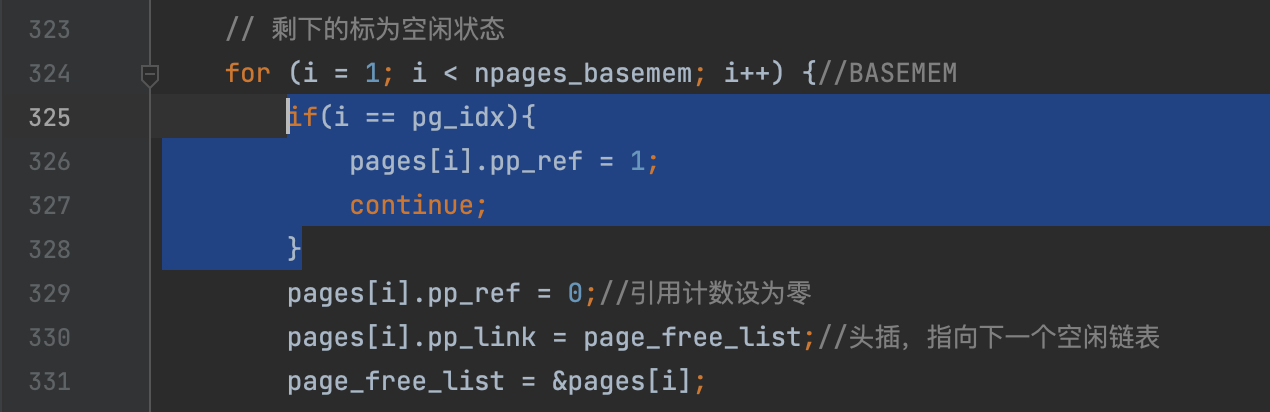
Read boot_aps() and mp_main() in kern/init.c, and the assembly code in kern/mpentry.S. Make sure you understand the control flow transfer during the bootstrap of APs. Then modify your implementation of page_init() in kern/pmap.cto avoid adding the page at MPENTRY_PADDR to the free list, so that we can safely copy and run AP bootstrap code at that physical address. Your code should pass the updated check_page_free_list() test (but might fail the updated check_kern_pgdir() test, which we will fix soon).
real mode表示我们看到的都是直接的物理地址
Question
Compare kern/mpentry.S side by side with boot/boot.S. Bearing in mind that kern/mpentry.S is compiled and linked to run above KERNBASE just like everything else in the kernel, what is the purpose of macro MPBOOTPHYS? Why is it necessary in kern/mpentry.S but not in boot/boot.S? In other words, what could go wrong if it were omitted in kern/mpentry.S? Hint: recall the differences between the link address and the load address that we have discussed in Lab 1.
# This code is similar to boot/boot.S except that # - it does not need to enable A20 # - it uses MPBOOTPHYS to calculate absolute addresses of its # symbols, rather than relying on the linker to fill them
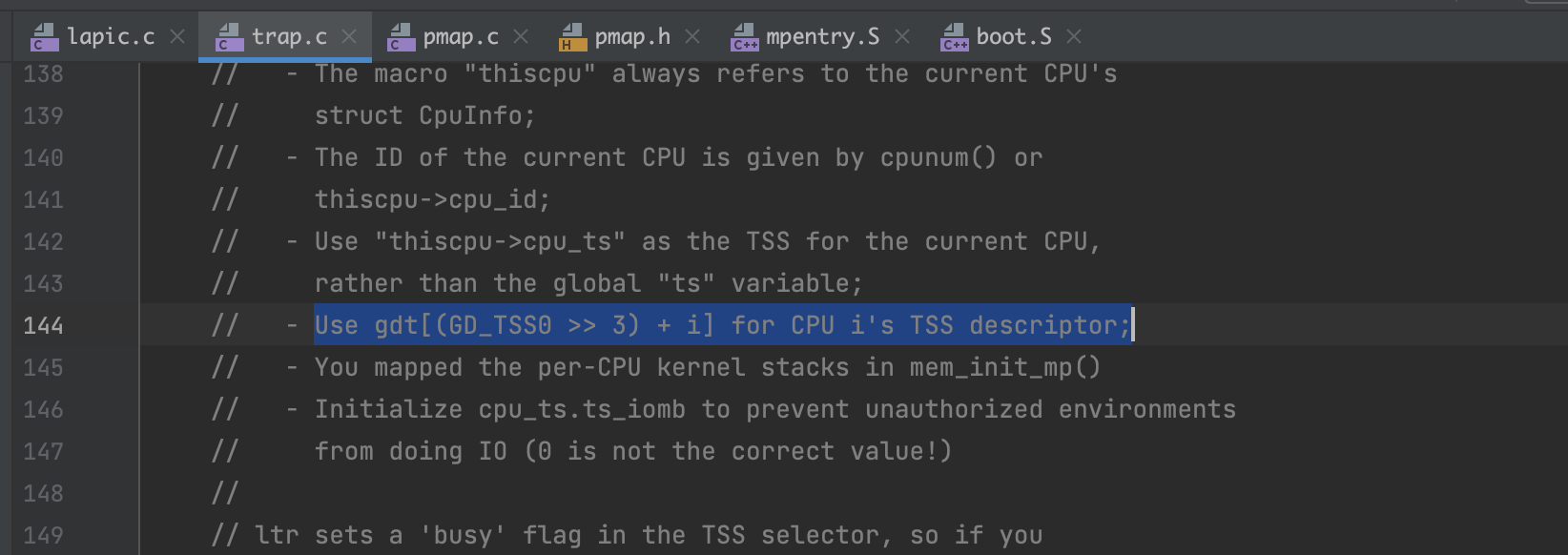
Per-CPU TSS 以及 TSS 描述符 为了指明每个 CPU 的内核栈位置,需要任务状态段 (Task State Segment, TSS),其功能在 Lab3 中已经详细讲过。
Per-CPU 当前环境指针 因为每个 CPU 能够同时运行各自的用户进程,我们重新定义了基于cpus[cpunum()] 的 curenv。
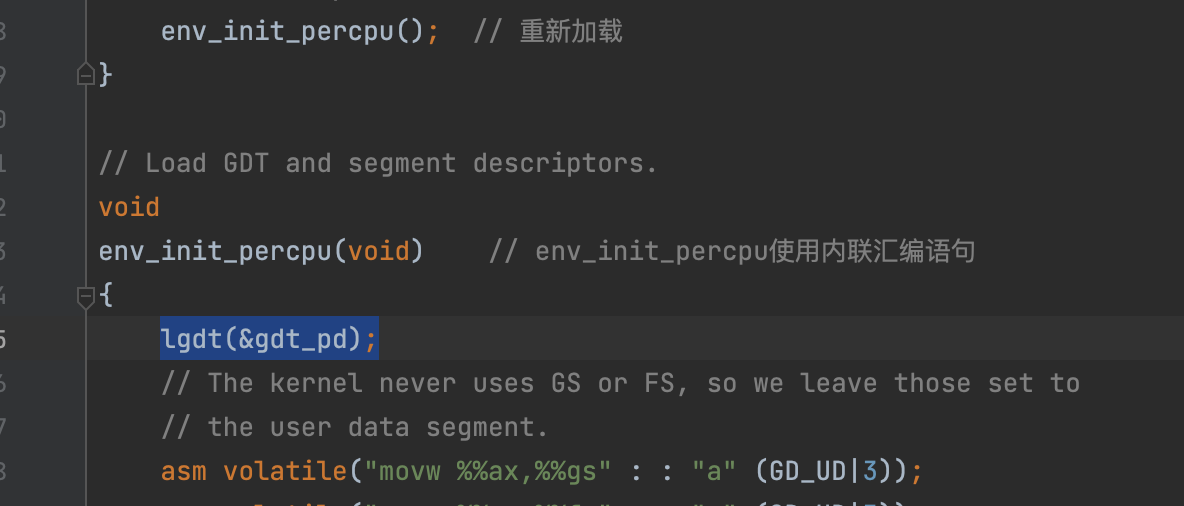
Per-CPU 系统寄存器 所有的寄存器,包括系统寄存器,都是 CPU 私有的。因此,初始化这些寄存器的指令,例如 lcr3(), ltr(), lgdt(), lidt() 等,必须在每个 CPU 都执行一次。
Exercise 3.
Modify mem_init_mp() (in kern/pmap.c) to map per-CPU stacks starting at KSTACKTOP, as shown in inc/memlayout.h. The size of each stack is KSTKSIZE bytes plus KSTKGAP bytes of unmapped guard pages. Your code should pass the new check in check_kern_pgdir().
// Initialize and load the per-CPU TSS and IDT void trap_init_percpu(void) { // LAB 4: Your code here: structTaskstate* this_ts = &thiscpu->cpu_ts; //!!!!!!!!!!!! // 一开始写成了struct Taskstate this_ts = thiscpu->cpu_ts; // 导致cpu的值并未改变,然后出现triple fault !!!!!!!!!! // Setup a TSS so that we get the right stack // when we trap to the kernel. ts.ts_esp0 = KSTACKTOP; ts.ts_ss0 = GD_KD; ts.ts_iomb = sizeof(struct Taskstate);
// Initialize the TSS slot of the gdt. gdt[GD_TSS0 >> 3] = SEG16(STS_T32A, (uint32_t) (&ts), sizeof(struct Taskstate) - 1, 0); gdt[GD_TSS0 >> 3].sd_s = 0;
// Load the TSS selector (like other segment selectors, the // bottom three bits are special; we leave them 0) ltr(GD_TSS0);
// Load the IDT lidt(&idt_pd); }
运行 make qemu CPUS=4 (or make qemu-nox CPUS=4)
Exercise5: Locking
我们现在的代码在初始化 AP 后就会开始自旋。在进一步操作 AP 之前,我们要先处理几个 CPU 同时运行内核代码的竞争情况。最简单的方法是用一个大内核锁 (big kernel lock)。它是一个全局锁,在某个进程进入内核态时锁定,返回用户态时释放。这种模式下,用户进程可以并发地在 CPU 上运行,但是同一时间仅有一个进程可以在内核态,其他需要进入内核态的进程只能等待。 kern/spinlock.h 声明了一个大内核锁 kernel_lock。它提供了 lock_kernel() 和 unlock_kernel() 方法用于获得和释放锁。在以下 4 个地方需要使用到大内核锁:
在 i386_init(),BSP 唤醒其他 CPU 之前获得内核锁
在 mp_main(),初始化 AP 之后获得内核锁,之后调用 sched_yield() 在 AP 上运行进程。
Apply the big kernel lock as described above, by calling lock_kernel() and unlock_kernel() at the proper locations.
kern/init.c/i386_init()
1 2 3 4 5
// Acquire the big kernel lock before waking up APs // Your code here: lock_kernel(); // Starting non-boot CPUs boot_aps();
init.c/mp_main()
1 2 3 4 5 6 7
// Now that we have finished some basic setup, call sched_yield() // to start running processes on this CPU. But make sure that // only one CPU can enter the scheduler at a time! // // Your code here: lock_kernel(); sched_yield();
trap.c/trap()
1 2 3 4 5 6 7
if ((tf->tf_cs & 3) == 3) { // 陷入了内核态 // Trapped from user mode. // Acquire the big kernel lock before doing any // serious kernel work. // LAB 4: Your code here. lock_kernel(); assert(curenv);
BPS 启动 AP 前,获取内核锁,所以 AP 会在 mp_main 执行调度之前阻塞,在启动完 AP 后,BPS 执行调度,运行第一个进程,env_run() 函数中会释放内核锁,这样一来,其中一个 AP 就可以开始执行调度,运行其他进程。
Question 2. It seems that using the big kernel lock guarantees that only one CPU can run the kernel code at a time. Why do we still need separate kernel stacks for each CPU? Describe a scenario in which using a shared kernel stack will go wrong, even with the protection of the big kernel lock
sched_yield()不能同时在两个CPU上运行同一个进程。如果一个进程已经在某个 CPU 上运行,其状态会变为 ENV_RUNNING。
程序中已经实现了一个新的系统调用 sys_yield(),进程可以用它来唤起内核的 sched_yield() 函数,从而将 CPU 资源移交给一个其他的进程
Exercise 6. Implement round-robin scheduling in sched_yield() as described above. Don’t forget to modify syscall() to dispatch sys_yield(). Make sure to invoke sched_yield() in mp_main. Modify kern/init.c to create three (or more!) environments that all run the program user/yield.c.
// Choose a user environment to run and run it. void sched_yield(void) { structEnv *idle;
// Implement simple round-robin scheduling. // // Search through 'envs' for an ENV_RUNNABLE environment in // circular fashion starting just after the env this CPU was // last running. Switch to the first such environment found. // // If no envs are runnable, but the environment previously // running on this CPU is still ENV_RUNNING, it's okay to // choose that environment. // // Never choose an environment that's currently running on // another CPU (env_status == ENV_RUNNING). If there are // no runnable environments, simply drop through to the code // below to halt the cpu.
Question 3. In your implementation of env_run() you should have called lcr3(). Before and after the call to lcr3(), your code makes references (at least it should) to the variable e, the argument to env_run. Upon loading the %cr3 register, the addressing context used by the MMU is instantly changed. But a virtual address (namely e) has meaning relative to a given address context–the address context specifies the physical address to which the virtual address maps. Why can the pointer e be dereferenced both before and after the addressing switch?
大意是问为什么通过 lcr3() 切换了页目录,还能照常对 e 解引用。回想在 lab3 中,曾经写过的函数 env_setup_vm()。它直接以内核的页目录作为模版稍做修改。因此两个页目录的 e 地址映射到同一物理地址。
Question 4. Whenever the kernel switches from one environment to another, it must ensure the old environment’s registers are saved so they can be restored properly later. Why? Where does this happen?
在进程陷入内核时,会保存当前的运行信息,这些信息都保存在内核栈上。而当从内核态回到用户态时,会恢复之前保存的运行信息。 具体到 JOS 代码中,保存发生在 kern/trapentry.S,恢复发生在 kern/env.c。可以对比两者的代码。 保存:
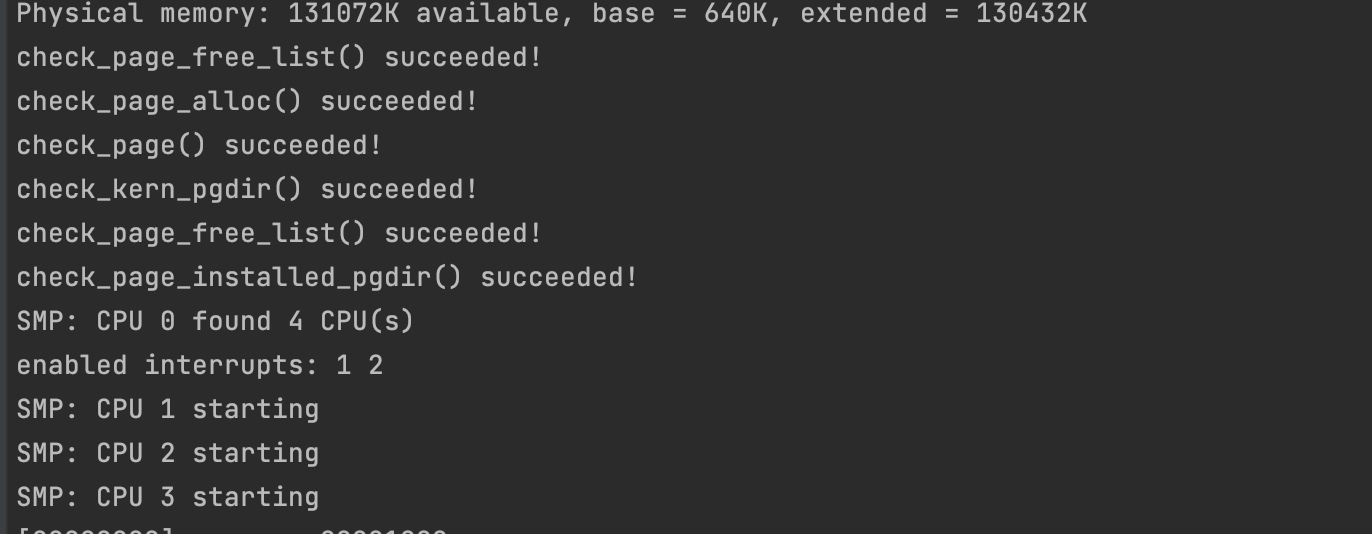
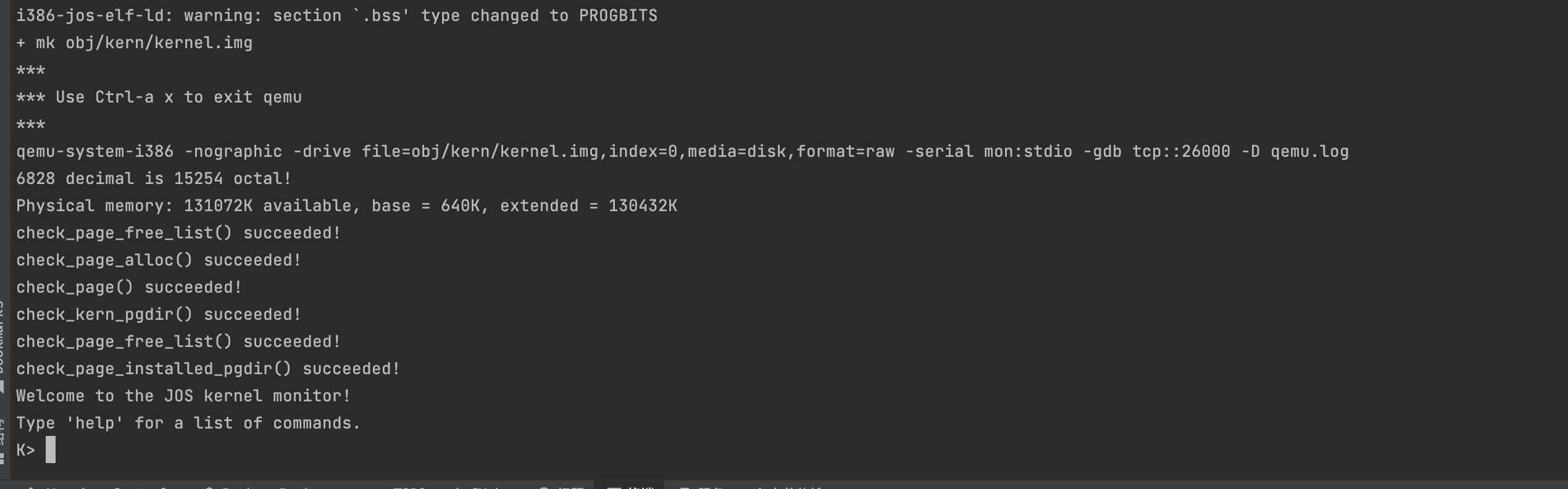
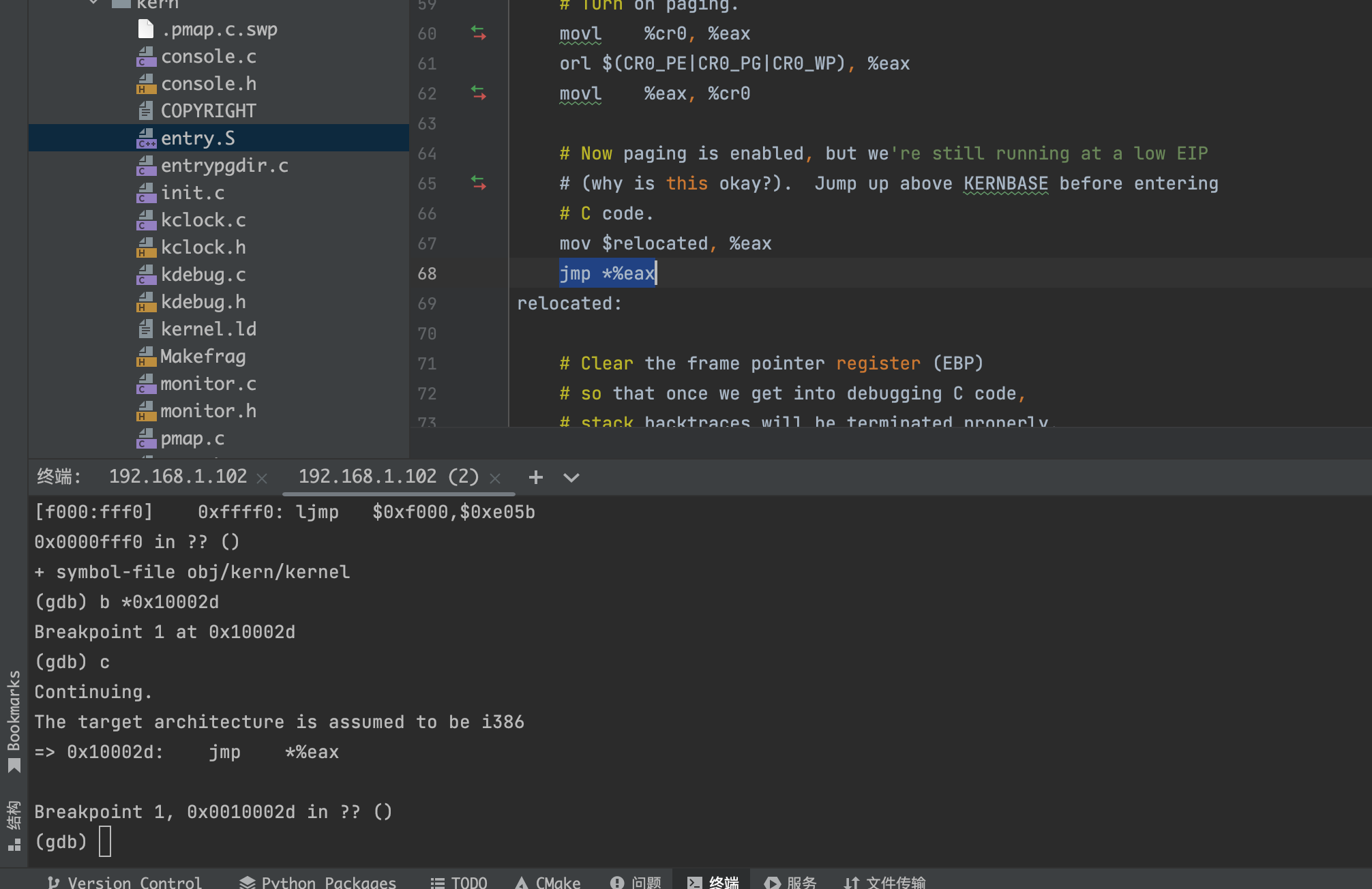
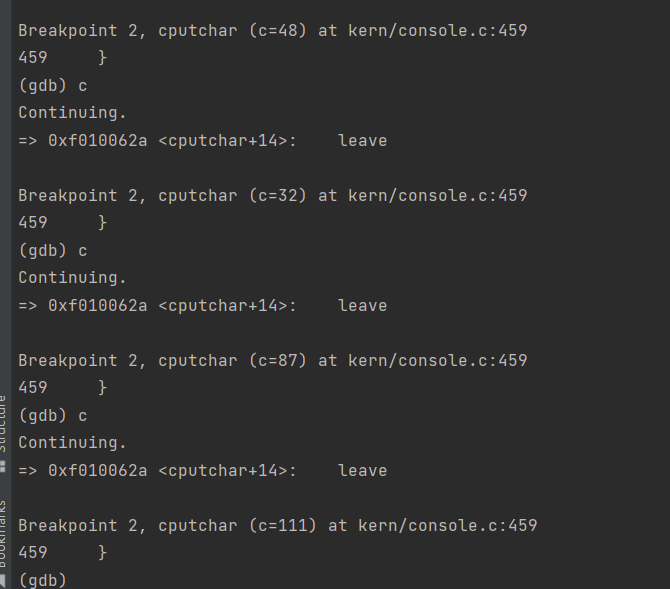
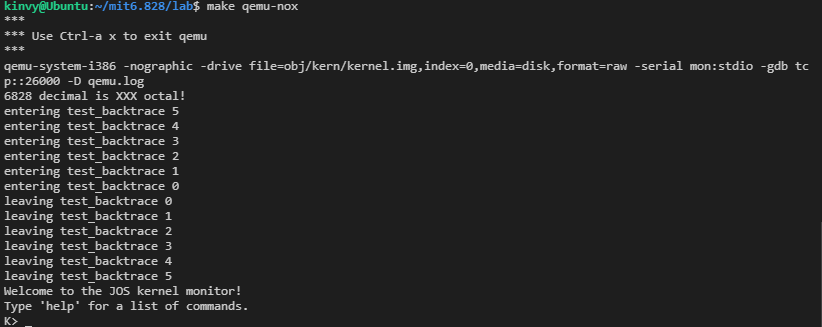
➜ lab git:(lab4) ✗ make qemu-nox CPUS=2 *** *** Use Ctrl-a x to exit qemu *** qemu-system-i386 -nographic -drive file=obj/kern/kernel.img,index=0,media=disk,format=raw -serial mon:stdio -gdb tcp::26000 -D qemu.log -smp 2 6828 decimal is 15254 octal! Physical memory: 131072K available, base = 640K, extended = 130432K check_page_free_list() succeeded! check_page_alloc() succeeded! check_page() succeeded! check_kern_pgdir() succeeded! check_page_free_list() succeeded! check_page_installed_pgdir() succeeded! SMP: CPU 0 found 2 CPU(s) enabled interrupts: 1 2 SMP: CPU 1 starting [00000000] new env 00001000 [00000000] new env 00001001 [00000000] new env 00001002 Incoming TRAP frame at 0xefffffbc Incoming TRAP frame at 0xeffeffbc Incoming TRAP frame at 0xefffffbc Hello, I am environment 00001000. Incoming TRAP frame at 0xeffeffbc Hello, I am environment 00001001. Incoming TRAP frame at 0xefffffbc Incoming TRAP fIncoming TRAP frame at 0xefffffbc rame at 0xeffeffbc Incoming TRAP frame at 0Incoming TRAP frame at 0xefffffbc Hello, I am environment 00001002. xeffeffbc Back in environment 00001000, iteration 0. Incoming TRAP frame at 0xefffffbc Incoming TRAP frame at 0xeffeffbc Incoming TRAP frame at 0xefffffbc Back in environment 00001001, iteration 0. Incoming TRAP frame at 0xeffeffbc Back in environment 00001002, iteration 0. Incoming TRAP frame at 0xefffffbc Incoming TRAP frame at 0xeffeffbc Incoming TRAP frame at 0xefffffbc Back in environment 00001000, iteration 1. Incoming TRAP frame at 0xeffeffbc Back in environment 00001001, iteration 1. Incoming TRAP frame at 0xefffffbc Incoming TRAP frame at 0xeffeffbc Incoming TRAP frame at 0xefffffbc Back in environment 00001002, iteration 1. Incoming TRAP frame at 0xeffeffbc Back in environment 00001000, iteration 2. Incoming TRAP frame at 0xefffffbc Incoming TRAP frame at 0xeffeffbc Incoming TRAP frame at 0xefffffbc Back in environment 00001001, iteration 2. Incoming TRAP frame at 0xeffeffbc Back in environment 00001002, iteration 2. Incoming TRAP frame at 0xefffffbc Incoming TRAP frame at 0xeffeffbc Incoming TRAP frame at 0xefffffbc Back in environment 00001000, iteration 3. Incoming TRAP frame at 0xeffeffbc Back in environment 00001001, iteration 3. Incoming TRAP frame at 0xefffffbc Incoming TRAP frame at 0xeffeffbc Incoming TRAP frame at 0xefffffbc Back in environment 00001002, iteration 3. Incoming TRAP frame at 0xeffeffbc Back in environment 00001000, iteration 4. Incoming TRAP frame at 0xefffffbc Incoming TRAP frame at 0xeffeffbc All done in environment 00001000. Incoming TRAP frame at 0xefffffbc Back in environment 00001001, iteration 4. Incoming TRAP frame at 0xeffeffbc [00001000] exiting gracefully [00001000] free env 00001000 Incoming TRAP frame at 0xefffffbc All done in environment 00001001. Incoming TRAP frame at 0xeffeffbc Back in environment 00001002, iteration 4. Incoming TRAP frame at 0xefffffbc [00001001] exiting gracefully [00001001] free env 00001001 Incoming TRAP frame at 0xeffeffbc All done in environment 00001002. Incoming TRAP frame at 0xeffeffbc [00001002] exiting gracefully [00001002] free env 00001002 No runnable environments in the system! Welcome to the JOS kernel monitor! Type 'help' for a list of commands.
cpu=2时,三个进程通过sys_yield切换了5次。
Exercise 7: System Calls for Environment Creation(系统调用: 创建进程)
Exercise 7. Implement the system calls described above in kern/syscall.c. You will need to use various functions in kern/pmap.c and kern/env.c, particularly envid2env(). For now, whenever you call envid2env(), pass 1 in the checkperm parameter. Be sure you check for any invalid system call arguments, returning -E_INVAL in that case. Test your JOS kernel with user/dumbfork and make sure it works before proceeding.
// This is NOT what you should do in your fork. if ((r = sys_page_alloc(dstenv, addr, PTE_P|PTE_U|PTE_W)) < 0) panic("sys_page_alloc: %e", r); if ((r = sys_page_map(dstenv, addr, 0, UTEMP, PTE_P|PTE_U|PTE_W)) < 0) panic("sys_page_map: %e", r); memmove(UTEMP, addr, PGSIZE); if ((r = sys_page_unmap(0, UTEMP)) < 0) panic("sys_page_unmap: %e", r); }
Exercise 8. Implement the sys_env_set_pgfault_upcall system call. Be sure to enable permission checking when looking up the environment ID of the target environment, since this is a “dangerous” system call.
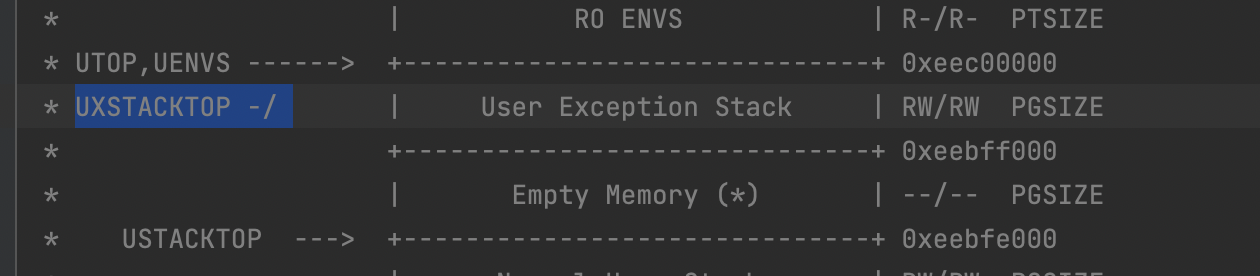
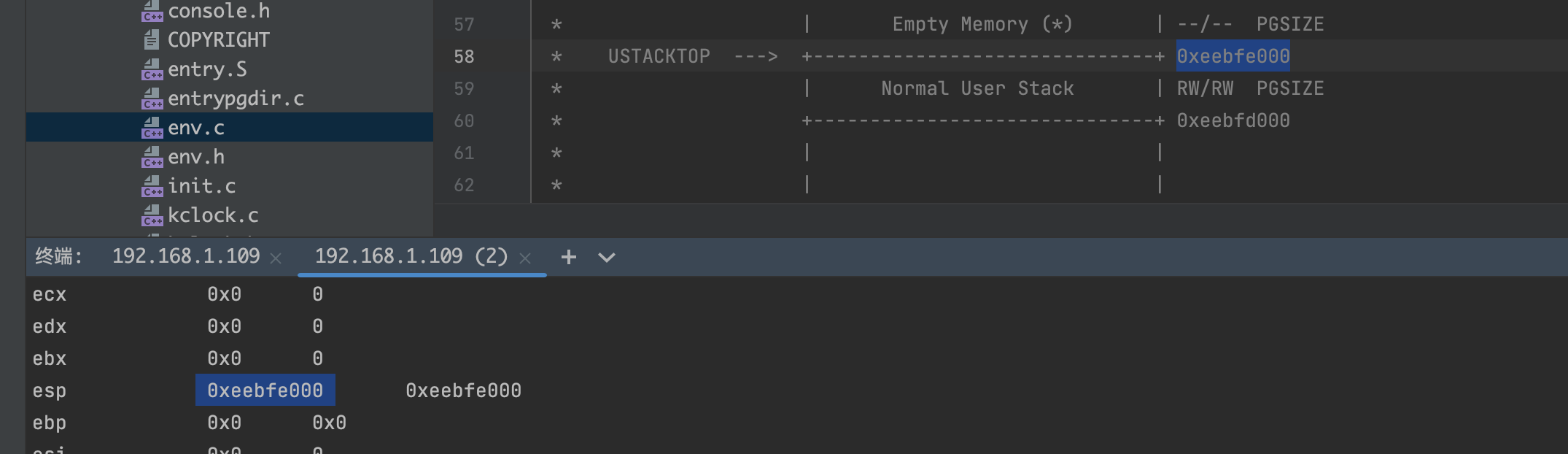
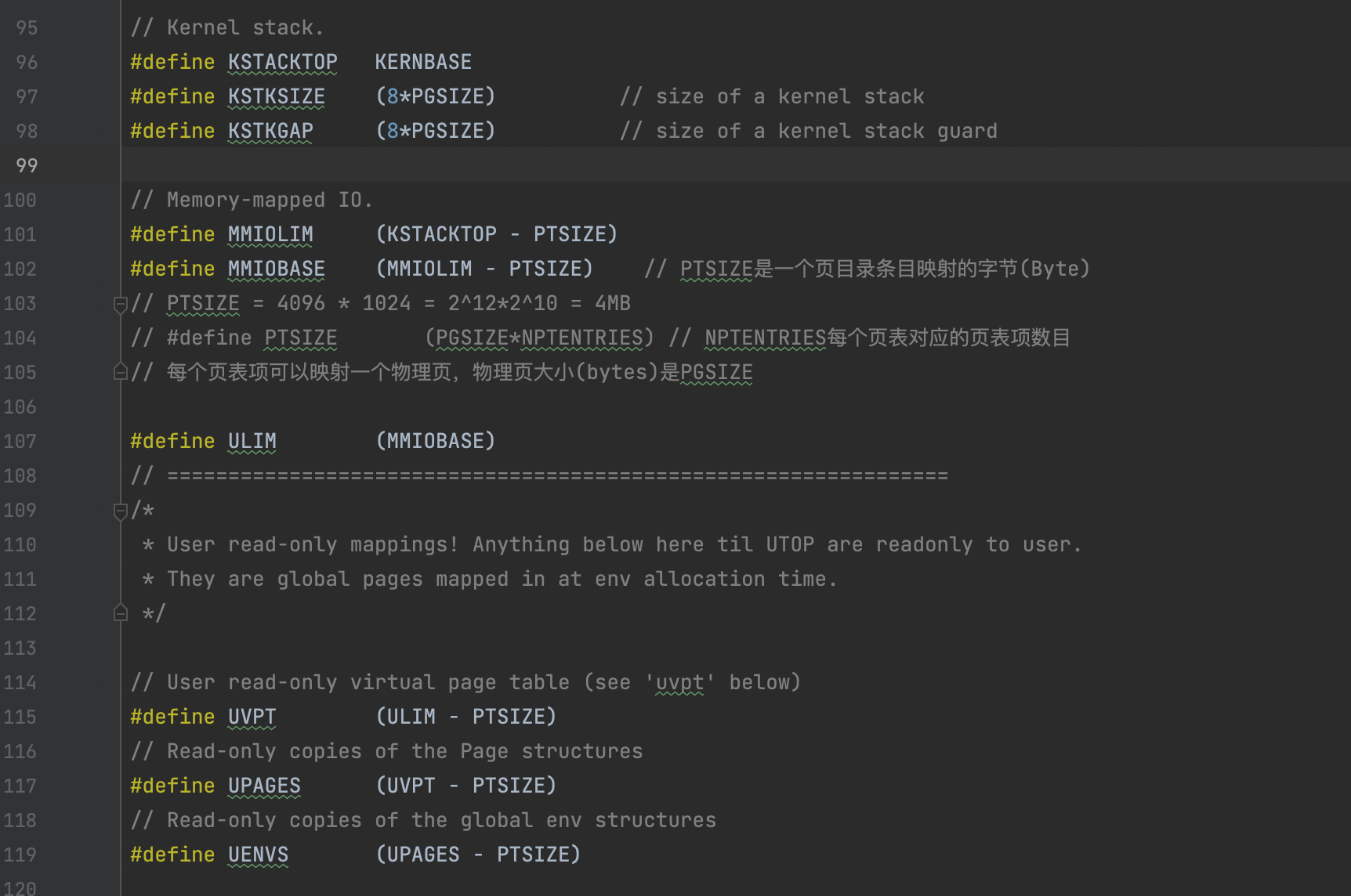
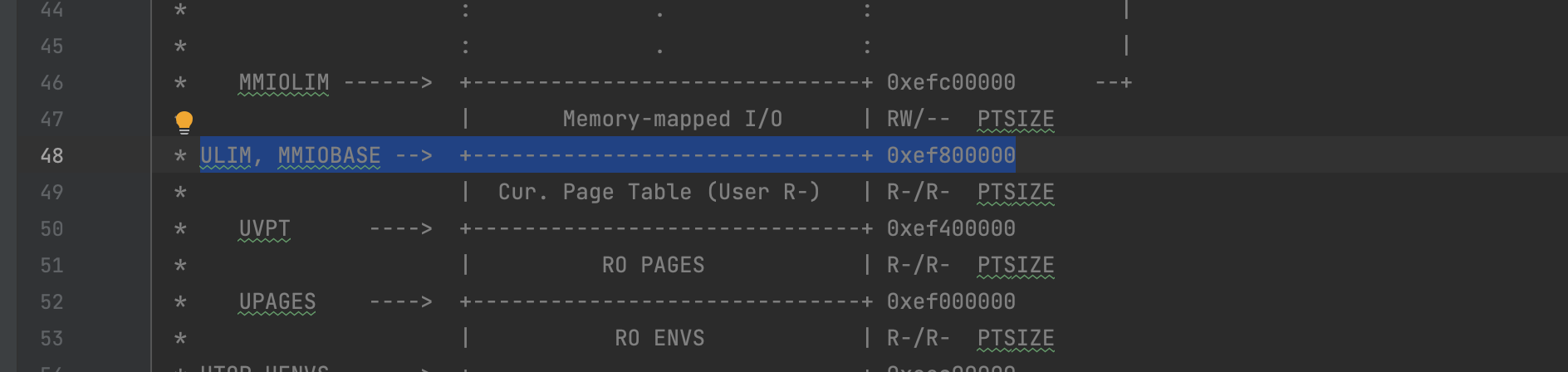
进程的正常栈和异常栈
正常运行时,JOS 的进程会运行在正常栈上,ESP 从USTACKTOP开始往下生长,栈上的数据存放在 [USTACKTOP-PGSIZE, USTACKTOP-1] 上。当出现页错误时,内核会把进程在一个新的栈(异常栈)上面重启,运行指定的用户级别页错误处理函数。也就是说完成了一次进程内的栈切换。这个过程与 trap 的过程很相似。 JOS 的异常栈也只有一个物理页大小,并且它的栈顶定义在虚拟内存 UXSTACKTOP 处。当运行在这个栈上时,用户级别页错误处理函数可以使用 JOS 的系统调用来映射新的页,以修复页错误。 每个需要支持用户级页错误处理的函数都需要分配自己的异常栈。可以使用 sys_page_alloc() 这个系统调用来实现。
Implement the code in page_fault_handler in kern/trap.c required to dispatch page faults to the user-mode handler. Be sure to take appropriate precautions when writing into the exception stack. (What happens if the user environment runs out of space on the exception stack?)
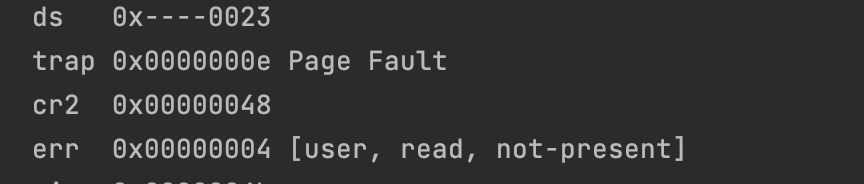
// Destroy the environment that caused the fault. cprintf("[%08x] user fault va %08x ip %08x\n", curenv->env_id, fault_va, tf->tf_eip); print_trapframe(tf); env_destroy(curenv); }
Question What happens if the user environment runs out of space on the exception stack?
在 inc/memlayout.h 中可以找到:
1 2
#define UXSTACKTOP UTOP // Next page left invalid to guard against exception stack overflow;
下面一页是空页,内核和用户访问都会报错。
用户模式页错误入口
在处理完页错误之后,现在我们需要编写汇编语句实现从异常栈到正常栈的切换。
Exercise 10.
Implement the _pgfault_upcall routine in lib/pfentry.S. The interesting part is returning to the original point in the user code that caused the page fault. You’ll return directly there, without going back through the kernel. The hard part is simultaneously switching stacks and re-loading the EIP.
// Restore the trap-time registers. After you do this, you // can no longer modify any general-purpose registers. // LAB 4: Your code here. // 跳过 utf_err 以及 utf_fault_va addl $8, %esp // popal 同时 esp 会增加,执行结束后 %esp 指向 utf_eip popal
// Restore eflags from the stack. After you do this, you can // no longer use arithmetic operations or anything else that // modifies eflags. // LAB 4: Your code here. // 跳过 utf_eip addl $4, %esp // 恢复 eflags popfl
// Switch back to the adjusted trap-time stack. // LAB 4: Your code here. // 恢复 trap-time 的栈顶 popl %esp // Return to re-execute the instruction that faulted. // LAB 4: Your code here. // ret 指令相当于 popl %eip ret
它在调用 sys_cputs() 之前,首先在用户态执行了 vprintfmt() 将要输出的字符串存入结构体 b 中。在此过程中试图访问 0xdeadbeef 地址,触发并处理了页错误(其处理方式是在错误位置处分配一个字符串,内容是 "this string was faulted in at ..."),因此在继续调用 sys_cputs() 时不会出现 panic。
// parent // extern unsigned char end[]; // for ((uint8_t *) addr = UTEXT; addr < end; addr += PGSIZE) for (uintptr_t addr = UTEXT; addr < USTACKTOP; addr += PGSIZE) { if ( (uvpd[PDX(addr)] & PTE_P) && (uvpt[PGNUM(addr)] & PTE_P) ) { // dup page to child duppage(e_id, PGNUM(addr)); } } // alloc page for exception stack int r = sys_page_alloc(e_id, (void *)(UXSTACKTOP-PGSIZE), PTE_U | PTE_W | PTE_P); if (r < 0) panic("fork: %e",r);
// DO NOT FORGET externvoid _pgfault_upcall(); r = sys_env_set_pgfault_upcall(e_id, _pgfault_upcall); if (r < 0) panic("fork: set upcall for child fail, %e", r);
// mark the child environment runnable if ((r = sys_env_set_status(e_id, ENV_RUNNABLE)) < 0) panic("sys_env_set_status: %e", r);
// Check that the faulting access was (1) a write, and (2) to a // copy-on-write page. If not, panic. // Hint: // Use the read-only page table mappings at uvpt // (see <inc/memlayout.h>).
// LAB 4: Your code here. if ((err & FEC_WR)==0 || (uvpt[PGNUM(addr)] & PTE_COW)==0) { panic("pgfault: invalid user trap frame"); } // Allocate a new page, map it at a temporary location (PFTEMP), // copy the data from the old page to the new page, then move the new // page to the old page's address. // Hint: // You should make three system calls.
Modify kern/trapentry.S and kern/trap.c to initialize the appropriate entries in the IDT and provide handlers for IRQs 0 through 15. Then modify the code in env_alloc() in kern/env.c to ensure that user environments are always run with interrupts enabled.
Modify the kernel’s trap_dispatch() function so that it calls sched_yield() to find and run a different environment whenever a clock interrupt takes place.
直接在 trap_dispatch() 中添加时钟中断的分支即可。
1 2 3 4 5 6 7 8
// Handle clock interrupts. Don't forget to acknowledge the // interrupt using lapic_eoi() before calling the scheduler! // LAB 4: Your code here. if (tf->tf_trapno == IRQ_OFFSET + IRQ_TIMER) { lapic_eoi(); sched_yield(); return; }
Implement sys_ipc_recv and sys_ipc_try_send in kern/syscall.c. Read the comments on both before implementing them, since they have to work together. When you call envid2env in these routines, you should set the checkperm flag to 0, meaning that any environment is allowed to send IPC messages to any other environment, and the kernel does no special permission checking other than verifying that the target envid is valid. Then implement the ipc_recv and ipc_send functions in lib/ipc.c.
首先需要仔细阅读 inc/env.h 了解用于传递消息的数据结构。
1 2 3 4 5 6
// Lab 4 IPC bool env_ipc_recving; // 当前进程的状态,表明当前进程是否处于接受状态。 void *env_ipc_dstva; // VA at which to map received page uint32_t env_ipc_value; // 当前进程接收到的数据(如果用页来传递数据)。 envid_t env_ipc_from; // envid of the sender int env_ipc_perm; // Perm of page mapping received
实验三中,you will implement the basic kernel facilities required to get a protected user-mode environment (i.e., “process”) running. 将实现运行受保护的用户模式环境(即进程)所需的基本内核功能。将增强JOS内核以设置数据结构来跟踪 用户环境、创建单个用户环境、将程序映像(program image)加载到其中并开始运行。还需要使得JOS内核能够处理用户环境进行的任何调用和解决它所造成的一切异常情况。
// env指针指向一个由Env结构体组成的数组,同时,不活动的Env记录在env_free_list 中, 和之前的page_free_list很像 structEnv *envs =NULL; // All environments structEnv *curenv =NULL; // The current env curenv记录着现在正在运行的进程,在第一个进程运行之前为空 staticstructEnv *env_free_list;// Free environment list // (linked by Env->env_link)
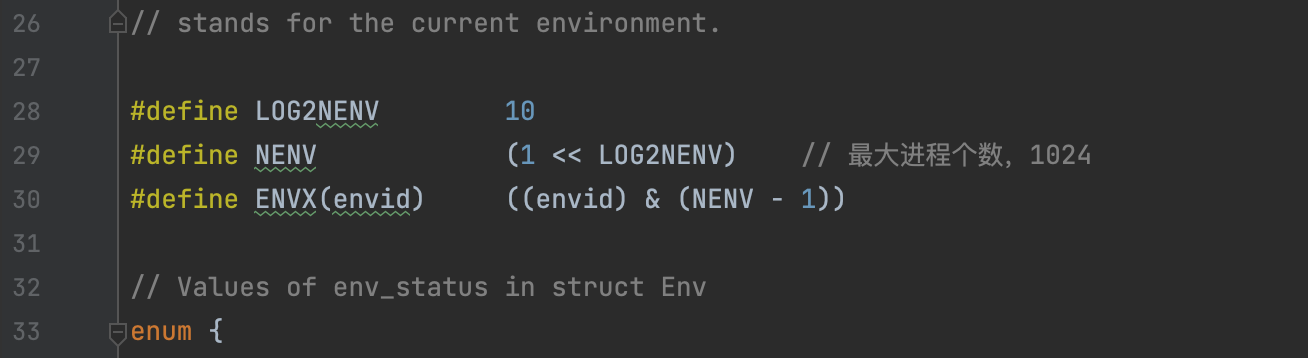
#define ENVGENSHIFT 12 // >= LOGNENV
inc/enc.h 中查看Env结构体的具体信息
1 2 3 4 5 6 7 8 9 10 11 12
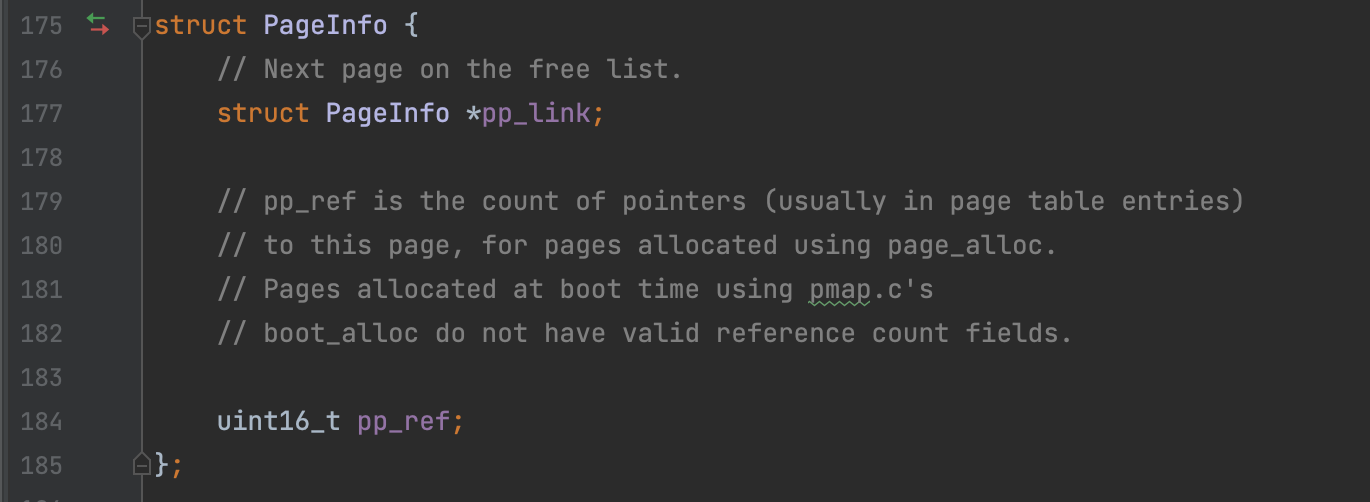
structEnv { structTrapframeenv_tf;// Saved registers structEnv *env_link;// Next free Env envid_t env_id; // Unique environment identifier envid_t env_parent_id; // env_id of this env's parent enumEnvTypeenv_type;// Indicates special system environments unsigned env_status; // Status of the environment uint32_t env_runs; // Number of times environment has run
// Address space pde_t *env_pgdir; // Kernel virtual address of page dir };
////////////////////////////////////////////////////////////////////// // Recursively insert PD in itself as a page table, to form // a virtual page table at virtual address UVPT. // (For now, you don't have understand the greater purpose of the // following line.)
// Permissions: kernel R, user R kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P;
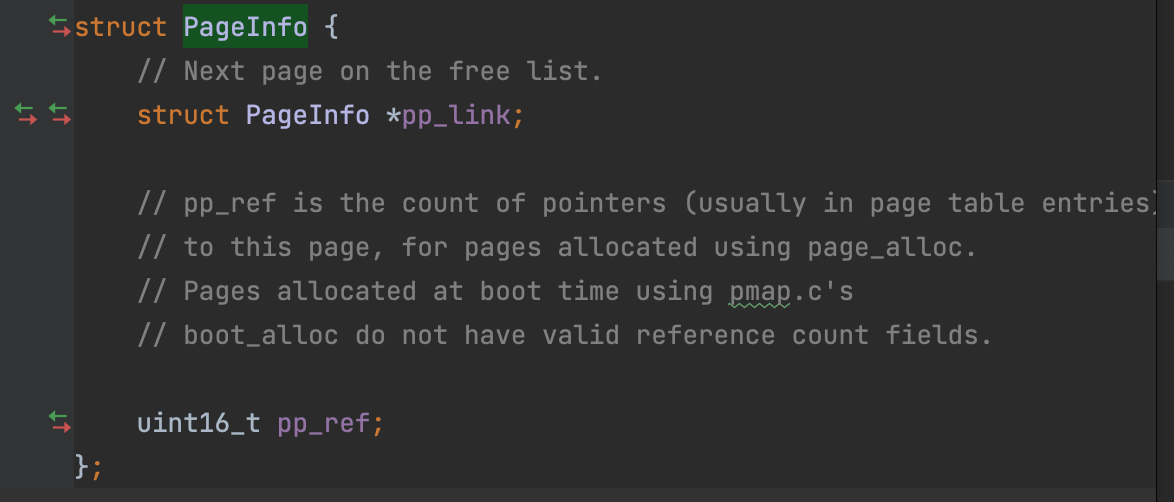
////////////////////////////////////////////////////////////////////// // Allocate an array of npages 'struct PageInfo's and store it in 'pages'. // The kernel uses this array to keep track of physical pages: for // each physical page, there is a corresponding struct PageInfo in this // array. 'npages' is the number of physical pages in memory. Use memset // to initialize all fields of each struct PageInfo to 0. // Your code goes here:
////////////////////////////////////////////////////////////////////// // Make 'envs' point to an array of size 'NENV' of 'struct Env'. // LAB 3: Your code here.
////////////////////////////////////////////////////////////////////// // Now that we've allocated the initial kernel data structures, we set // up the list of free physical pages. Once we've done so, all further // memory management will go through the page_* functions. In // particular, we can now map memory using boot_map_region // or page_insert page_init();
////////////////////////////////////////////////////////////////////// // Now we set up virtual memory
////////////////////////////////////////////////////////////////////// // Map 'pages' read-only by the user at linear address UPAGES // Permissions: // - the new image at UPAGES -- kernel R, user R // (ie. perm = PTE_U | PTE_P) // - pages itself -- kernel RW, user NONE // Your code goes here:
////////////////////////////////////////////////////////////////////// // Map the 'envs' array read-only by the user at linear address UENVS // (ie. perm = PTE_U | PTE_P). // Permissions: // - the new image at UENVS -- kernel R, user R // - envs itself -- kernel RW, user NONE // LAB 3: Your code here.
////////////////////////////////////////////////////////////////////// // Use the physical memory that 'bootstack' refers to as the kernel // stack. The kernel stack grows down from virtual address KSTACKTOP. // We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP) // to be the kernel stack, but break this into two pieces: // * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory // * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if // the kernel overflows its stack, it will fault rather than // overwrite memory. Known as a "guard page". // Permissions: kernel RW, user NONE // Your code goes here:
////////////////////////////////////////////////////////////////////// // Map all of physical memory at KERNBASE. // Ie. the VA range [KERNBASE, 2^32) should map to // the PA range [0, 2^32 - KERNBASE) // We might not have 2^32 - KERNBASE bytes of physical memory, but // we just set up the mapping anyway. // Permissions: kernel RW, user NONE // Your code goes here:
// Check that the initial page directory has been set up correctly. check_kern_pgdir();
// Switch from the minimal entry page directory to the full kern_pgdir // page table we just created. Our instruction pointer should be // somewhere between KERNBASE and KERNBASE+4MB right now, which is // mapped the same way by both page tables. // // If the machine reboots at this point, you've probably set up your // kern_pgdir wrong. lcr3(PADDR(kern_pgdir));
check_page_free_list(0);
// entry.S set the really important flags in cr0 (including enabling // paging). Here we configure the rest of the flags that we care about. cr0 = rcr0(); cr0 |= CR0_PE|CR0_PG|CR0_AM|CR0_WP|CR0_NE|CR0_MP; cr0 &= ~(CR0_TS|CR0_EM); lcr0(cr0);
// Some more checks, only possible after kern_pgdir is installed. check_page_installed_pgdir();
// Find out how much memory the machine has (npages & npages_basemem). i386_detect_memory();
// Remove this line when you're ready to test this function. // panic("mem_init: This function is not finished\n");
////////////////////////////////////////////////////////////////////// // Recursively insert PD in itself as a page table, to form // a virtual page table at virtual address UVPT. // (For now, you don't have understand the greater purpose of the // following line.)
// Permissions: kernel R, user R kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P;
////////////////////////////////////////////////////////////////////// // Allocate an array of npages 'struct PageInfo's and store it in 'pages'. // The kernel uses this array to keep track of physical pages: for // each physical page, there is a corresponding struct PageInfo in this // array. 'npages' is the number of physical pages in memory. Use memset // to initialize all fields of each struct PageInfo to 0. // Your code goes here: // 创建一个struct PageInfo 的数组 // kernel 使用这个数组来耿总每个物理页 // 对于每一个物理页,都会有一个对应的 struct PageInfo 在数组中 pages = (struct PageInfo *) boot_alloc(npages * sizeof(struct PageInfo)); // npages 是内存中物理页的数量 memset(pages, 0, npages * sizeof(struct PageInfo));
////////////////////////////////////////////////////////////////////// // Now that we've allocated the initial kernel data structures, we set // up the list of free physical pages. Once we've done so, all further // memory management will go through the page_* functions. In // particular, we can now map memory using boot_map_region // or page_insert page_init();
////////////////////////////////////////////////////////////////////// // Now we set up virtual memory
////////////////////////////////////////////////////////////////////// // Map 'pages' read-only by the user at linear address UPAGES // Permissions: // - the new image at UPAGES -- kernel R, user R // (ie. perm = PTE_U | PTE_P) // - pages itself -- kernel RW, user NONE // Your code goes here: // UPAGES是JOS记录物理页面使用情况的数据结构,只有kernel能够访问 // 为了使用户空间能访问这块数据结构,会将PAGES映射到UPAGES的位置 // 但是现在需要让用户空间能够读取这段线性地址,因此需要建立映射,将用户空间的一块内存映射到存储该数据结构的物理地址上 // boot_map_region() 建立映射关系 boot_map_region(kern_pgdir, (uintptr_t)UPAGES, npages*sizeof(struct PageInfo), PADDR(pages), PTE_U | PTE_P); // 目前建立了一个页目录,kernel_pgdir // pgdir为页目录指针, UPAGES为虚拟地址,npages*sizeof(struct* PageInfo)为映射的内存块大小 // PADDR(pages) 为物理地址, PTE_U | PTE为权限 (PTE_U 表示用户可读)
////////////////////////////////////////////////////////////////////// // Use the physical memory that 'bootstack' refers to as the kernel // stack. The kernel stack grows down from virtual address KSTACKTOP. // We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP) // to be the kernel stack, but break this into two pieces: // * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory // * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if // the kernel overflows its stack, it will fault rather than // overwrite memory. Known as a "guard page". // Permissions: kernel RW, user NONE // Your code goes here: // kernel 内核栈 // kernel stack 从虚拟地址 KSTACKTOP 开始,向低地址增长,所以KSTACKTOP实际上是栈顶 // KSTACKTOP = 0xf0000000, // KSTKSIZE = (8*PGSIZE) = 8*4096(bytes) = 32KB // 只需要映射 [KSTACKTOP, KSTACKTOP - KSTKSIZE) 范围的虚拟地址 boot_map_region(kern_pgdir, (uintptr_t)(KSTACKTOP - KSTKSIZE), KSTKSIZE, PADDR(bootstack), PTE_W | PTE_P); // PTE_W 开启了写权限,但是并未打开 PTE_U, 因此用户没有权限,只有内核有权限
////////////////////////////////////////////////////////////////////// // Map all of physical memory at KERNBASE. // Ie. the VA range [KERNBASE, 2^32) should map to // the PA range [0, 2^32 - KERNBASE) // We might not have 2^32 - KERNBASE bytes of physical memory, but // we just set up the mapping anyway. // Permissions: kernel RW, user NONE // Your code goes here: // 内核部分 // KERNBASE = 0xF0000000, VA大小为 2^32 - KERNBASE // ROUNDUP(a,n) 将a四舍五入到最接近n的倍数 boot_map_region(kern_pgdir, (uintptr_t)KERNBASE, ROUNDUP(0xffffffff - KERNBASE + 1, PGSIZE), 0, PTE_W | PTE_P);
// Check that the initial page directory has been set up correctly. check_kern_pgdir();
// Switch from the minimal entry page directory to the full kern_pgdir // page table we just created. Our instruction pointer should be // somewhere between KERNBASE and KERNBASE+4MB right now, which is // mapped the same way by both page tables. // // If the machine reboots at this point, you've probably set up your // kern_pgdir wrong. lcr3(PADDR(kern_pgdir));
check_page_free_list(0);
// entry.S set the really important flags in cr0 (including enabling // paging). Here we configure the rest of the flags that we care about. cr0 = rcr0(); cr0 |= CR0_PE | CR0_PG | CR0_AM | CR0_WP | CR0_NE | CR0_MP; cr0 &= ~(CR0_TS | CR0_EM); lcr0(cr0);
// Some more checks, only possible after kern_pgdir is installed. check_page_installed_pgdir();
}
Exercise 2: Creating and Running Environments
You will now write the code in kern/env.c necessary to run a user environment. Because we do not yet have a filesystem, we will set up the kernel to load a static binary image that is embedded within the kernel itself. JOS embeds this binary in the kernel as a ELF executable image.
In i386_init() in kern/init.c you’ll see code to run one of these binary images in an environment. However, the critical functions to set up user environments are not complete; you will need to fill them in.
staticint env_setup_vm(struct Env *e) { int i; structPageInfo *p =NULL;
// Allocate a page for the page directory if (!(p = page_alloc(ALLOC_ZERO))) // 给p分配个 页目录 return -E_NO_MEM;
// Now, set e->env_pgdir and initialize the page directory. // // Hint: // - The VA space of all envs is identical above UTOP // (except at UVPT, which we've set below). // See inc/memlayout.h for permissions and layout. // Can you use kern_pgdir as a template? Hint: Yes. // (Make sure you got the permissions right in Lab 2.) // - The initial VA below UTOP is empty. // - You do not need to make any more calls to page_alloc. // - Note: In general, pp_ref is not maintained for // physical pages mapped only above UTOP, but env_pgdir // is an exception -- you need to increment env_pgdir's // pp_ref for env_free to work correctly. // - The functions in kern/pmap.h are handy. // LAB 3: Your code here. // env_setup_vm负责创建进程自己的页目录,并初始化内核地址空间。 // 它不需要为内核地址空间另外创建页表,只要先将内核页目录kern_pgdir的所有目录项复制过来即可,以后再设置用户地址空间。 // // pde_t *env_pgdir; // Kernel virtual address of page dir e->env_pgdir = page2kva(p); memcpy(e->env_pgdir, kern_pgdir, PGSIZE); p->pp_ref++; // p此时指向了页目录
// UVPT maps the env's own page table read-only. // Permissions: kernel R, user R e->env_pgdir[PDX(UVPT)] = PADDR(e->env_pgdir) | PTE_P | PTE_U; // PDX() page directory index NPDENTRIES 1024 return0; }
region_alloc()
为环境env分配 len 字节的物理内存,并将其映射到环境地址空间中的虚拟地址va。不以任何方式将映射页归零或初始化。页面应该是用户和内核可写的。Panic if any allocation attempt fails.
staticvoid region_alloc(struct Env *e, void *va, size_t len) { // LAB 3: Your code here. // (But only if you need it for load_icode.) // // Hint: It is easier to use region_alloc if the caller can pass // 'va' and 'len' values that are not page-aligned. // You should round va down, and round (va + len) up. // (Watch out for corner-cases!) uintptr_t va_start = ROUNDDOWN((uintptr_t)va, PGSIZE); uintptr_t va_end = ROUNDUP((uintptr_t)va + len, PGSIZE); structPageInfo *pginfo =NULL; for(int cur_va = va_start;cur_va<va_end;cur_va+=PGSIZE){ pginfo = page_alloc(0); if(!pginfo){ panic("region_alloc: pageinfo failed."); } cprintf("insert page at %08x\n.", cur_va); page_insert(e->env_pgdir, pginfo, (void*)cur_va, PTE_U | PTE_W | PTE_P); } }
staticvoid load_icode(struct Env *e, uint8_t *binary) { // Hints: // Load each program segment into virtual memory // at the address specified in the ELF segment header. // You should only load segments with ph->p_type == ELF_PROG_LOAD. // Each segment's virtual address can be found in ph->p_va // and its size in memory can be found in ph->p_memsz. // The ph->p_filesz bytes from the ELF binary, starting at // 'binary + ph->p_offset', should be copied to virtual address // ph->p_va. Any remaining memory bytes should be cleared to zero. // (The ELF header should have ph->p_filesz <= ph->p_memsz.) // Use functions from the previous lab to allocate and map pages. // // All page protection bits should be user read/write for now. // ELF segments are not necessarily page-aligned, but you can // assume for this function that no two segments will touch // the same virtual page. // // You may find a function like region_alloc useful. // // Loading the segments is much simpler if you can move data // directly into the virtual addresses stored in the ELF binary. // So which page directory should be in force during // this function? // // You must also do something with the program's entry point, // to make sure that the environment starts executing there. // What? (See env_run() and env_pop_tf() below.)
void env_run(struct Env *e) { // Hint: This function loads the new environment's state from // e->env_tf. Go back through the code you wrote above // and make sure you have set the relevant parts of // e->env_tf to sensible values.
Exercise 4. Edit trapentry.S and trap.c and implement the features described above. The macros TRAPHANDLER and TRAPHANDLER_NOEC in trapentry.S should help you, as well as the T_* defines in inc/trap.h. You will need to add an entry point in trapentry.S (using those macros) for each trap defined in inc/trap.h, and you’ll have to provide _alltraps which the TRAPHANDLER macros refer to. You will also need to modify trap_init() to initialize the idt to point to each of these entry points defined in trapentry.S; the SETGATE macro will be helpful here.
Your _alltraps should:
push values to make the stack look like a struct Trapframe
load GD_KD into %ds and %es
pushl %esp to pass a pointer to the Trapframe as an argument to trap()
call trap (can trap ever return?)
Consider using the pushal instruction; it fits nicely with the layout of the struct Trapframe.
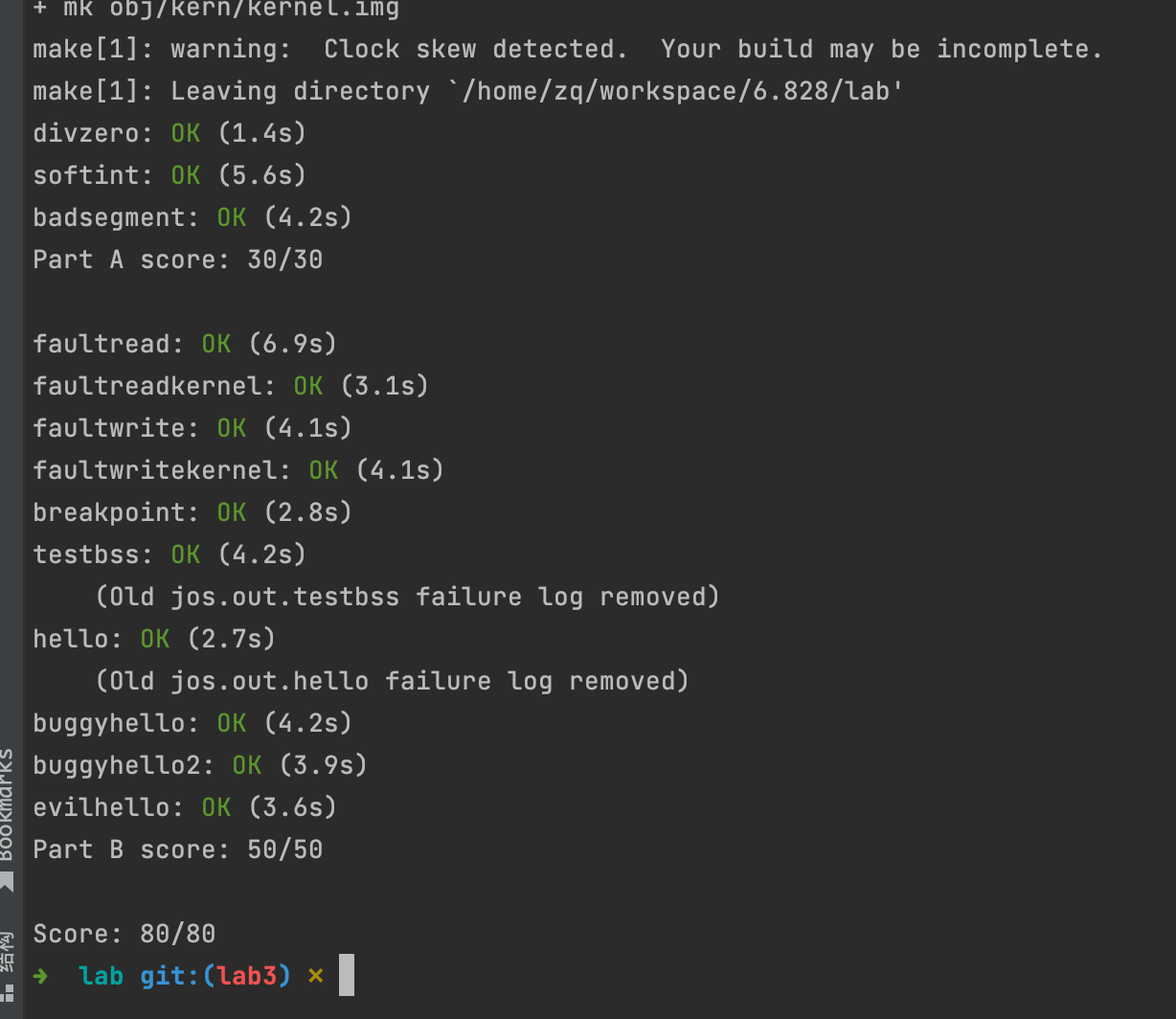
Test your trap handling code using some of the test programs in the user directory that cause exceptions before making any system calls, such as user/divzero. You should be able to get make grade to succeed on the divzero, softint, and badsegment tests at this point.
查看trapentry.s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/* TRAPHANDLER defines a globally-visible function for handling a trap. * It pushes a trap number onto the stack, then jumps to _alltraps. * Use TRAPHANDLER for traps where the CPU automatically pushes an error code. * * You shouldn't call a TRAPHANDLER function from C, but you may * need to _declare_ one in C (for instance, to get a function pointer * during IDT setup). You can declare the function with * void NAME(); * where NAME is the argument passed to TRAPHANDLER. */ #define TRAPHANDLER(name, num) \ .globl name; /* define global symbol for 'name' */ \ .type name, @function; /* symbol type is function */ \ .align 2; /* align function definition */ \ name: /* function starts here */ \ pushl $(num); \ jmp _alltraps
.global 定义了全局符号。
汇编函数如果需要在其他文件内调用,需要把函数声明为全局,此时就会使用.global这个伪操作。
.type 用来制定一个符号类型是函数类型或者是对象类型,对象类型一般是数据
.type symbol, @object
.type symbol, @function
.align 用来指定内存对齐方式
.align size
表示按size字节对齐内存
这一步做了什么?光看这里很难理解,提示说是构造一个 Trapframe 结构体来保存现场,但是这里怎么直接就 push 中断向量了?实际上,在上文已经指出, cpu 自身会先 push 一部分寄存器(见例子所述),而其他则由用户和操作系统决定。由于中断向量是操作系统定义的,所以从这部分开始就已经不属于 cpu 的工作范畴了。
// TRAPHANDLER defines a globally-visible function for handling a trap. // It pushes a trap number onto the stack, then jumps to _alltraps.
// Use TRAPHANDLER for traps where the CPU automatically pushes an error code. // Use TRAPHANDLER_NOEC for traps where the CPU doesn't push an error code.
/* * Lab 3: Your code here for generating entry points for the different traps. */ // 绑定异常到自定义处理器 TRAPHANDLER_NOEC(handler0, T_DIVIDE) TRAPHANDLER_NOEC(handler1, T_DEBUG) TRAPHANDLER_NOEC(handler2, T_NMI) TRAPHANDLER_NOEC(handler3, T_BRKPT) TRAPHANDLER_NOEC(handler4, T_OFLOW) TRAPHANDLER_NOEC(handler5, T_BOUND) TRAPHANDLER_NOEC(handler6, T_ILLOP) TRAPHANDLER_NOEC(handler7, T_DEVICE) TRAPHANDLER(handler8, T_DBLFLT) // 9 deprecated since 386 TRAPHANDLER(handler10, T_TSS) TRAPHANDLER(handler11, T_SEGNP) TRAPHANDLER(handler12, T_STACK) TRAPHANDLER(handler13, T_GPFLT) TRAPHANDLER(handler14, T_PGFLT) // 15 reserved by intel TRAPHANDLER_NOEC(handler16, T_FPERR) TRAPHANDLER(handler17, T_ALIGN) TRAPHANDLER_NOEC(handler18, T_MCHK) TRAPHANDLER_NOEC(handler19, T_SIMDERR) // system call (interrupt) TRAPHANDLER_NOEC(handler48, T_SYSCALL)
// Set up a normal interrupt/trap gate descriptor. // - istrap: 1 for a trap (= exception) gate, 0 for an interrupt gate. // see section 9.6.1.3 of the i386 reference: "The difference between // an interrupt gate and a trap gate is in the effect on IF (the // interrupt-enable flag). An interrupt that vectors through an // interrupt gate resets IF, thereby preventing other interrupts from // interfering with the current interrupt handler. A subsequent IRET // instruction restores IF to the value in the EFLAGS image on the // stack. An interrupt through a trap gate does not change IF." // - sel: 代码段选择器 for interrupt/trap handler // - off: 代码段的偏移量 for interrupt/trap handler // - dpl: Descriptor Privilege Level - // the privilege level required for software to invoke // this interrupt/trap gate explicitly using an int instruction. /* gate 这是一个 struct Gatedesc。 istrap 该中断是 trap(exception) 则为1,是 interrupt 则为0。 sel 代码段选择器。进入内核的话是 GD_KT。 off 相对于段的偏移,简单来说就是函数地址。 dpl(Descriptor Privileged Level) 权限描述符。 */ #define SETGATE(gate, istrap, sel, off, dpl) \ { \ (gate).gd_off_15_0 = (uint32_t) (off) & 0xffff; \ (gate).gd_sel = (sel); \ (gate).gd_args = 0; \ (gate).gd_rsv1 = 0; \ (gate).gd_type = (istrap) ? STS_TG32 : STS_IG32; \ (gate).gd_s = 0; \ (gate).gd_dpl = (dpl); \ (gate).gd_p = 1; \ (gate).gd_off_31_16 = (uint32_t) (off) >> 16; \ }
Challenge! You probably have a lot of very similar code right now, between the lists of TRAPHANDLER in trapentry.S and their installations in trap.c. Clean this up. Change the macros in trapentry.S to automatically generate a table for trap.c to use. Note that you can switch between laying down code and data in the assembler by using the directives .text and .data.
Questions
Answer the following questions in your answers-lab3.txt:
What is the purpose of having an individual handler function for each exception/interrupt? (i.e., if all exceptions/interrupts were delivered to the same handler, what feature that exists in the current implementation could not be provided?)
Did you have to do anything to make the user/softint program behave correctly? The grade script expects it to produce a general protection fault (trap 13), but softint‘s code says int $14. Why should this produce interrupt vector 13? What happens if the kernel actually allows softint‘s int $14instruction to invoke the kernel’s page fault handler (which is interrupt vector 14)?
Part B: Page Faults, Breakpoints Exceptions, and System Calls
staticvoid trap_dispatch(struct Trapframe *tf) { // Handle processor exceptions. // LAB 3: Your code here. switch(tf->tf_trapno){ case T_PGFLT: page_fault_handler(); break; default: // Unexpected trap: The user process or the kernel has a bug. print_trapframe(tf); if (tf->tf_cs == GD_KT) panic("unhandled trap in kernel"); else { env_destroy(curenv); // 销毁 return; } } }
Exercise 6: The Breakpoint Exception
断点异常,中断向量 3 (T_BRKPT) 允许调试器给程序加上断点。原理是暂时把程序中的某个指令替换为一个 1 字节大小的 int3软件中断指令。在 JOS 中,我们将它实现为一个伪系统调用。这样,任何程序(不限于调试器)都能使用断点功能。
Modify trap_dispatch() to make breakpoint exceptions invoke the kernel monitor. You should now be able to get make grade to succeed on the breakpoint test.
staticvoid trap_dispatch(struct Trapframe *tf)// dispatch 调度 { // Handle processor exceptions. // LAB 3: Your code here. switch(tf->tf_trapno){ case T_PGFLT: page_fault_handler(tf); break; case T_BRKPT: monitor(tf); break; default: // Unexpected trap: The user process or the kernel has a bug. print_trapframe(tf); if (tf->tf_cs == GD_KT) panic("unhandled trap in kernel"); else { env_destroy(curenv); // 销毁 return; } } }
Challenge! Modify the JOS kernel monitor so that you can ‘continue’ execution from the current location (e.g., after the int3, if the kernel monitor was invoked via the breakpoint exception), and so that you can single-step one instruction at a time. You will need to understand certain bits of the EFLAGS register in order to implement single-stepping.
Optional: If you’re feeling really adventurous, find some x86 disassembler source code - e.g., by ripping it out of QEMU, or out of GNU binutils, or just write it yourself - and extend the JOS kernel monitor to be able to disassemble and display instructions as you are stepping through them. Combined with the symbol table loading from lab 1, this is the stuff of which real kernel debuggers are made.
Questions
The break point test case will either generate a break point exception or a general protection fault depending on how you initialized the break point entry in the IDT (i.e., your call to SETGATE from trap_init). Why? How do you need to set it up in order to get the breakpoint exception to work as specified above and what incorrect setup would cause it to trigger a general protection fault?
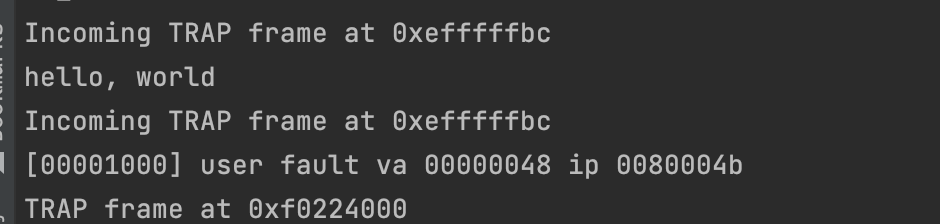
Run the user/hello program under your kernel (make run-hello). It should print “hello, world” on the console and then cause a page fault in user mode. If this does not happen, it probably means your system call handler isn’t quite right. You should also now be able to get make grade to succeed on the testbss test.
// Dispatches to the correct kernel function, passing the arguments. int32_t syscall(uint32_t syscallno, uint32_t a1, uint32_t a2, uint32_t a3, uint32_t a4, uint32_t a5) { // Call the function corresponding to the 'syscallno' parameter. // Return any appropriate return value. // LAB 3: Your code here.
//panic("syscall not implemented"); int32_t retVal = 0; switch (syscallno) { case SYS_cputs: sys_cputs((constchar *)a1, a2); break; case SYS_cgetc: retVal = sys_cgetc(); break; case SYS_getenvid: retVal = sys_getenvid()>=0; // // Returns the current environment's envid. break; case SYS_env_destroy: retVal = sys_env_destroy(a1); // env_id break; default: return -E_INVAL; } return retVal; }
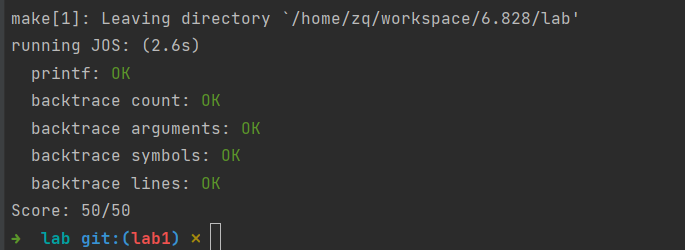
运行 make grade 可以通过 testbss,运行 make run-hello 可以打印出 hello world,紧接着提示了页错误。
通过 exercise 7,可以看出 JOS系 统调用的步骤为:
用户进程使用 inc/ 目录下暴露的接口
lib/syscall.c 中的函数将系统调用号及必要参数传给寄存器,并引起一次 int $0x30 中断
一个用户程序开始运行在lib/entry.S的顶部。在一些设置之后,这段代码调用lib/libmain.c中的libmain()。你应该修改libmain()来初始化全局指针thisenv,使其指向envs[]数组中的环境结构体Env。(Note that lib/entry.S has already defined envs to point at the UENVS mapping you set up in Part A.)
Hint: look in inc/env.h and use sys_getenvid.
libmain() then calls umain, which, in the case of the hello program, is in user/hello.c. Note that after printing “hello, world”, it tries to access thisenv->env_id. This is why it faulted earlier.
Now that you’ve initialized thisenv properly, it should not fault. If it still faults, you probably haven’t mapped the UENVS area user-readable (back in Part A in pmap.c; this is the first time we’ve actually used the UENVS area).
Add the required code to the user library, then boot your kernel. You should see user/hello print “hello, world“ and then print “i am environment 00001000“. user/hello then attempts to “exit” by calling sys_env_destroy() (see lib/libmain.c and lib/exit.c). Since the kernel currently only supports one user environment, it should report that it has destroyed the only environment and then drop into the kernel monitor. You should be able to get make grade to succeed on the hello test.
void libmain(int argc, char **argv) { // set thisenv to point at our Env structure in envs[]. // LAB 3: Your code here. thisenv = &envs[ENVX(sys_getenvid())]; // &envs[ENVX(envid)]
// save the name of the program so that panic() can use it if (argc > 0) binaryname = argv[0];
Change kern/trap.c to panic if a page fault happens in kernel mode.
Hint: to determine whether a fault happened in user mode or in kernel mode, check the low bits of the tf_cs. (tf_cs是0x18还是0x1b, 0x18|0x03 = 0x1b此时是用户模式,0x18是内核模式,检查&3后的低2位)
Read user_mem_assert in kern/pmap.c and implement user_mem_check in that same file.
Change kern/syscall.c to sanity check arguments to system calls.
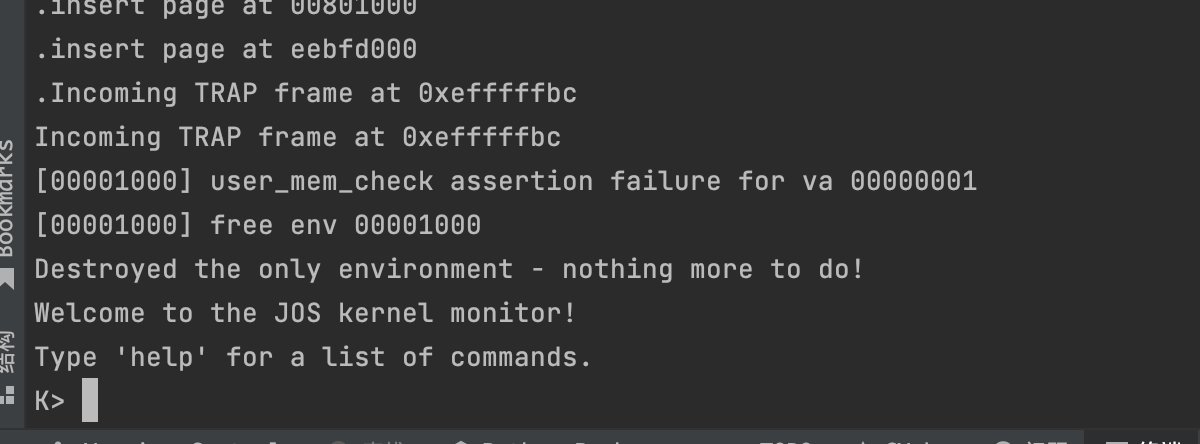
Boot your kernel, running user/buggyhello. The environment should be destroyed, and the kernel should not panic. You should see:
1 2 3 4
[00001000] user_mem_check assertion failure for va 00000001 [00001000] free env 00001000 Destroyed the only environment - nothing more to do!
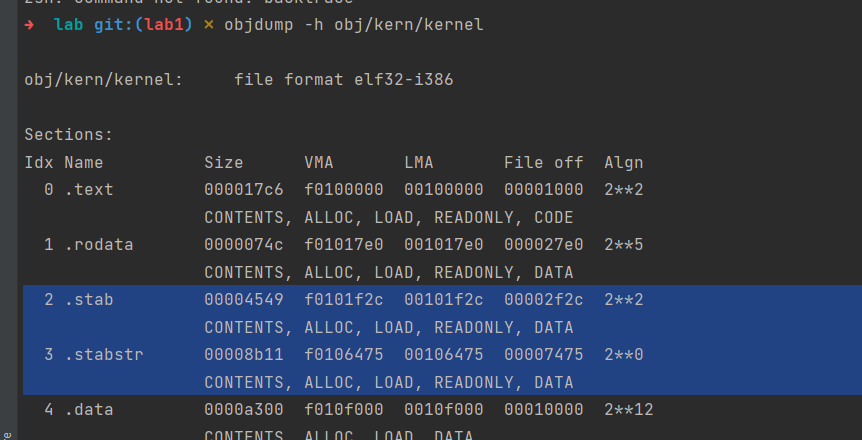
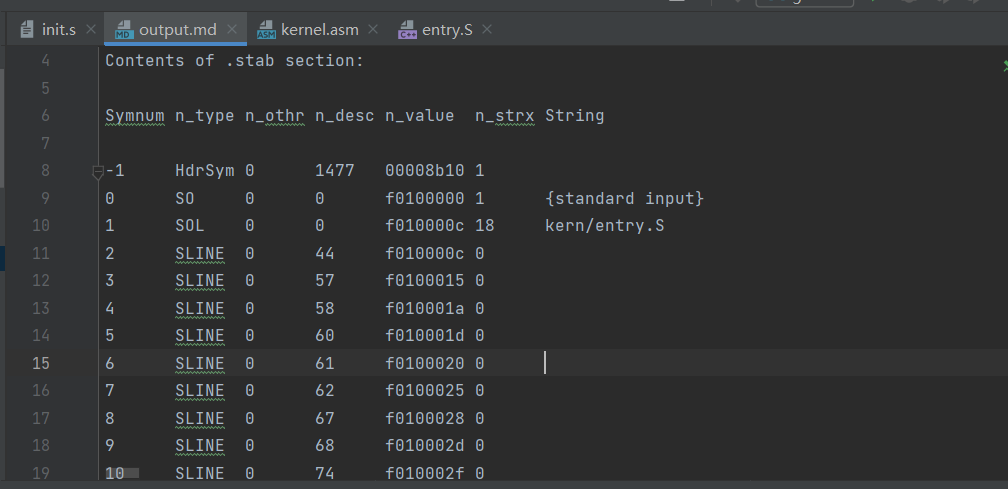
Finally, change debuginfo_eip in kern/kdebug.c to call user_mem_check on usd, stabs, and stabstr. If you now run user/breakpoint, you should be able to run backtrace from the kernel monitor and see the backtrace traverse into lib/libmain.c before the kernel panics with a page fault. What causes this page fault? You don’t need to fix it, but you should understand why it happens.
// Read processor's CR2 register to find the faulting address fault_va = rcr2();
// Handle kernel-mode page faults. // LAB 3: Your code here. if(!(tf->tf_cs & 3)){ panic("page fault in kernel mode."); } // We've already handled kernel-mode exceptions, so if we get here, // the page fault happened in user mode.
// Destroy the environment that caused the fault. cprintf("[%08x] user fault va %08x ip %08x\n", curenv->env_id, fault_va, tf->tf_eip); print_trapframe(tf); env_destroy(curenv); }
// // Checks that environment 'env' is allowed to access the range // of memory [va, va+len) with permissions 'perm | PTE_U | PTE_P'. // If it can, then the function simply returns. // If it cannot, 'env' is destroyed and, if env is the current // environment, this function will not return. // void user_mem_assert(struct Env *env, constvoid *va, size_t len, int perm) { if (user_mem_check(env, va, len, perm | PTE_U) < 0) { cprintf("[%08x] user_mem_check assertion failure for " "va %08x\n", env->env_id, user_mem_check_addr); env_destroy(env); // may not return } }
调用了user_mem_check(),不满足则摧毁页面
运行 make run-buggyhello-nox
[00001000] user_mem_check assertion failure for va 00000001
[00001000] free env 00001000
Destroyed the only environment - nothing more to do!
最后,change debuginfo_eip in kern/kdebug.c to call user_mem_check on usd, stabs, and stabstr.
kclock.c and kclock.h manipulate the PC’s battery-backed clock and CMOS RAM hardware, in which the BIOS records the amount of physical memory the PC contains, among other things.
staticvoid * boot_alloc(uint32_t n) { staticchar *nextfree; // virtual address of next byte of free memory char *result;
// Initialize nextfree if this is the first time. // 'end' is a magic symbol automatically generated by the linker, // which points to the end of the kernel's bss segment: // the first virtual address that the linker did *not* assign // to any kernel code or global variables. if (!nextfree) { externchar end[]; nextfree = ROUNDUP((char *) end, PGSIZE); }
// Allocate a chunk large enough to hold 'n' bytes, then update // nextfree. Make sure nextfree is kept aligned // to a multiple of PGSIZE. // // LAB 2: Your code here. if (n == 0) { // if n == 0, returns the address of the next free page without allocating anything. return nextfree; } // n > 0 分配足够的连续物理内存页以容纳〞n”个字节。returns a kernel virtual address. result = nextfree; nextfree += ROUNDUP(n, PGSIZE); // Round up to the nearest multiple of PGSIZE return result; }
////////////////////////////////////////////////////////////////////// // Recursively insert PD in itself as a page table, to form // a virtual page table at virtual address UVPT. // (For now, you don't have understand the greater purpose of the // following line.)
// Permissions: kernel R, user R kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P;
////////////////////////////////////////////////////////////////////// // Allocate an array of npages 'struct PageInfo's and store it in 'pages'. // The kernel uses this array to keep track of physical pages: for // each physical page, there is a corresponding struct PageInfo in this // array. 'npages' is the number of physical pages in memory. Use memset // to initialize all fields of each struct PageInfo to 0. // Your code goes here: // 创建一个struct PageInfo 的数组 // kernel 使用这个数组来耿总每个物理页 // 对于每一个物理页,都会有一个对应的 struct PageInfo 在数组中 pages = (struct PageInfo *) boot_alloc(npages * sizeof(struct PageInfo)); // npages 是内存中物理页的数量 memset(pages, 0, npages * sizeof(struct PageInfo));
////////////////////////////////////////////////////////////////////// // Now that we've allocated the initial kernel data structures, we set // up the list of free physical pages. Once we've done so, all further // memory management will go through the page_* functions. In // particular, we can now map memory using boot_map_region // or page_insert page_init();
////////////////////////////////////////////////////////////////////// // Now we set up virtual memory
////////////////////////////////////////////////////////////////////// // Map 'pages' read-only by the user at linear address UPAGES // Permissions: // - the new image at UPAGES -- kernel R, user R // (ie. perm = PTE_U | PTE_P) // - pages itself -- kernel RW, user NONE // Your code goes here:
////////////////////////////////////////////////////////////////////// // Use the physical memory that 'bootstack' refers to as the kernel // stack. The kernel stack grows down from virtual address KSTACKTOP. // We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP) // to be the kernel stack, but break this into two pieces: // * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory // * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if // the kernel overflows its stack, it will fault rather than // overwrite memory. Known as a "guard page". // Permissions: kernel RW, user NONE // Your code goes here:
////////////////////////////////////////////////////////////////////// // Map all of physical memory at KERNBASE. // Ie. the VA range [KERNBASE, 2^32) should map to // the PA range [0, 2^32 - KERNBASE) // We might not have 2^32 - KERNBASE bytes of physical memory, but // we just set up the mapping anyway. // Permissions: kernel RW, user NONE // Your code goes here:
// Check that the initial page directory has been set up correctly. check_kern_pgdir();
// Switch from the minimal entry page directory to the full kern_pgdir // page table we just created. Our instruction pointer should be // somewhere between KERNBASE and KERNBASE+4MB right now, which is // mapped the same way by both page tables. // // If the machine reboots at this point, you've probably set up your // kern_pgdir wrong. lcr3(PADDR(kern_pgdir));
check_page_free_list(0);
// entry.S set the really important flags in cr0 (including enabling // paging). Here we configure the rest of the flags that we care about. cr0 = rcr0(); cr0 |= CR0_PE | CR0_PG | CR0_AM | CR0_WP | CR0_NE | CR0_MP; cr0 &= ~(CR0_TS | CR0_EM); lcr0(cr0);
// Some more checks, only possible after kern_pgdir is installed. check_page_installed_pgdir(); }
void page_init(void) { // The example code here marks all physical pages as free. // However this is not truly the case. What memory is free? size_t i; // 1) Mark physical page 0 as in use. // This way we preserve the real-mode IDT and BIOS structures // in case we ever need them. (Currently we don't, but...) // 将页 0 标记为使用状态 pages[0].pp_ref = 1; // 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE) // is free. // 剩下的标为空闲状态 for(i = 1;i<npages_basemem;++i){ pages[i].pp_ref = 0; pages[i].pp_link = page_free_list; page_free_list = &pages[i]; } // 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must // never be allocated. // io端口, 不能被分配 for(i = IOPHYSMEM/PGSIZE;i<EXTPHYSMEM/PGSIZE;++i){ pages[i].pp_ref = 1; }
// 4) Then extended memory [EXTPHYSMEM, ...). // Some of it is in use, some is free. Where is the kernel // in physical memory? Which pages are already in use for // page tables and other data structures? // // Change the code to reflect this. // NB: DO NOT actually touch the physical memory corresponding to // free pages! // 找到第一个能分配的页面 // boot_alloc有个 nextfree指针,但是是虚拟地址,我们要将其转换为物理地址 physical address // PADDR 可以实现地址的转换 size_t first_free_address = PADDR(boot_alloc(0)); // 看看extend physical memory 是不是free for(i = EXTPHYSMEM/PGSIZE;i<first_free_address/PGSIZE;++i){ pages[i].pp_ref = 1; } // 把页面设为空闲,插入链表头部 for (i = first_free_address/PGSIZE; i < npages; i++) { pages[i].pp_ref = 0; pages[i].pp_link = page_free_list; page_free_list = &pages[i]; } }
(This function should only be called when pp->pp_ref reaches 0.)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// Return a page to the free list. // (This function should only be called when pp->pp_ref reaches 0.) // void page_free(struct PageInfo *pp){ // Fill this function in // Hint: You may want to panic if pp->pp_ref is nonzero or // pp->pp_link is not NULL. if(pp->pp_ref>0 || pp->pp_link!=NULL){ panic("Double check failed when dealloc page"); return; } pp->pp_link = page_free_list; // 头插 page_free_list = pp; }
使用 make qemu-nox 运行,发现报了个panic, 需要把panic注释掉。看漏了
Part 2: Virtual Memory
虚拟内存 当 cpu 拿到一个地址并根据地址访问内存时,在 x86架构下药经过至少两级的地址变换:段式变换和页式变换。分段机制的主要目的是将代码段、数据段以及堆栈段分开,保证互不干扰。分页机制则是为了实现虚拟内存。 虚拟内存主要的好处是:
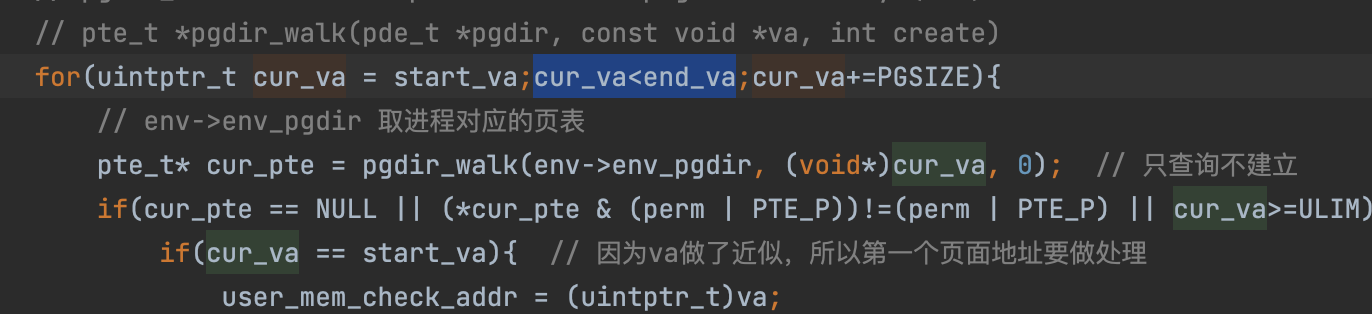
// Given 'pgdir', a pointer to a page directory, pgdir_walk returns // a pointer to the page table entry (PTE) for linear address 'va'. // This requires walking the two-level page table structure. // // The relevant page table page might not exist yet. // If this is true, and create == false, then pgdir_walk returns NULL. // Otherwise, pgdir_walk allocates a new page table page with page_alloc. // - If the allocation fails, pgdir_walk returns NULL. // - Otherwise, the new page's reference count is incremented, // the page is cleared, // and pgdir_walk returns a pointer into the new page table page. // // Hint 1: you can turn a PageInfo * into the physical address of the // page it refers to with page2pa() from kern/pmap.h. // // Hint 2: the x86 MMU checks permission bits in both the page directory // and the page table, so it's safe to leave permissions in the page // directory more permissive than strictly necessary. // // Hint 3: look at inc/mmu.h for useful macros that manipulate page // table and page directory entries. // // typedef uint32_t pte_t; // pgdir_walk returns a pointer to the page table entry (PTE) for linear address 'va'. pte_t * pgdir_walk(pde_t *pgdir, constvoid *va, int create) { // Fill this function in // pgdir 页目录项地址 // va 虚拟地址,jos只有一个段,因此虚拟地址等于线性地址 // create 若页目录项不存在是否创建 // return 页表项指针 uint32_t page_dir_index = PDX(va); uint32_t page_table_index = PTX(va);
Map [va, va+size) of virtual address space to physical [pa, pa+size) in the page table rooted at pgdir. Size is a multiple of PGSIZE, and va and pa are both page-aligned. This function is only intended to set up the ``static'' mappings above UTOP. As such, it should *not* change the pp_ref field on the mapped pages.
// Return the page mapped at virtual address 'va'. // If pte_store is not zero, then we store in it the address // of the pte for this page. This is used by page_remove and // can be used to verify page permissions for syscall arguments, // but should not be used by most callers. // // Return NULL if there is no page mapped at va. // // Hint: the TA solution uses pgdir_walk and pa2page. // // 返回映射到虚拟地址 va 的页面 // pgdir_walk 只查询,不创建,create为0 // pa2page 由物理地址 返回对应的页面描述 struct PageInfo * page_lookup(pde_t *pgdir, void *va, pte_t **pte_store) { // Fill this function in // pdgir 页目录地址 // va 虚拟地址 // pte_store 指向页表指针的指针 the address of the pte for this page // If pte_store is not zero, then we store in it the address of the pte for this page. pde_t* find_pgtab = pgdir_walk(pgdir, va, 0); // 根据va,返回一个指向page table entry的指针 if(!find_pgtab){ // 没找到 returnNULL; } // 找到了 // 再找page table的虚拟地址 if(pte_store){ *pte_store = find_pgtab; // 保存下 } // 返回页面描述 struct PageInfo * return pa2page(PTE_ADDR(*find_pgtab)); // PTE_ADDR 将页表指针指向的内容转为物理地址 }
// // Unmaps the physical page at virtual address 'va'. // If there is no physical page at that address, silently does nothing. // // Details: // - The ref count on the physical page should decrement. // - The physical page should be freed if the refcount reaches 0. // - The pg table entry corresponding to 'va' should be set to 0. // (if such a PTE exists) // - The TLB must be invalidated if you remove an entry from // the page table. // // Hint: The TA solution is implemented using page_lookup, // tlb_invalidate, and page_decref. // // 移除一个虚拟地址与对应物理地址的映射关系 void page_remove(pde_t *pgdir, void *va) { // Fill this function in // pgdir 页目录地址 // va 虚拟地址 // 首先要找到 va对应的物理地址, 使用 page_lookup // page_lookup(pde_t *pgdir, void *va, pte_t **pte_store) pte_t* pgtab; pte_t** pte_store = &pgtab; structPageInfo* pInfo = page_lookup(pgdir, va, pte_store); if(!pInfo){ // 空的 return; } page_decref(pInfo); // 减少页上的引用计数,如果没有引用则释放该计数。 *pgtab = 0; // tlb_invalidate(pde_t *pgdir, void *va) tlb_invalidate(pgdir, va); // 使TLB条目无效,但前提是正在编辑的页表是当前处理器正在使用的页表。 }
page_insert()
建立一个虚拟地址与物理页的映射,与page_remove() 对应。
The permissions (the low 12 bits) of the page table entry should be set to ‘perm|PTE_P’.
// // Map [va, va+size) of virtual address space to physical [pa, pa+size) // in the page table rooted at pgdir. Size is a multiple of PGSIZE, and // va and pa are both page-aligned. // Use permission bits perm|PTE_P for the entries. // // This function is only intended to set up the ``static'' mappings // above UTOP. As such, it should *not* change the pp_ref field on the // mapped pages. // // Hint: the TA solution uses pgdir_walk // 映射一片虚拟页到指定物理页,大小为size, size是PGSIZE的倍数 // va -> pa staticvoid boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm) { // Fill this function in // *pgdir 页目录指针 // va 虚拟地址 // size size是PGSIZE的倍数, // pa 物理地址 // perm 权限 // 直接使用页数来分配,避免溢出 pte_t* pgtab; size_t pg_count = PGNUM(size); // size能分成多少页 // pte_t* pgdir_walk(pde_t *pgdir, const void *va, int create) for(size_t i = 0;i<pg_count;++i){ pgtab = pgdir_walk(pgdir, (void*)va, 1); // pgdir_walk returns a pointer to the page table entry (PTE) for linear address 'va'. *pgtab = pa | perm | PTE_P; // 权限 va+=PGSIZE; pa+=PGSIZE; }
////////////////////////////////////////////////////////////////////// // Map 'pages' read-only by the user at linear address UPAGES // Permissions: // - the new image at UPAGES -- kernel R, user R // (ie. perm = PTE_U | PTE_P) // - pages itself -- kernel RW, user NONE // Your code goes here: // UPAGES是JOS记录物理页面使用情况的数据结构,只有kernel能够访问 // 但是现在需要让用户空间能够读取这段线性地址,因此需要建立映射,将用户空间的一块内存映射到存储该数据结构的物理地址上 // boot_map_region() 建立映射关系 boot_map_region(kern_pgdir, (uintptr_t)UPAGES, npages*sizeof(struct PageInfo), PADDR(pages), PTE_U | PTE_P); // 目前建立了一个页目录,kernel_pgdir // pgdir为页目录指针, UPAGES为虚拟地址,npages*sizeof(struct* PageInfo)为映射的内存块大小 // PADDR(pages) 为物理地址, PTE_U | PTE为权限 (PTE_U 表示用户可读)
////////////////////////////////////////////////////////////////////// // Use the physical memory that 'bootstack' refers to as the kernel // stack. The kernel stack grows down from virtual address KSTACKTOP. // We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP) // to be the kernel stack, but break this into two pieces: // * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory // * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if // the kernel overflows its stack, it will fault rather than // overwrite memory. Known as a "guard page". // Permissions: kernel RW, user NONE // Your code goes here: // kernel 内核栈 // kernel stack 从虚拟地址 KSTACKTOP 开始,向低地址增长,所以KSTACKTOP实际上是栈顶 // KSTACKTOP = 0xf0000000, // KSTKSIZE = (8*PGSIZE) = 8*4096(bytes) = 32KB // 只需要映射 [KSTACKTOP, KSTACKTOP - KSTKSIZE) 范围的虚拟地址 boot_map_region(kern_pgdir, (uintptr_t)(KSTACKTOP - KSTKSIZE), KSTKSIZE, PADDR(bootstack), PTE_W | PTE_P); // PTE_W 开启了写权限,但是并未打开 PTE_U, 因此用户没有权限,只有内核有权限
////////////////////////////////////////////////////////////////////// // Map all of physical memory at KERNBASE. // Ie. the VA range [KERNBASE, 2^32) should map to // the PA range [0, 2^32 - KERNBASE) // We might not have 2^32 - KERNBASE bytes of physical memory, but // we just set up the mapping anyway. // Permissions: kernel RW, user NONE // Your code goes here: // 内核部分 // KERNBASE = 0xF0000000, VA大小为 2^32 - KERNBASE // ROUNDUP(a,n) 将a四舍五入到最接近n的倍数 boot_map_region(kern_pgdir, (uintptr_t)KERNBASE, ROUNDUP(0xffffffff - KERNBASE + 1, PGSIZE), 0, PTE_W | PTE_P);
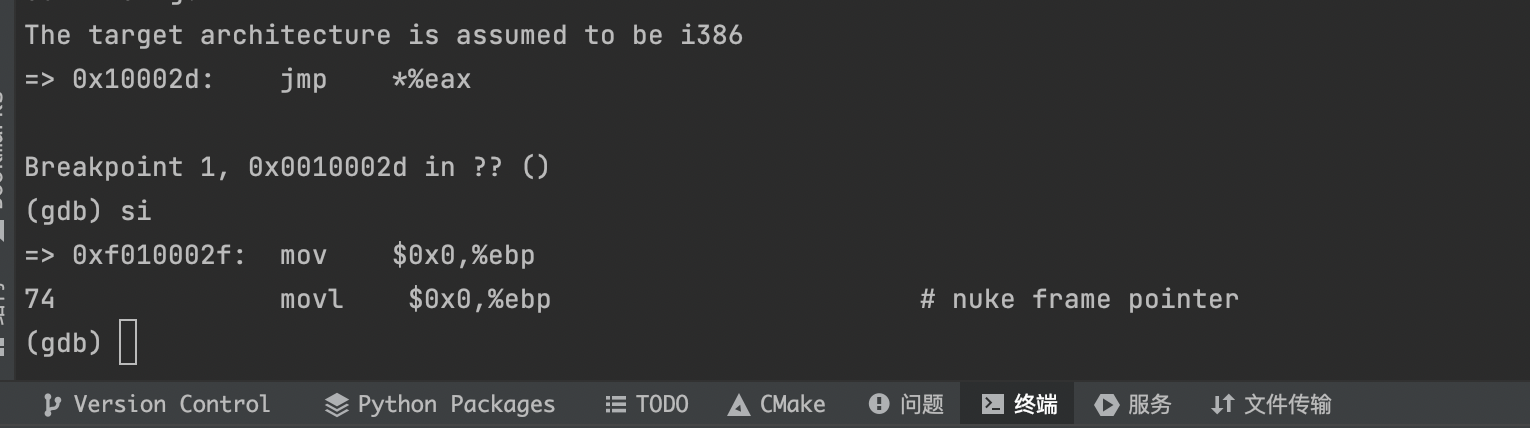
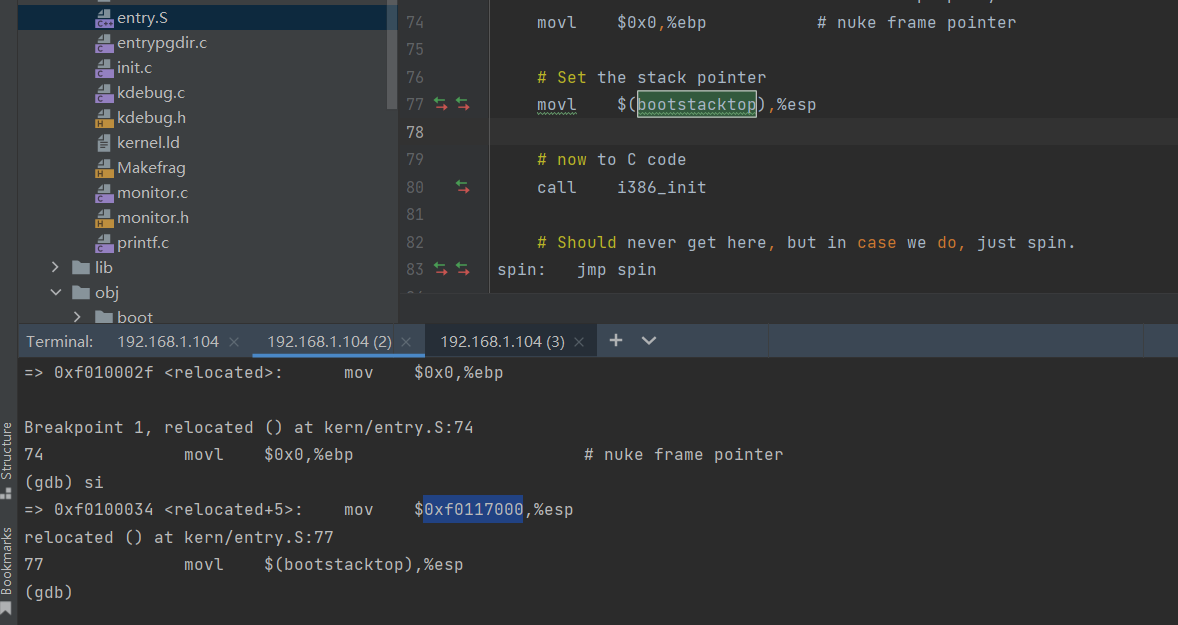
重新访问kern/entry.S和kern/entrypgdir.c中的页面表设置。在我们打开分页后,EIP仍然是一个低数字(略高于1MB)。我们什么时候过渡到KERNBASE上方的EIP运行?when we enable paging and when we begin running at an EIP above KERNBASE,是什么使我们能够继续以低EIP执行?为什么需要这种过渡?
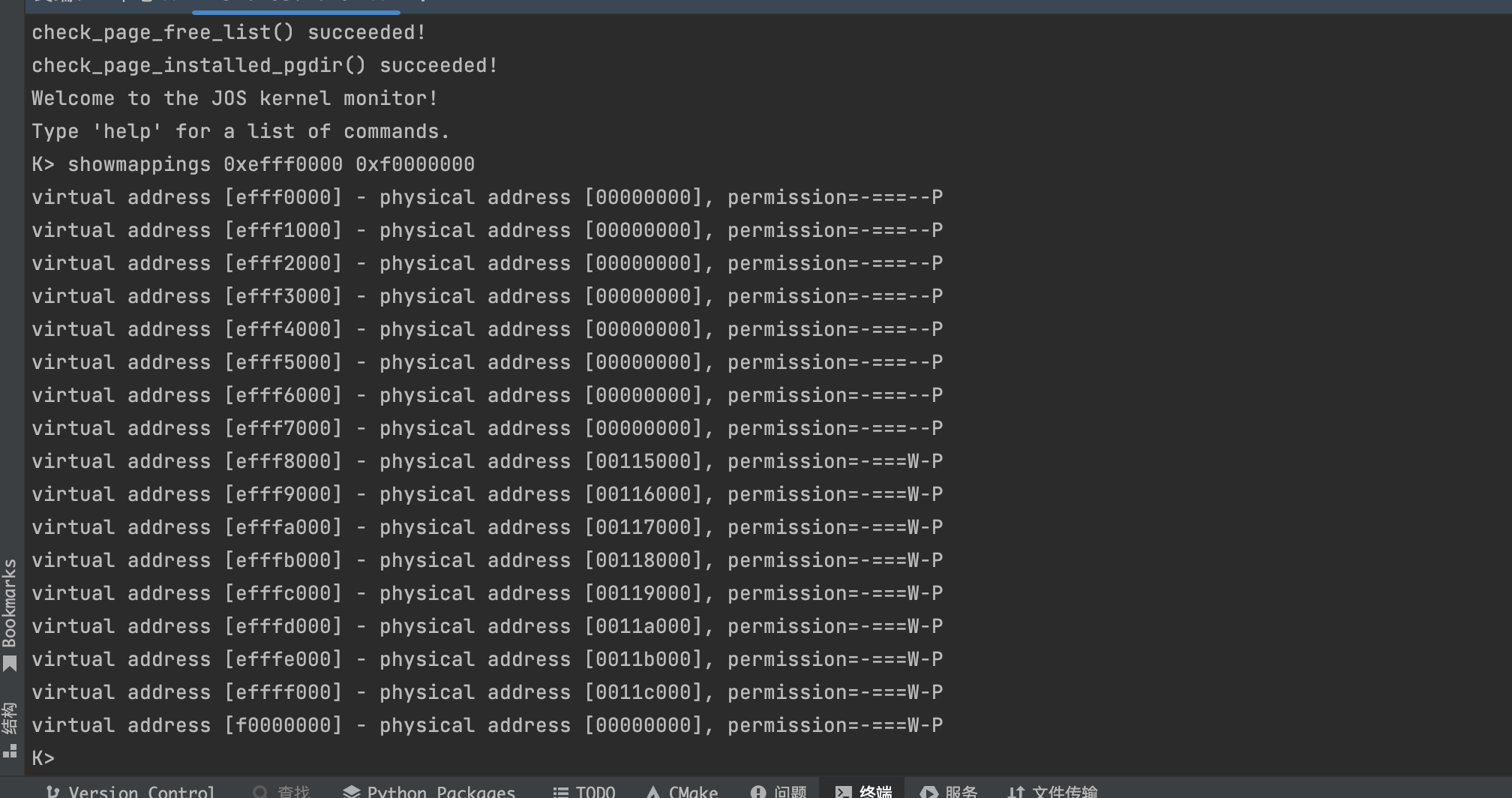
Display in a useful and easy-to-read format all of the physical page mappings (or lack thereof) that apply to a particular range of virtual/linear addresses in the currently active address space. For example, you might enter 'showmappings 0x3000 0x5000' to display the physical page mappings and corresponding permission bits that apply to the pages at virtual addresses 0x3000, 0x4000, and 0x5000.
inttotalFruit(vector<int>& fruits){ int n = fruits.size(); unordered_map<int, int> mp; int j = 0; // 记录需要删除水果的起始下标 int k = 2; int ans = 0; for (int i = 0; i < n; ++i) { if (mp[fruits[i]] == 0) { // 没使用过 --k; } mp[fruits[i]]++; while (k < 0) { // 有新水果进来,篮子已超出了两个 // 直至删除空了一种水果,画图好理解 mp[fruits[j]]--; if (mp[fruits[j]] == 0) { ++k; } j++; } ans = max(ans, i - j + 1); } return ans; }
# Jump to next instruction, but in 32-bit code segment. # Switches processor into 32-bit mode. ljmp $PROT_MODE_CSEG, $protcseg 7c2d: ea 32 7c 08 00 66 b8 ljmp $0xb866,$0x87c32
for (; ph < eph; ph++) readseg(ph->p_pa, ph->p_memsz, ph->p_offset);
ph是个struct Proghdr类型的指针,直接++让地址的值前进相应地址长度,非常方便。
至此,内核完全加载完毕。
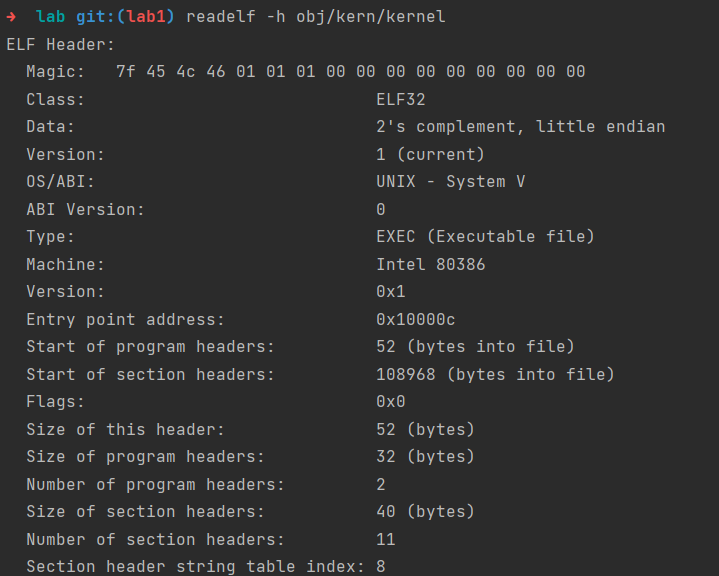
获取kernel ELF文件的相关信息:
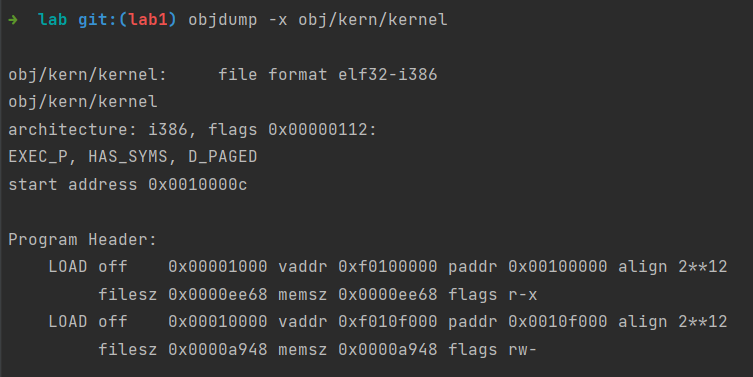
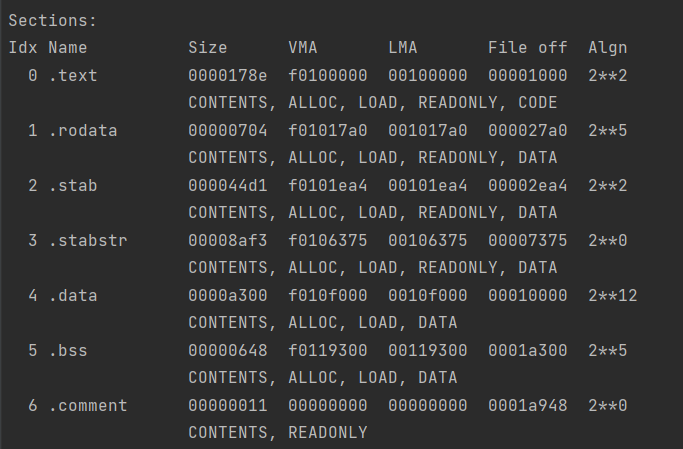
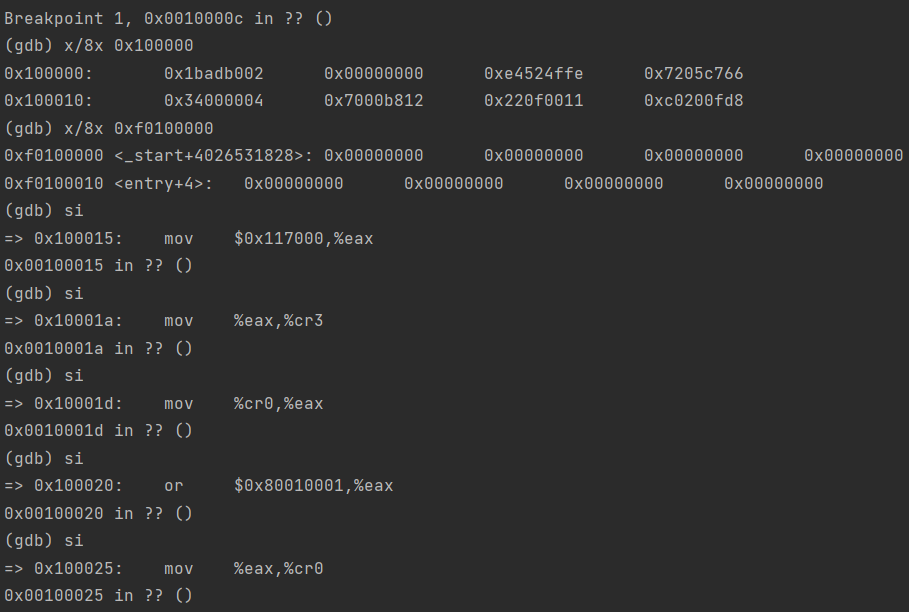
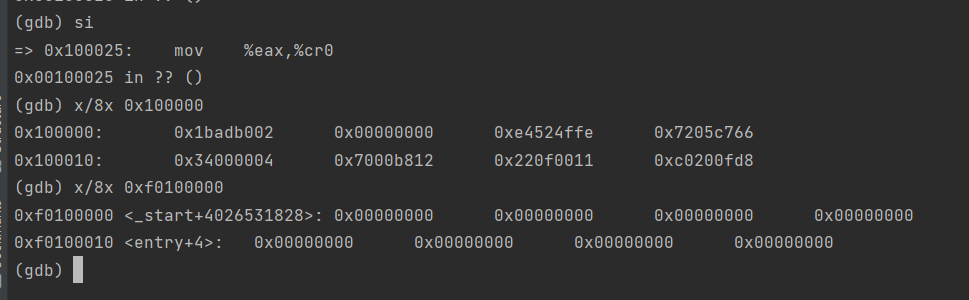
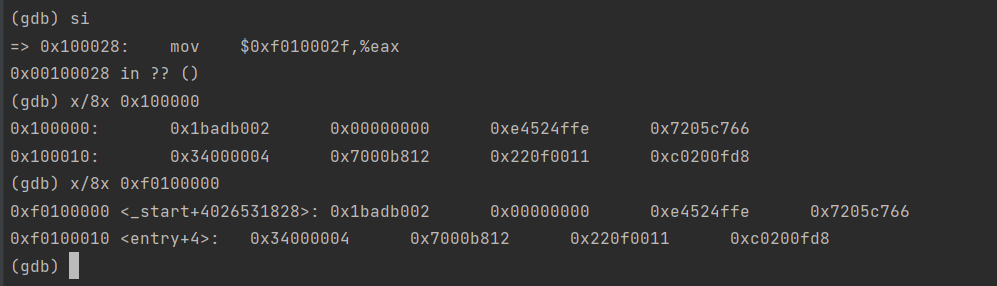
可看到程序入口的虚拟地址是0x10000c,程序头表偏移为52B,程序头表条目是2.
如果你得到一个错误的引导加载器链接地址,通过再次跟踪引导加载器的前几个指令,你将会发现第一个指令会 “中断” 或者出错。然后在 boot/Makefrag 修改链接地址来修复错误,运行 make clean,使用 make 重新编译,然后再次跟踪引导加载器去查看会发生什么事情。不要忘了改回正确的链接地址,然后再次 make clean!
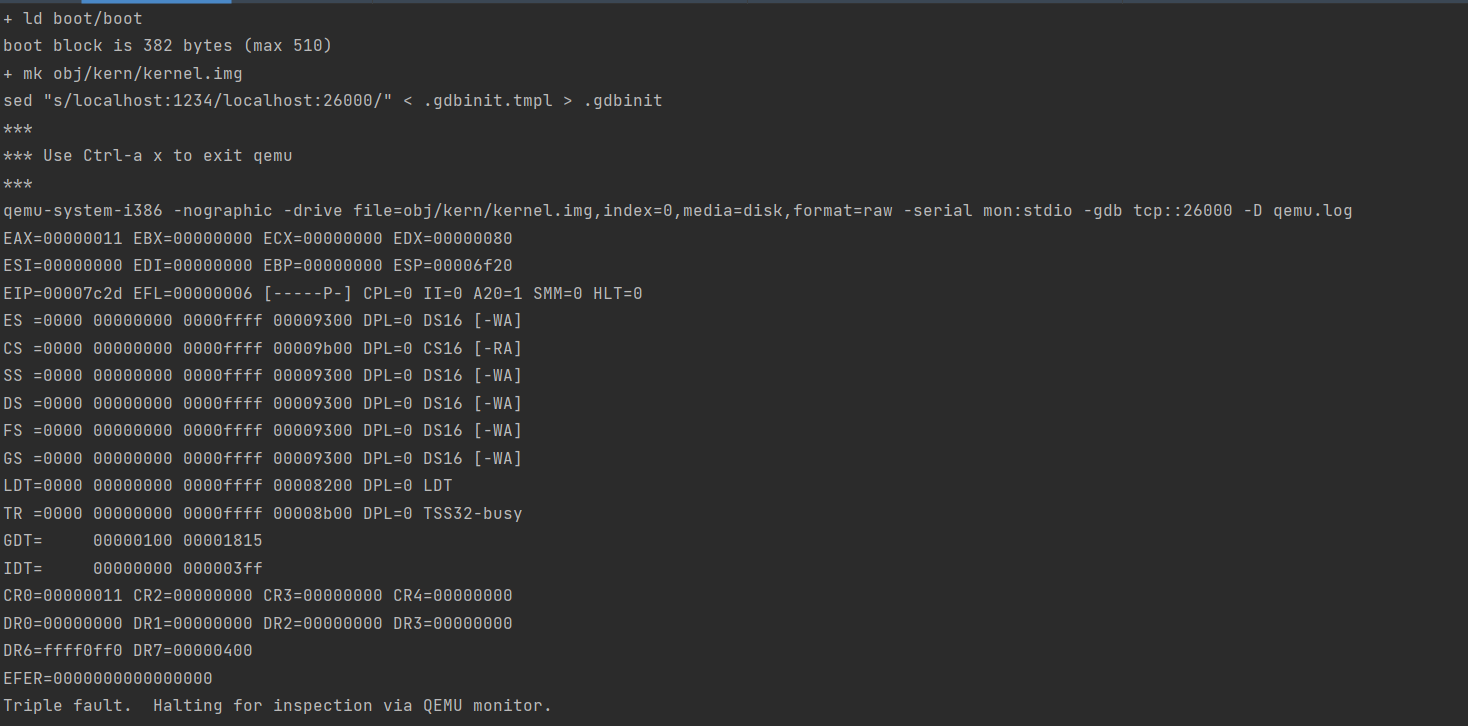
修改0x7C00为0x7d00,使得bootloader无法正确加载。
可能就是GDT表加载错误才导致后面加载失败,因为加载信息都错掉了。
Exercise 6
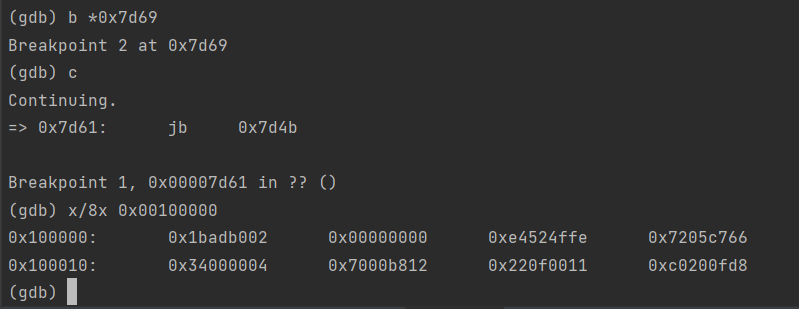
在BIOS进入 the boot loader时检查内存0x00100000处的8个字,然后在 the boot loader进入内核时再检查一次。
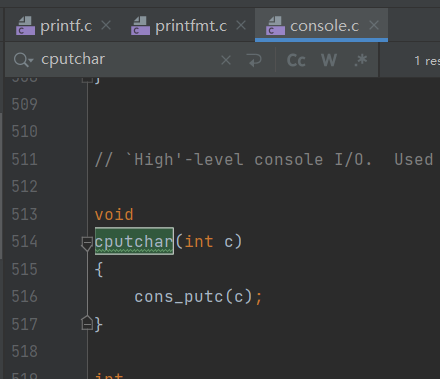
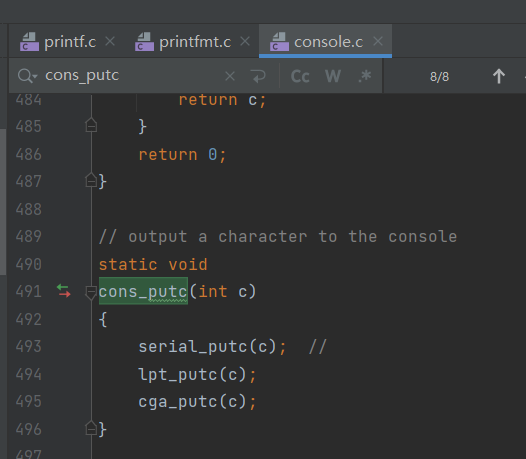
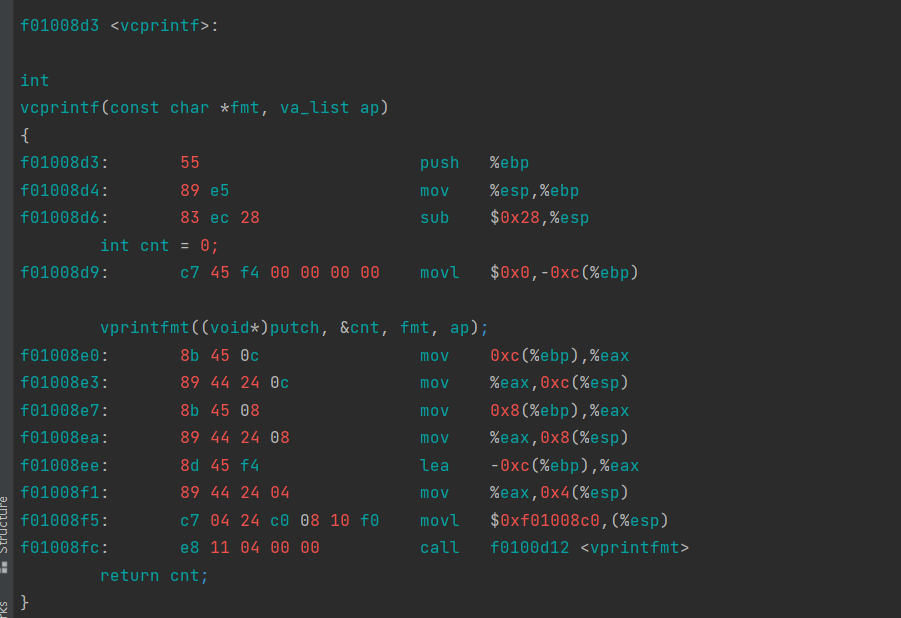
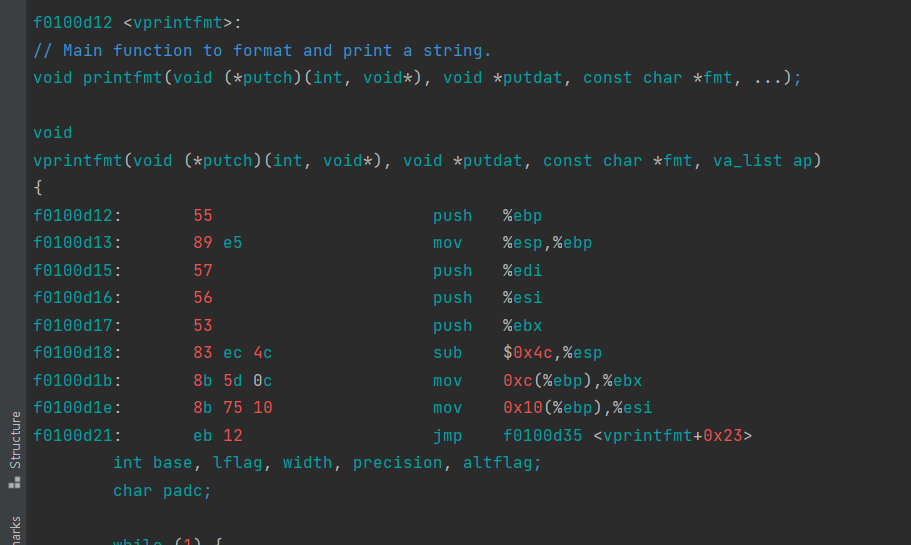
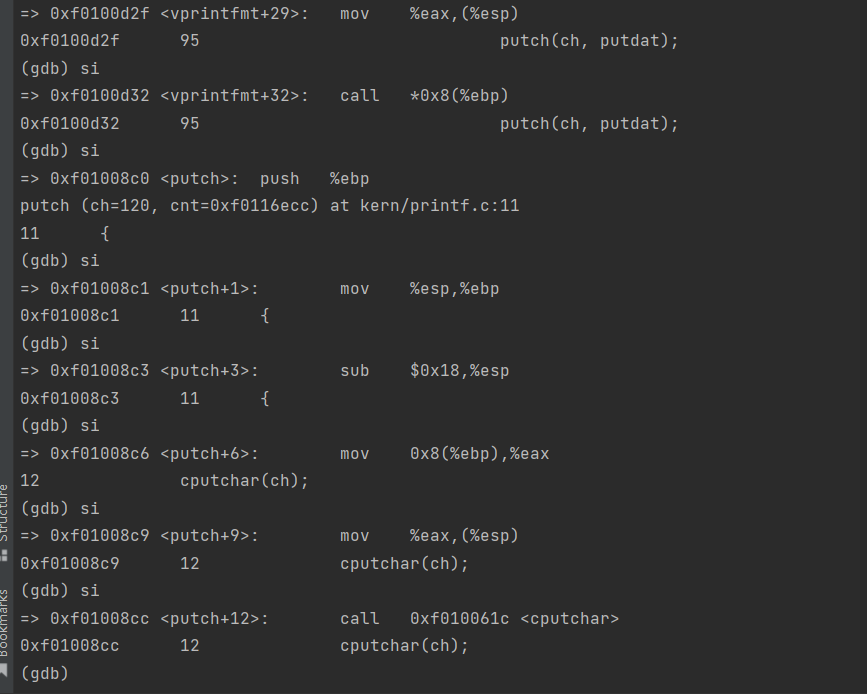
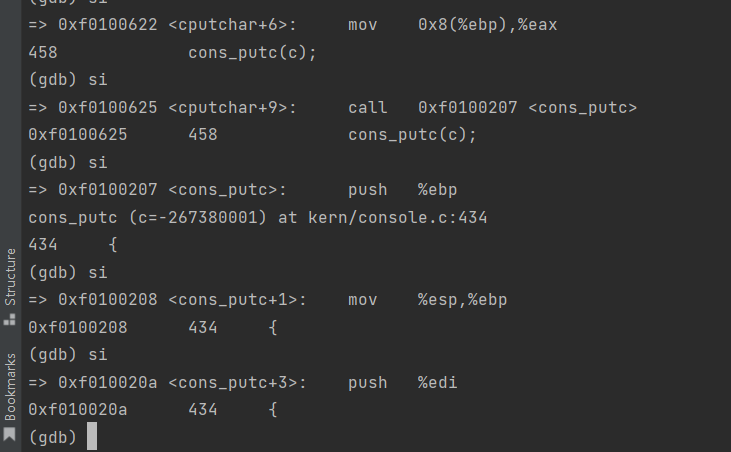
// printf.c // Simple implementation of cprintf console output for the kernel, // based on printfmt() and the kernel console's cputchar(). //为内核简单实现cprintf控制台输出, //基于printfmt()和内核控制台的cputchar()。
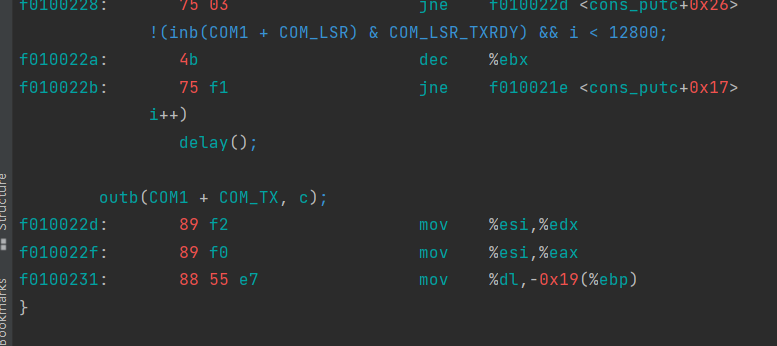
/* * 03FD r line status register bit 7 = 0 reserved bit 6 = 1 transmitter shift and holding registers empty bit 5 = 1 transmitter holding register empty. Controller is ready to accept a new character to send. bit 4 = 1 break interrupt. the received data input is held in in the zero bit state longer than the time of start bit + data bits + parity bit + stop bits. bit 3 = 1 framing error. the stop bit that follows the last parity or data bit is a zero bit. bit 2 = 1 parity error. Character has wrong parity bit 1 = 1 overrun error. a character was sent to the receiver buffer before the previous character in the buffer could be read. This destroys the previous character. bit 0 = 1 data ready. a complete incoming character has been received and sent to the receiver buffer register. * */ staticvoid serial_putc(int c) { int i; // COM1 = 0x3F8, COM_LSR(Line Status Register) = 5, COM_LSR_TXRDY(传输缓冲区) = 0x20, // 0x03F8 + 5 => 0x03FD 0x03FD & 0x20(0010 0000) => 取 bit 5 // bti 5 = 1 : // transmitter holding register empty. Controller is ready to accept a new character to send. // 如果bit 5 = 1,那么传输方寄存器已空,controller可以接受一个新的字符了 for (i = 0; !(inb(COM1 + COM_LSR) & COM_LSR_TXRDY) && i < 12800; // bit 5 != 1 && 没超时 i++) delay(); //COM_TX = 0 Out: Transmit buffer //serial_putc()函数的功能首先就是在bit 5 =1 的时候,跳出循环,否则只要 i <12800就会一直循环等待。 outb(COM1 + COM_TX, c); // 将c写入I/O端口 }
/***** Parallel port output code *****/ // For information on PC parallel port programming, see the class References // page. // 并行端口输入 /* 0x378~0x37A parallel printer port 0378 w data port 0379 r/w status port bit 7 = 0 busy * 0x80 bit 6 = 0 acknowledge bit 5 = 1 out of paper bit 4 = 1 printer is selected bit 3 = 0 error bit 2 = 0 IRQ has occurred bit 1-0 reserved 037A r/w control port bit 7-5 reserved bit 4 = 1 enable IRQ bit 3 = 1 select printer * 0x08 bit 2 = 0 initialize printer *0x04 bit 1 = 1 automatic line feed bit 0 = 1 strobe * 0x01 */ staticvoid lpt_putc(int c)// 并行端口输入 { int i; // 0x379 & 0x80 读取0x379的内容,和0x80相与,取bits 7,判断是否繁忙 for (i = 0; !(inb(0x378+1) & 0x80) && i < 12800; i++) // io端口不繁忙且未超时,一直等待,直到使用了端口或等待时间到 delay(); outb(0x378+0, c); // write char c outb(0x378+2, 0x08|0x04|0x01); //初始化 printer outb(0x378+2, 0x08); // 选择 printer }
staticvoid cga_putc(int c) { // if no attribute given, then use black on white // 如果没有给定属性,则使用黑白相间的颜色 if (!(c & ~0xFF)) // c 低16位为字符值,高16位为显示属性 c |= 0x0700; // crt_pos:当前输出位置指针,指向内存区中对应输出映射地址。 switch (c & 0xff) { // 取低16位 case'\b': // backspace if (crt_pos > 0) { crt_pos--; crt_buf[crt_pos] = (c & ~0xff) | ' '; // 删除处使用' '填充 } break; case'\n': // //new line:换行, 自动添加回车 crt_pos += CRT_COLS; // CRT_COLS默认输出格式下整个屏幕的列数,为80。 // CRT_ROWS:默认输出格式下整个屏幕的行数,为25。 /* fallthru */ case'\r': crt_pos -= (crt_pos % CRT_COLS); break; case'\t': // tab 转换为五个 ' ' cons_putc(' '); cons_putc(' '); cons_putc(' '); cons_putc(' '); cons_putc(' '); break; default: crt_buf[crt_pos++] = c; /* write the character */ break; }
// What is the purpose of this? // CRT_SIZE:是CRT_COLS和CRT_ROWS的乘积,即2000=80*25,是不翻页时一页屏幕最大能容纳的字数。 // 当前屏幕写满了, if (crt_pos >= CRT_SIZE) { int i; /* * 函数:memmove(): memmove(void *dst, const void *src, size_t n). * 意为将从src指向位置起的n字节数据送到dst指向位置,可以在两个区域重叠时复制。 * */ // 所有数据向前挪动一行,最上面一行数据丢失 memmove(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) * sizeof(uint16_t)); // 清空最后一行,用空格填充 for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++) crt_buf[i] = 0x0700 | ' '; crt_pos -= CRT_COLS; } // 写光标位置 /* move that little blinky thing */ outb(addr_6845, 14); outb(addr_6845 + 1, crt_pos >> 8); outb(addr_6845, 15); outb(addr_6845 + 1, crt_pos); }
problem 2
从console.c
解释以下内容:
1 2 3 4 5 6 7
1 if (crt_pos >= CRT_SIZE) { 2 int i; 3 memmove(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) * sizeof(uint16_t)); 4 for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++) 5 crt_buf[i] = 0x0700 | ' '; 6 crt_pos -= CRT_COLS; 7 }
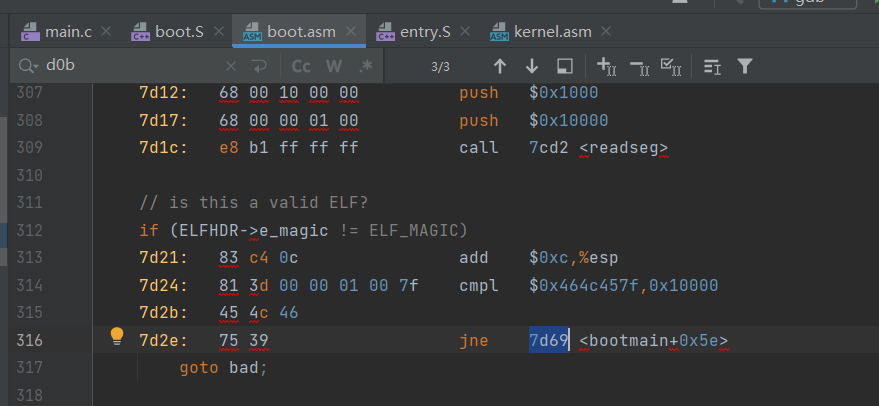
见上
problem 3
For the following questions you might wish to consult the notes for Lecture 2. These notes cover GCC’s calling convention on the x86.
Trace the execution of the following code step-by-step:
1 2
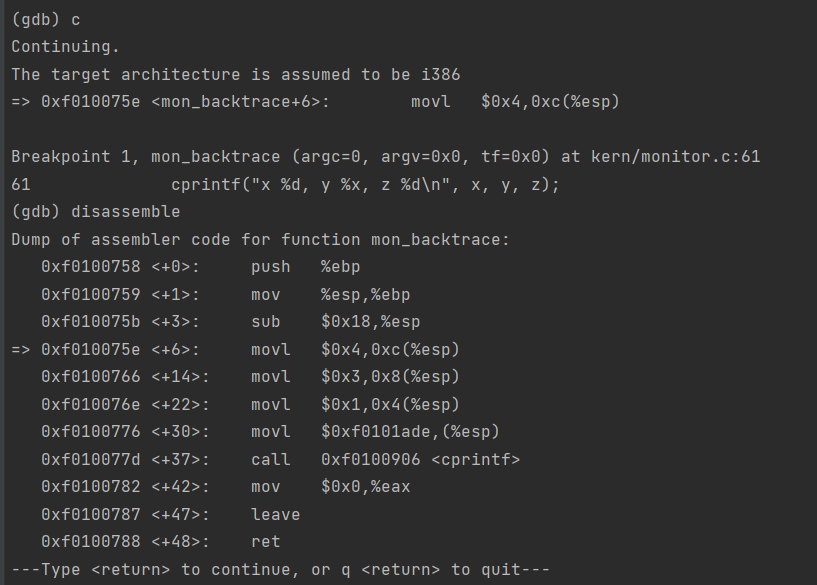
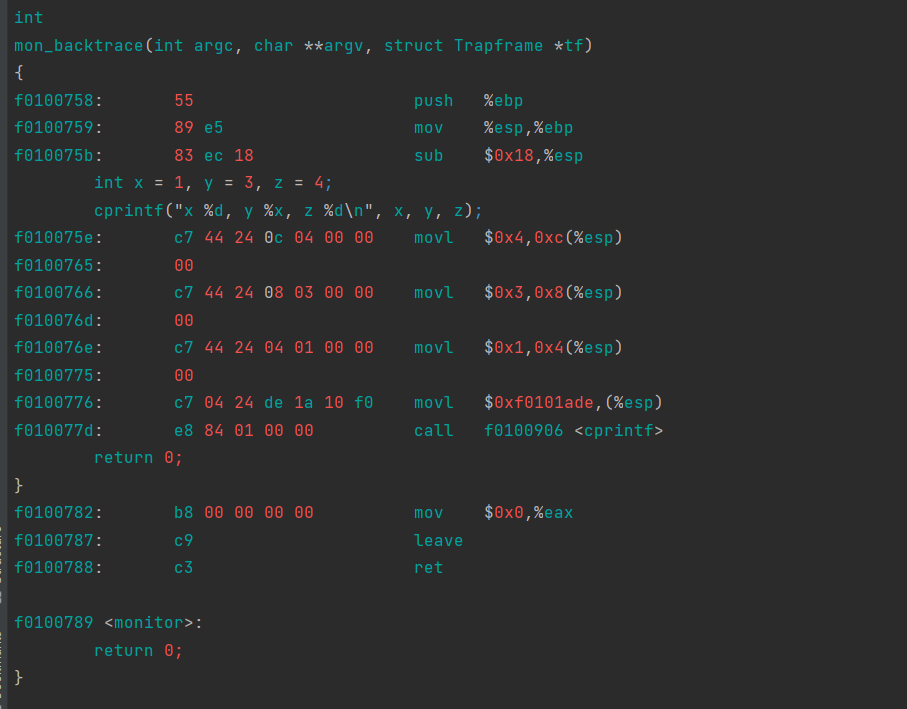
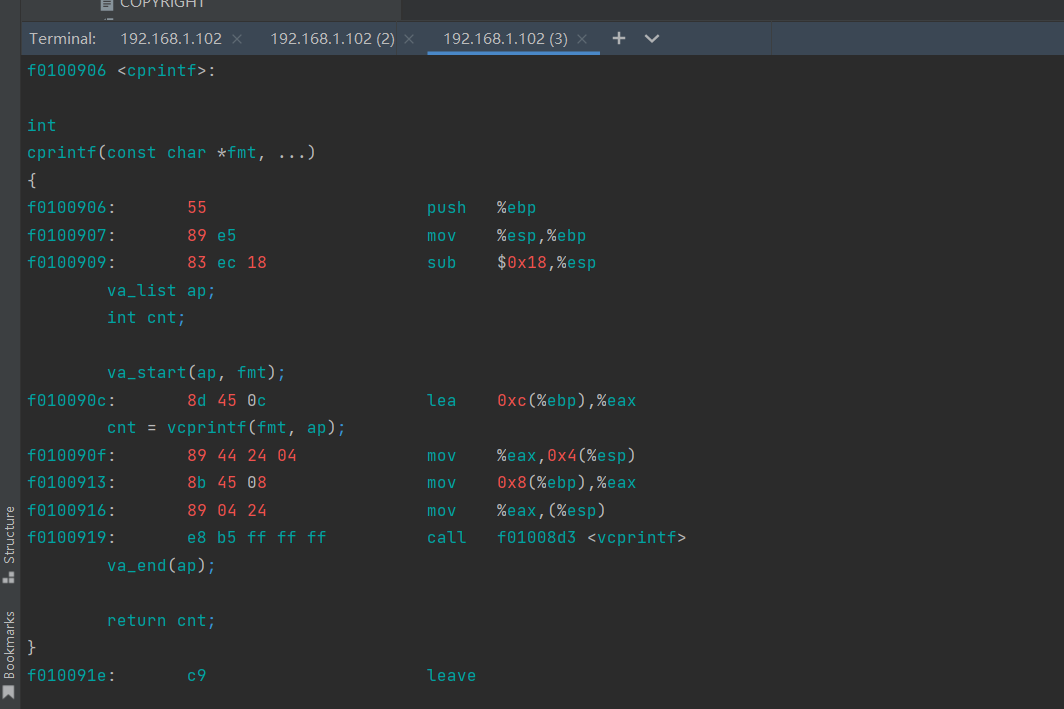
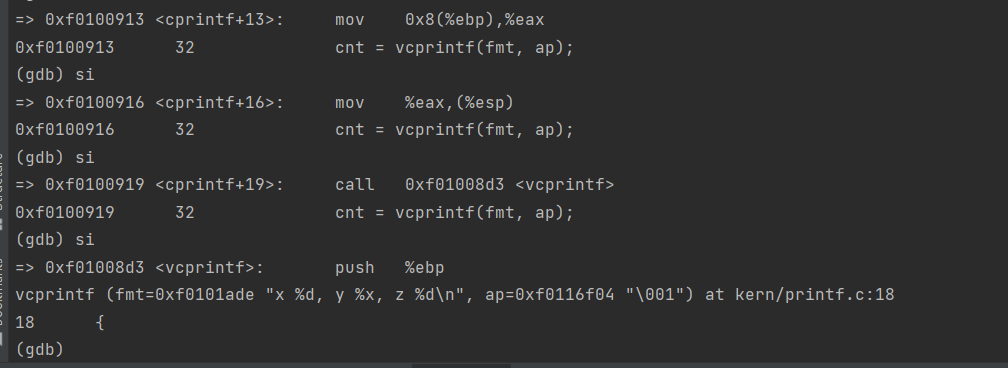
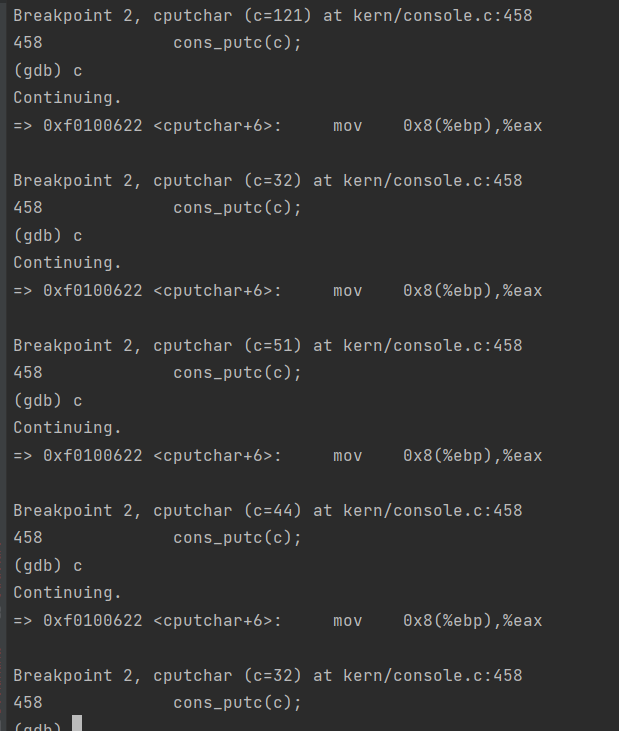
int x = 1, y = 3, z = 4; cprintf("x %d, y %x, z %d\n", x, y, z);
In the call to cprintf(), to what does fmt point? To what does ap point?
List (in order of execution) each call to cons_putc, va_arg, and vcprintf. For cons_putc, list its argument as well. For va_arg, list what ap points to before and after the call. For vcprintf list the values of its two arguments.
对于以下问题,您可能希望查阅第 2 讲的注释。这些注释涵盖了 GCC 在 x86 上的调用约定。
逐步跟踪以下代码的执行:
1 2
int x = 1, y = 3, z = 4; cprintf("x %d, y %x, z %d\n", x, y, z);
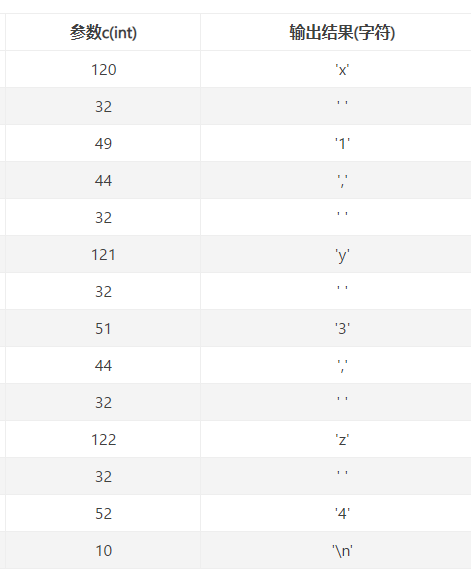
unsignedint i = 0x00646c72; cprintf("H%x Wo%s", 57616, &i);
What is the output? Explain how this output is arrived at in the step-by-step manner of the previous exercise.
The output depends on that fact that the x86 is little-endian. If the x86 were instead big-endian what would you set i to in order to yield the same output? Would you need to change 57616 to a different value?
unsignedint i = 0x726c6400; cprintf("H%x Wo%s", 57616, &i);
problem 5
In the following code, what is going to be printed after ‘ y= ‘ ? (note: the answer is not a specific value.) Why does this happen?
1
cprintf("x=%d y=%d", 3);
y的值没有给定,所以输出一个不确定的值
problem 6
Let’s say that GCC changed its calling convention so that it pushed arguments on the stack in declaration order, so that the last argument is pushed last. How would you have to change cprintf or its interface so that it would still be possible to pass it a variable number of arguments?
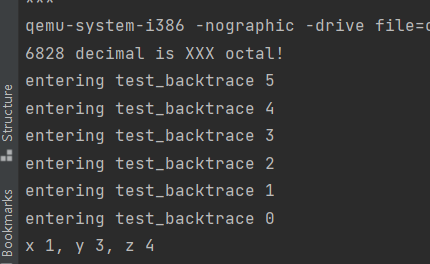
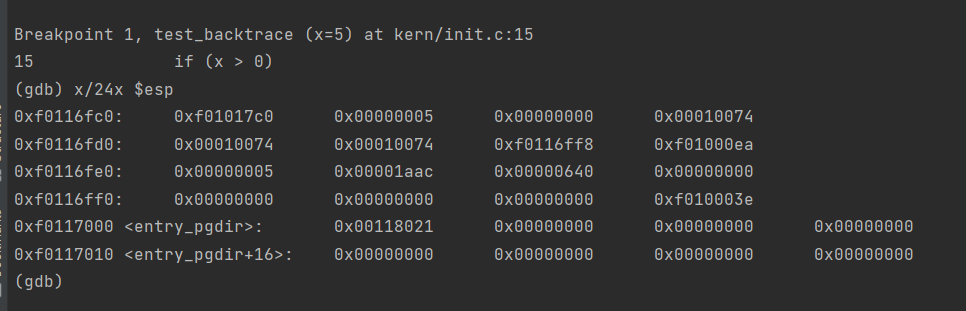
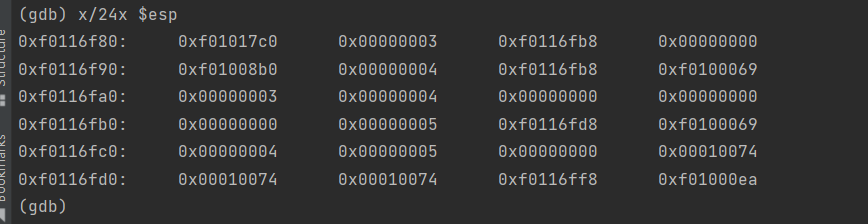
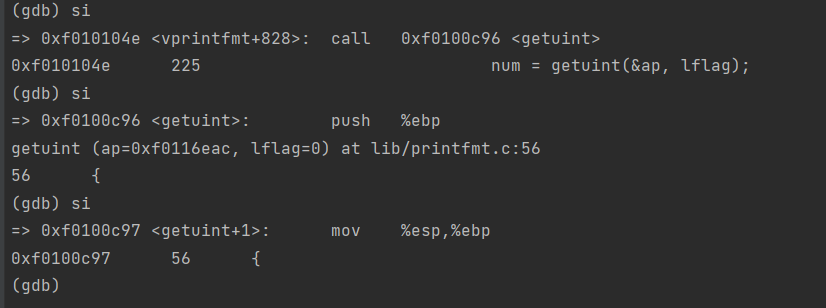
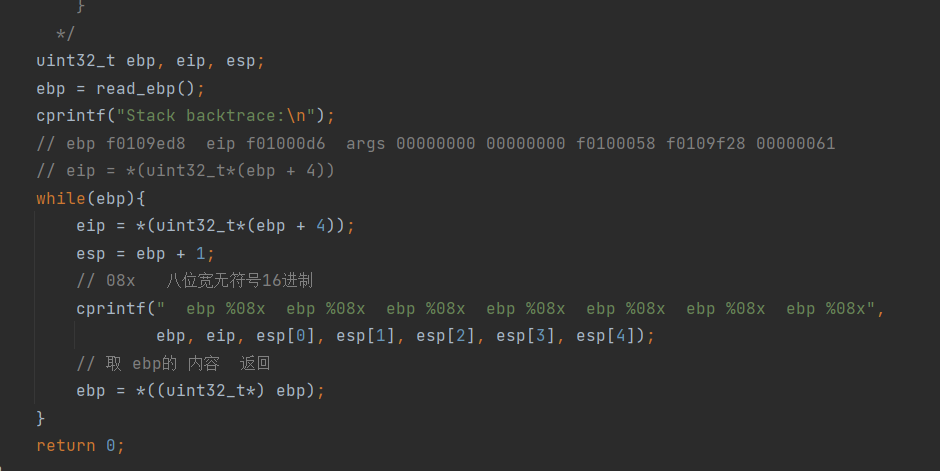
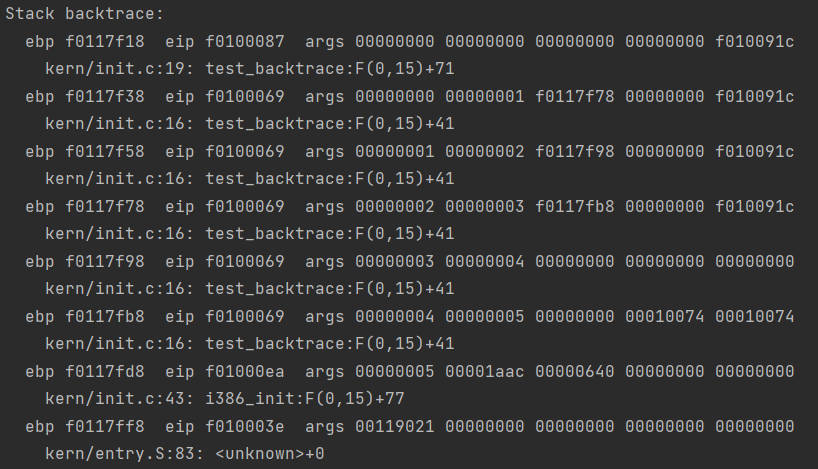
Each line gives the file name and line within that file of the stack frame’s eip, followed by the name of the function and the offset of the eip from the first instruction of the function (e.g., monitor+106 means the return eip is 106 bytes past the beginning of monitor).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
/* Include debugging information in kernel memory */ .stab : { PROVIDE(__STAB_BEGIN__ = .); *(.stab); PROVIDE(__STAB_END__ = .); BYTE(0) /* Force the linker to allocate space for this section */ }
.stabstr : { PROVIDE(__STABSTR_BEGIN__ = .); *(.stabstr); PROVIDE(__STABSTR_END__ = .); BYTE(0) /* Force the linker to allocate space for this section */ }
$tar xjf gmp-5.0.2.tar.bz2 $cd gmp-5.0.2 $./configure --prefix=/usr/local# 可能的错误:No usable m4 in $PATH or /usr/5bin (see config.log for reasons). $make $sudo make install $cd ..
qga/commands-posix.c: In function ‘dev_major_minor’: qga/commands-posix.c:633:13: error: In the GNU C Library, "major" is defined by <sys/sysmacros.h>. For historical compatibility, it is currently defined by <sys/types.h> as well, but we plan to remove this soon. To use "major", include <sys/sysmacros.h> directly. If you did not intend to use a system-defined macro "major", you should undefine it after including <sys/types.h>. [-Werror] *devmajor = major(st.st_rdev); ^~~~~~~~~~~~~~~~~~~~~~~~~~






%E5%8E%9F%E7%90%86.png)